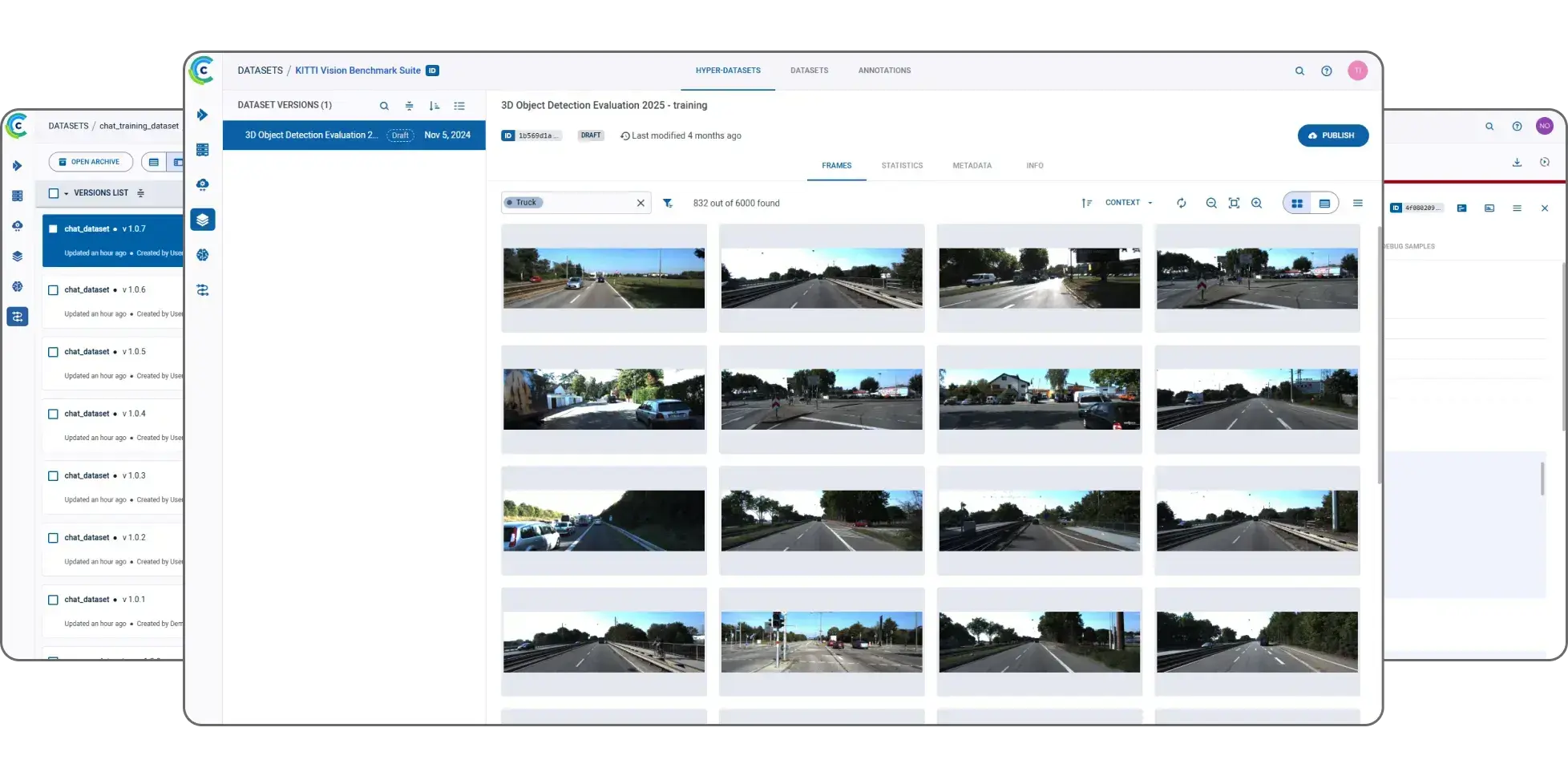
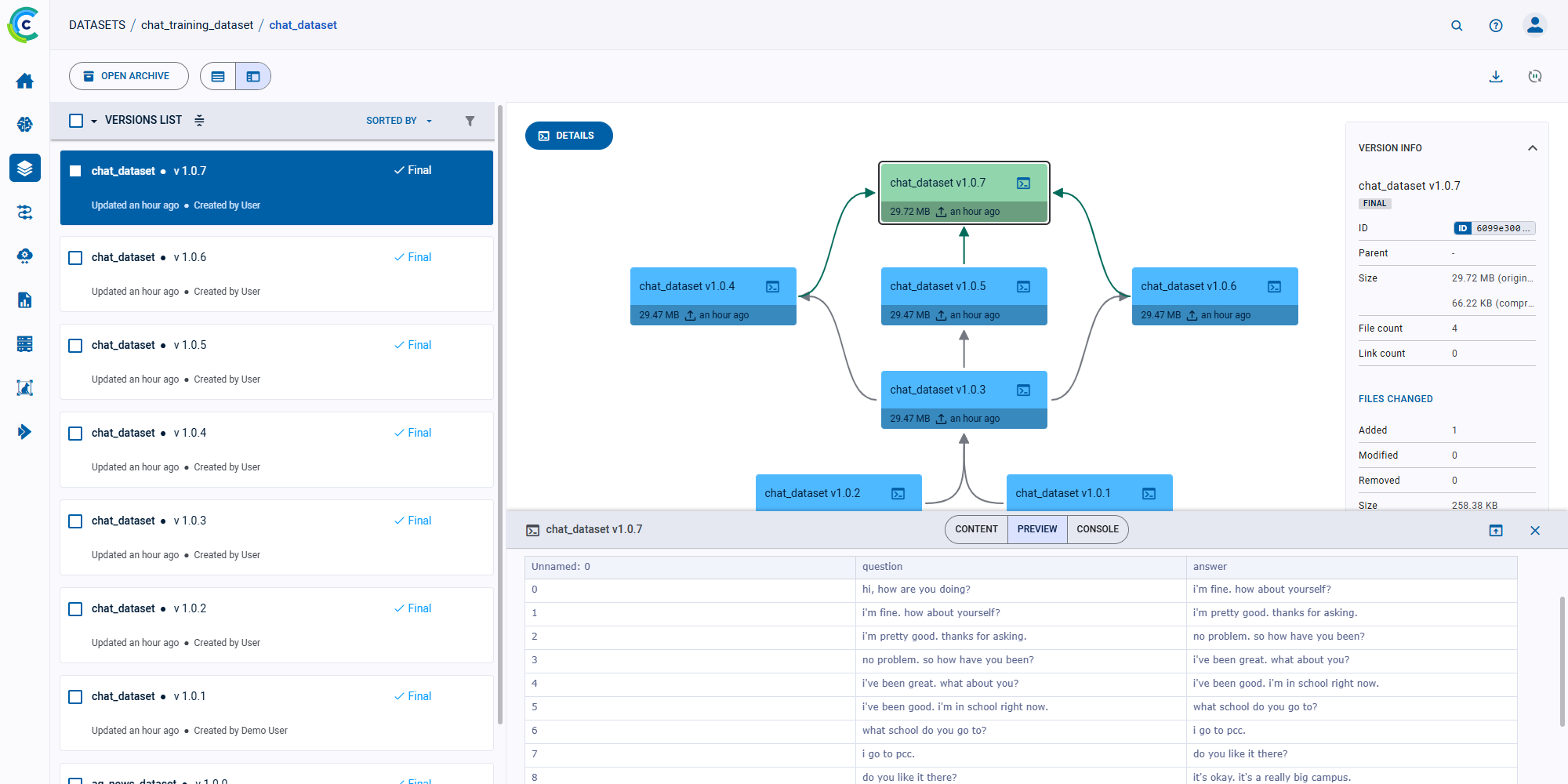
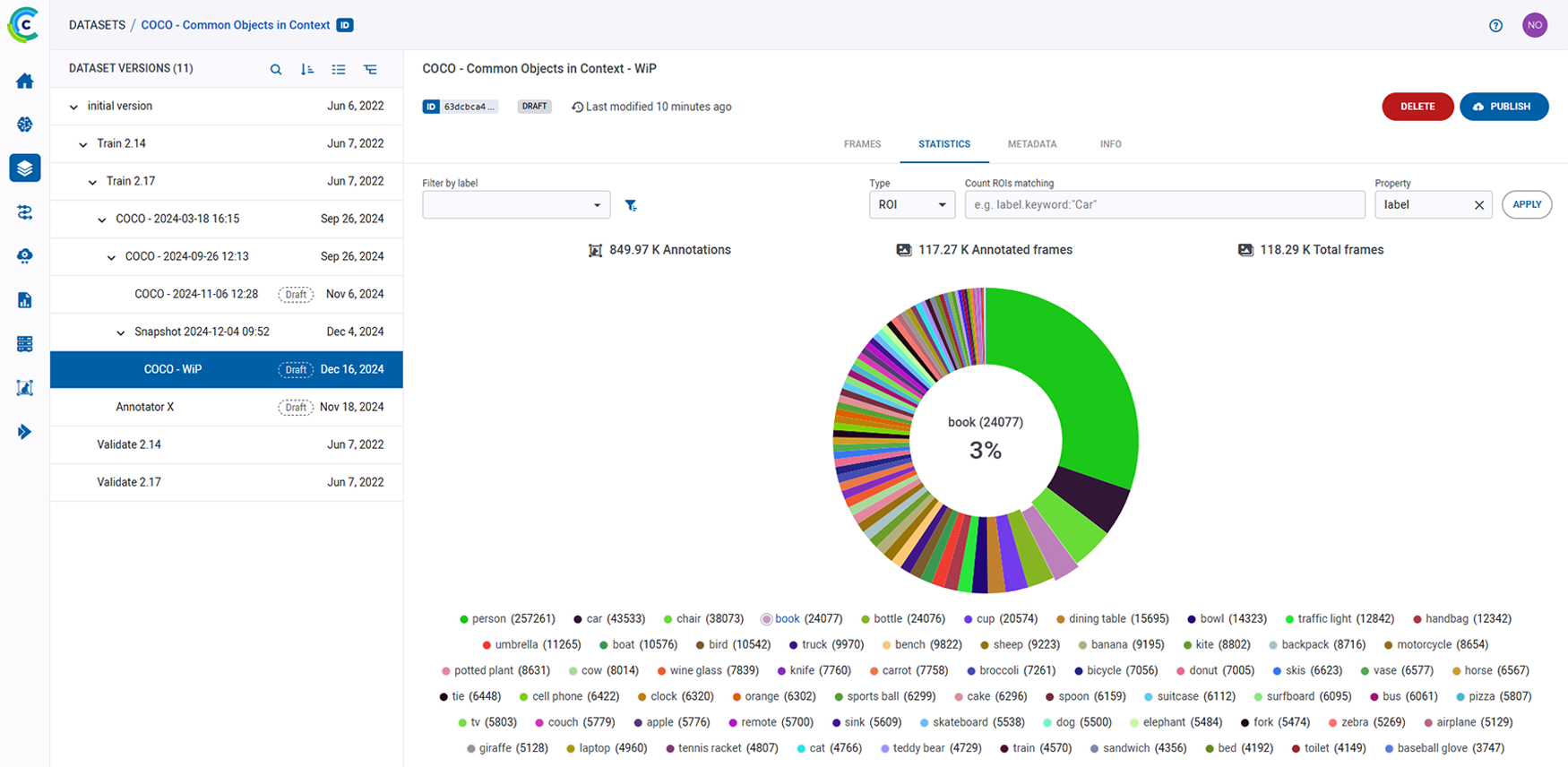
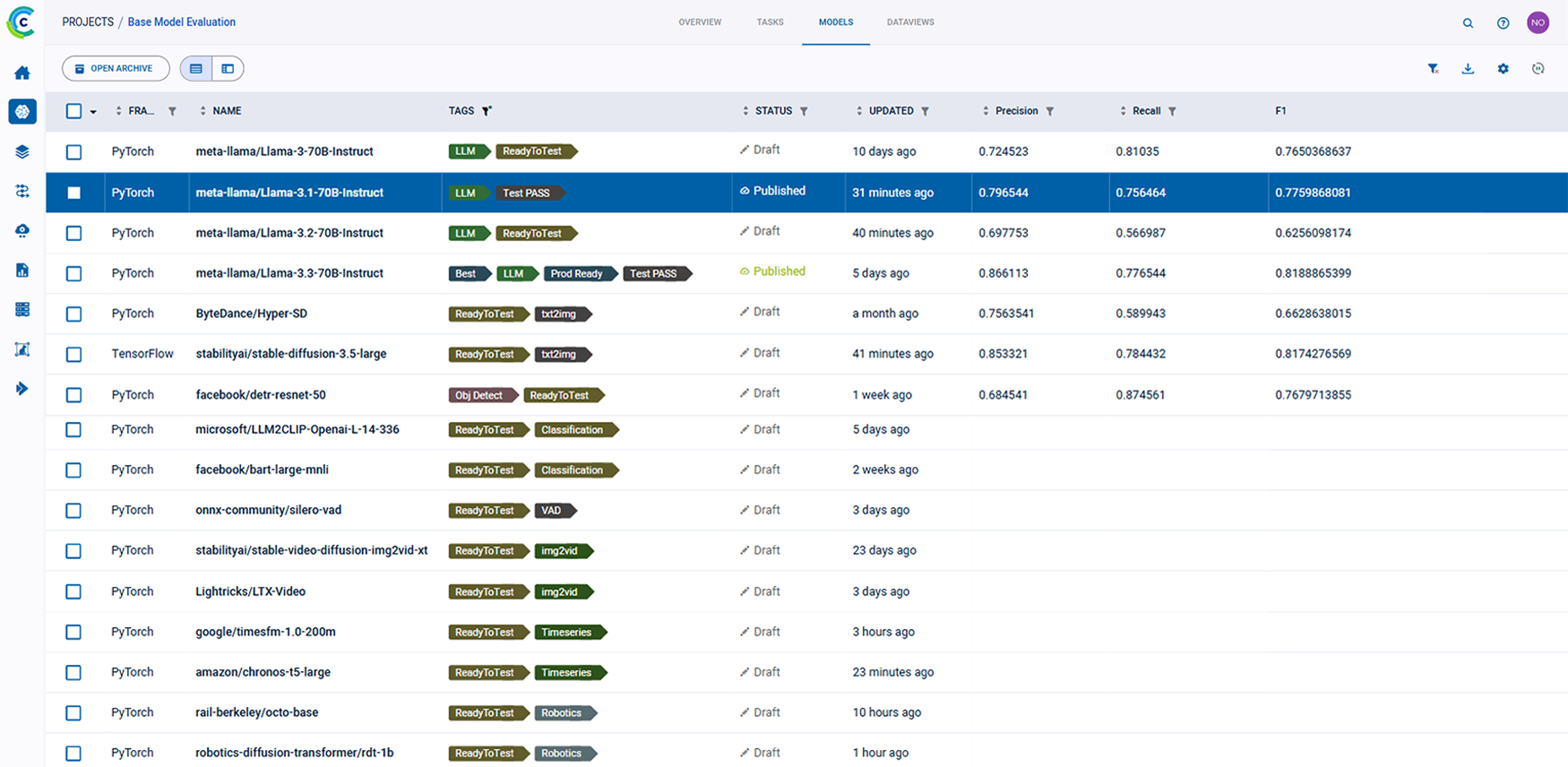
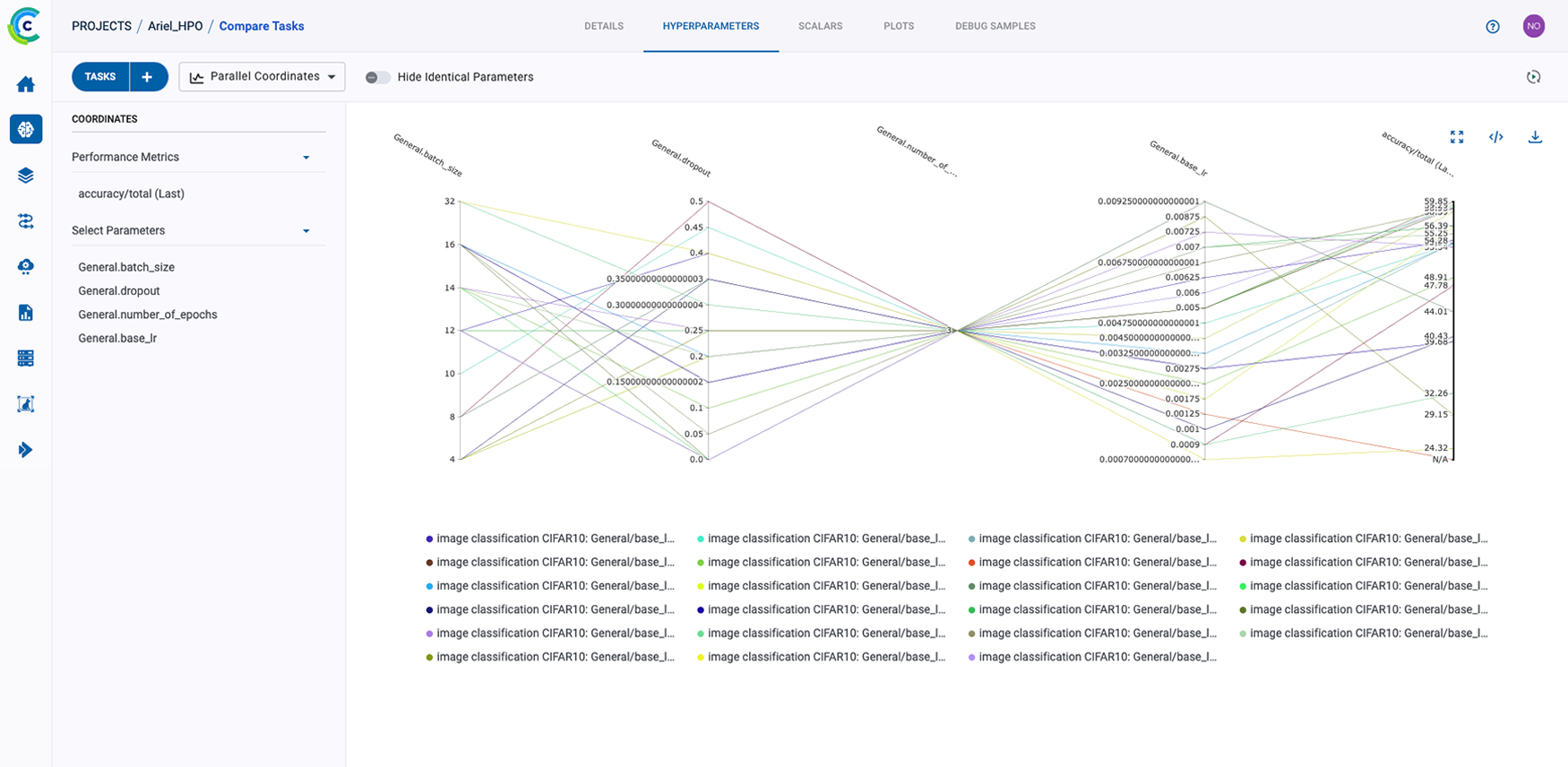
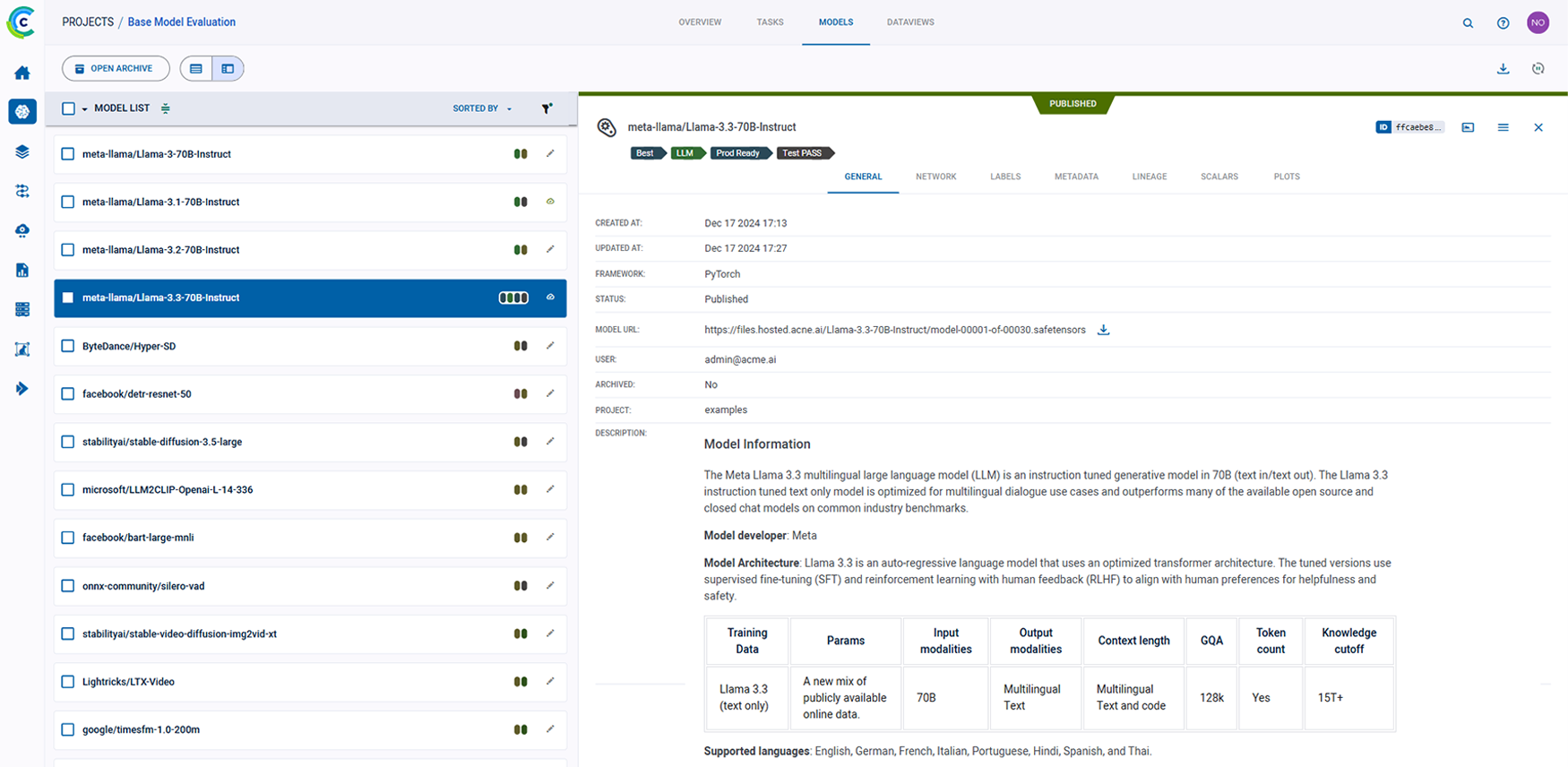
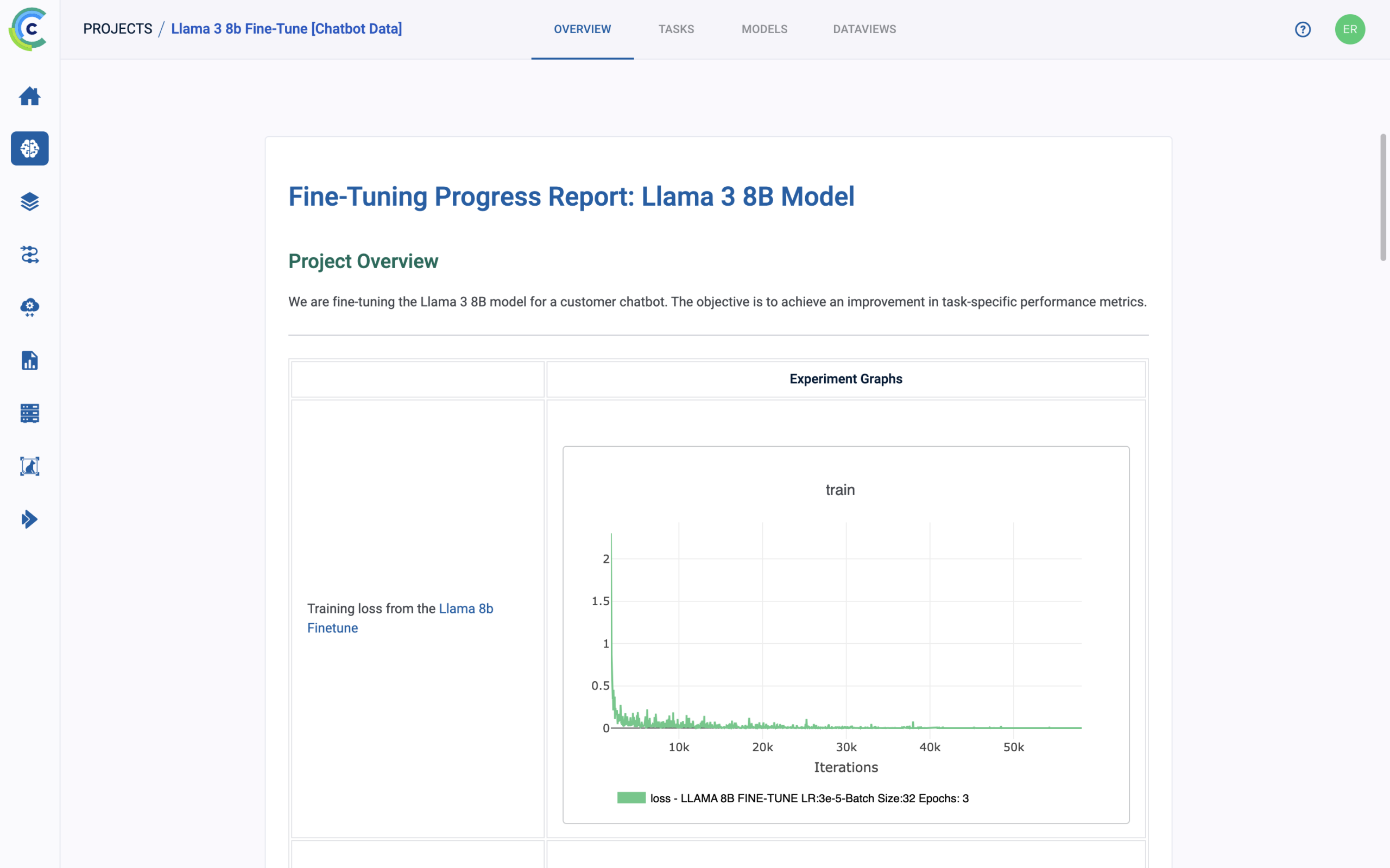
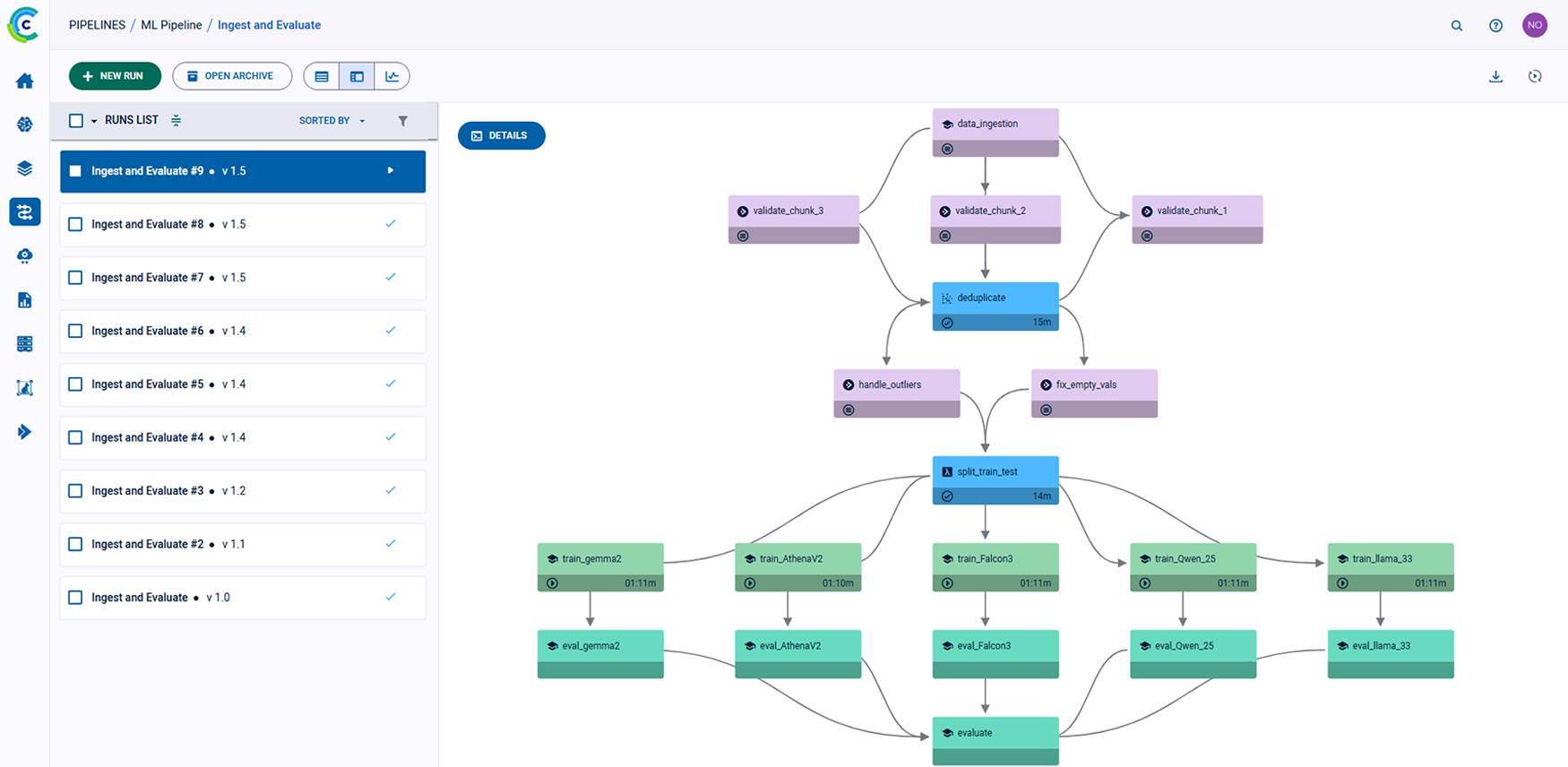
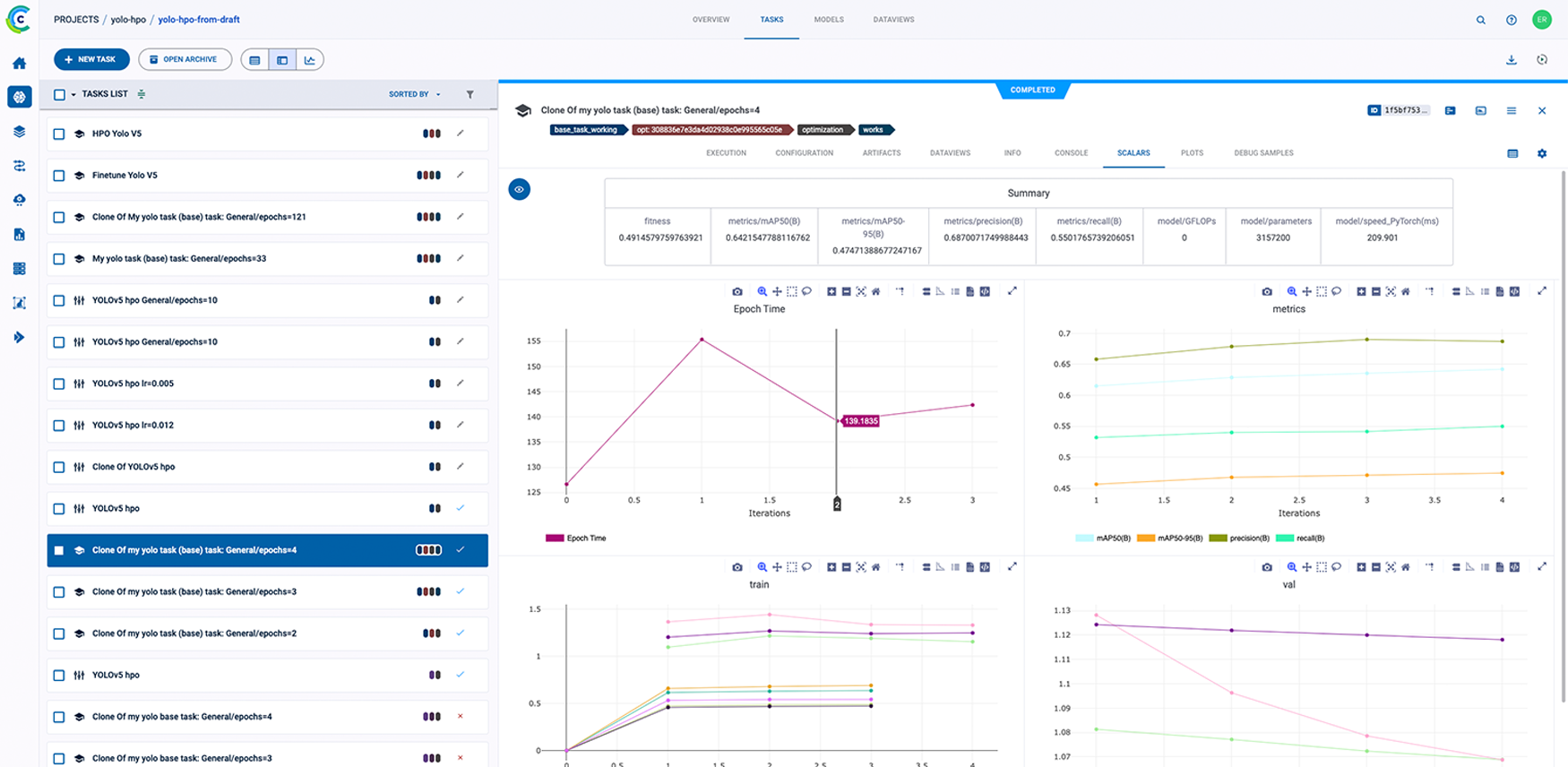
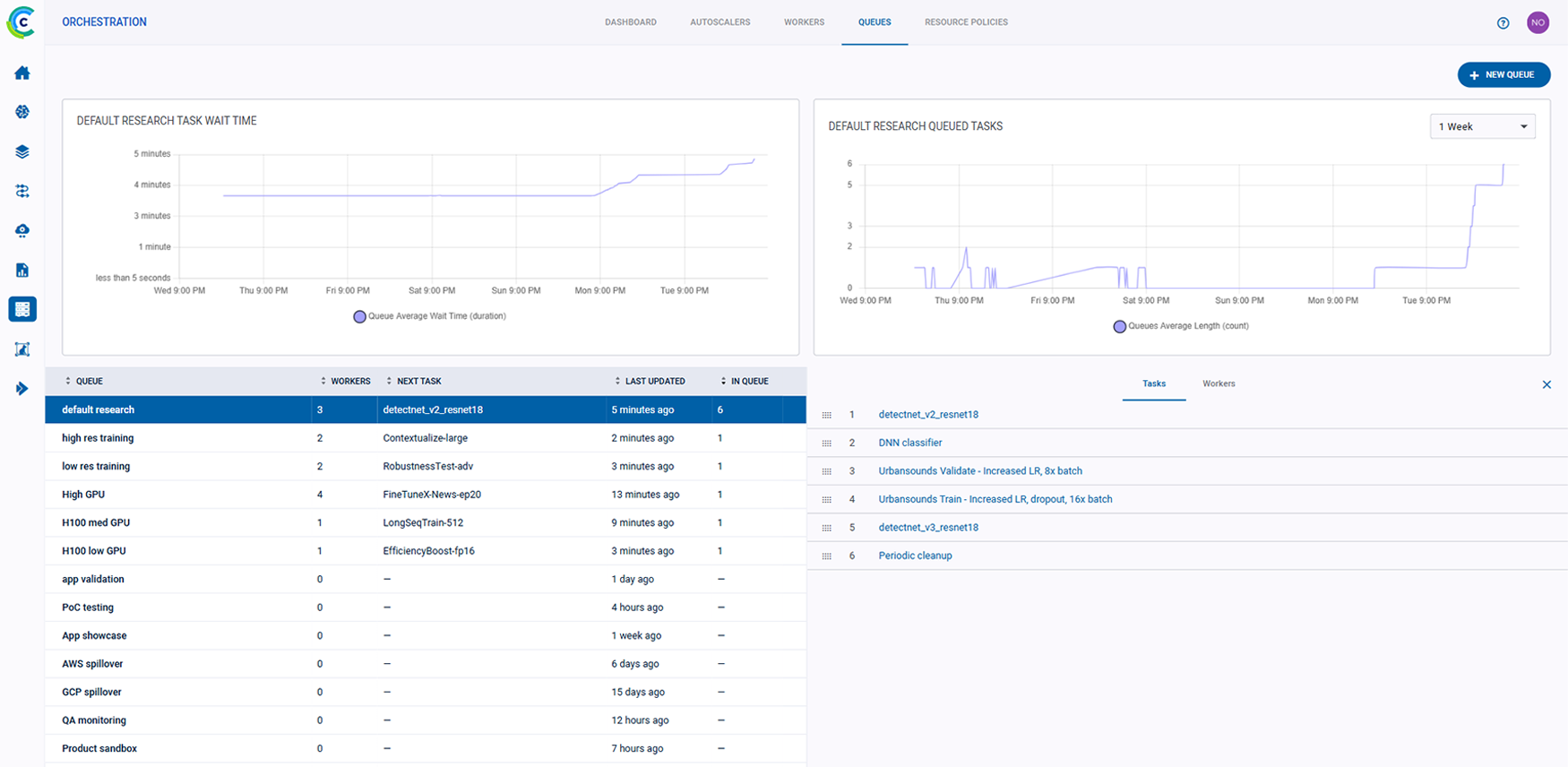
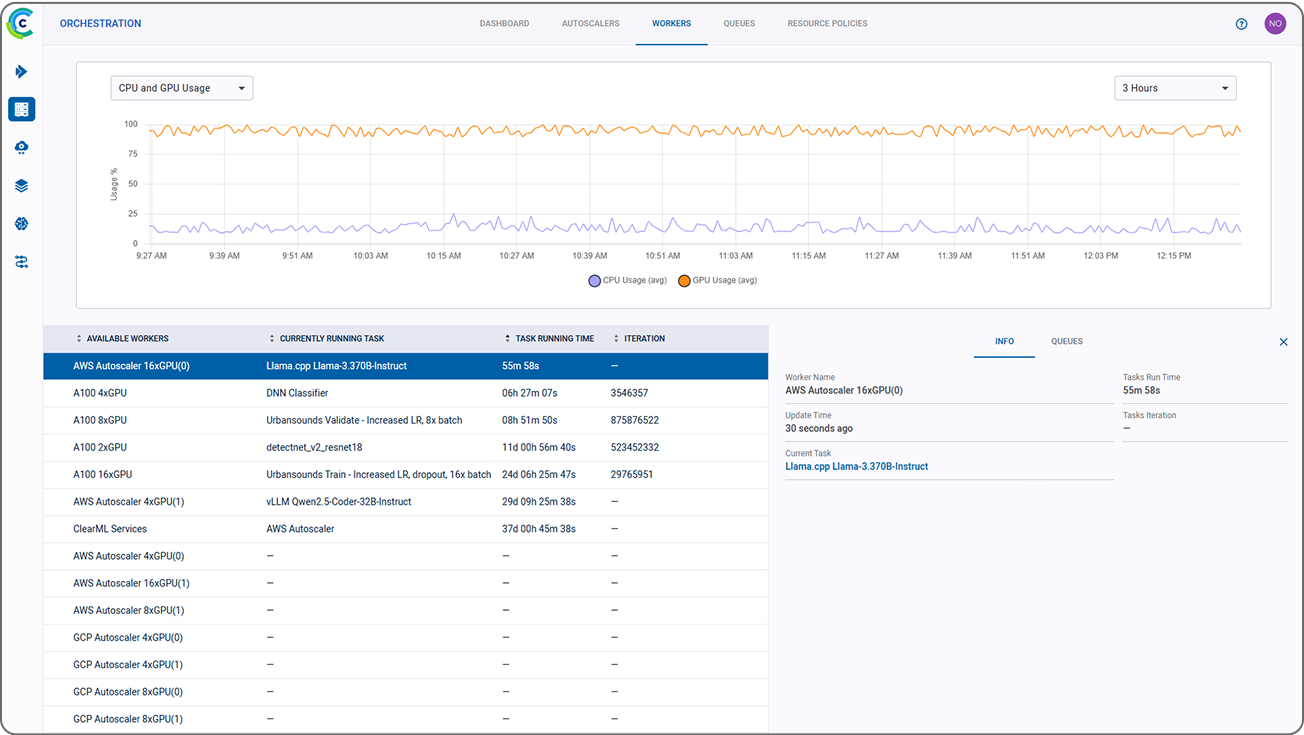
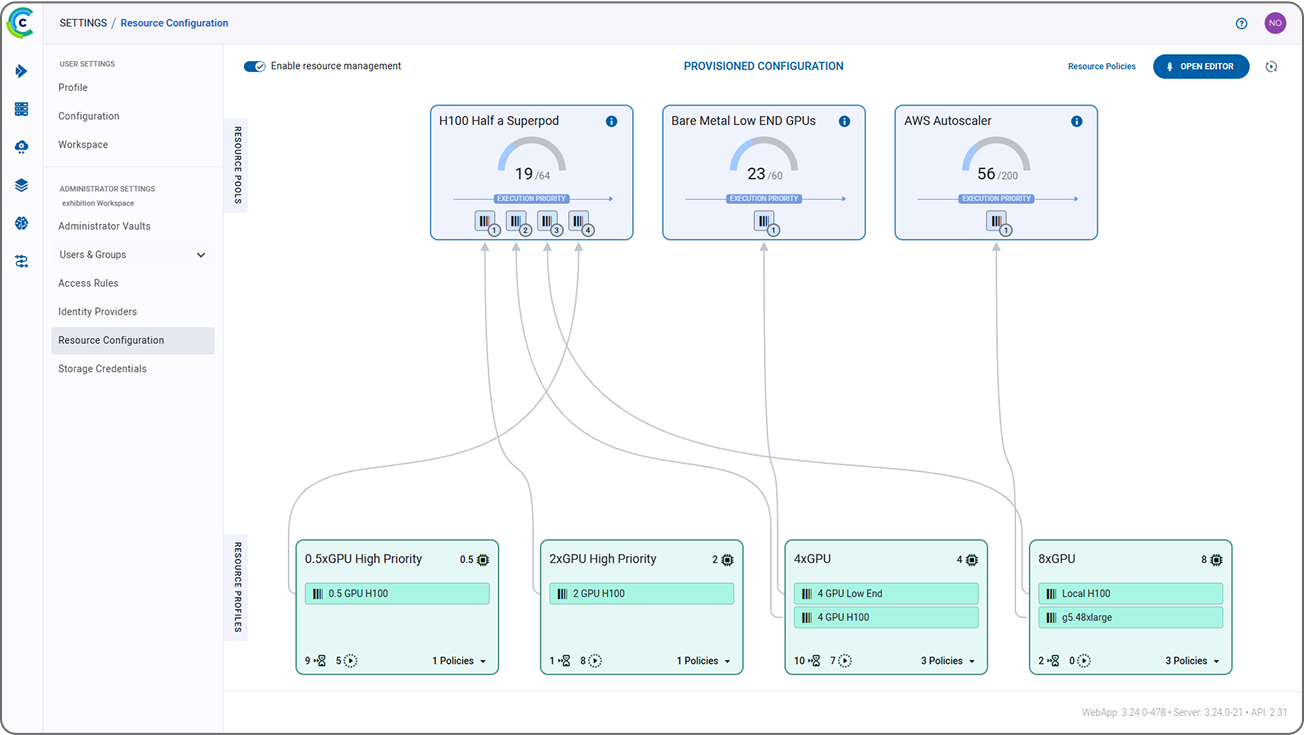
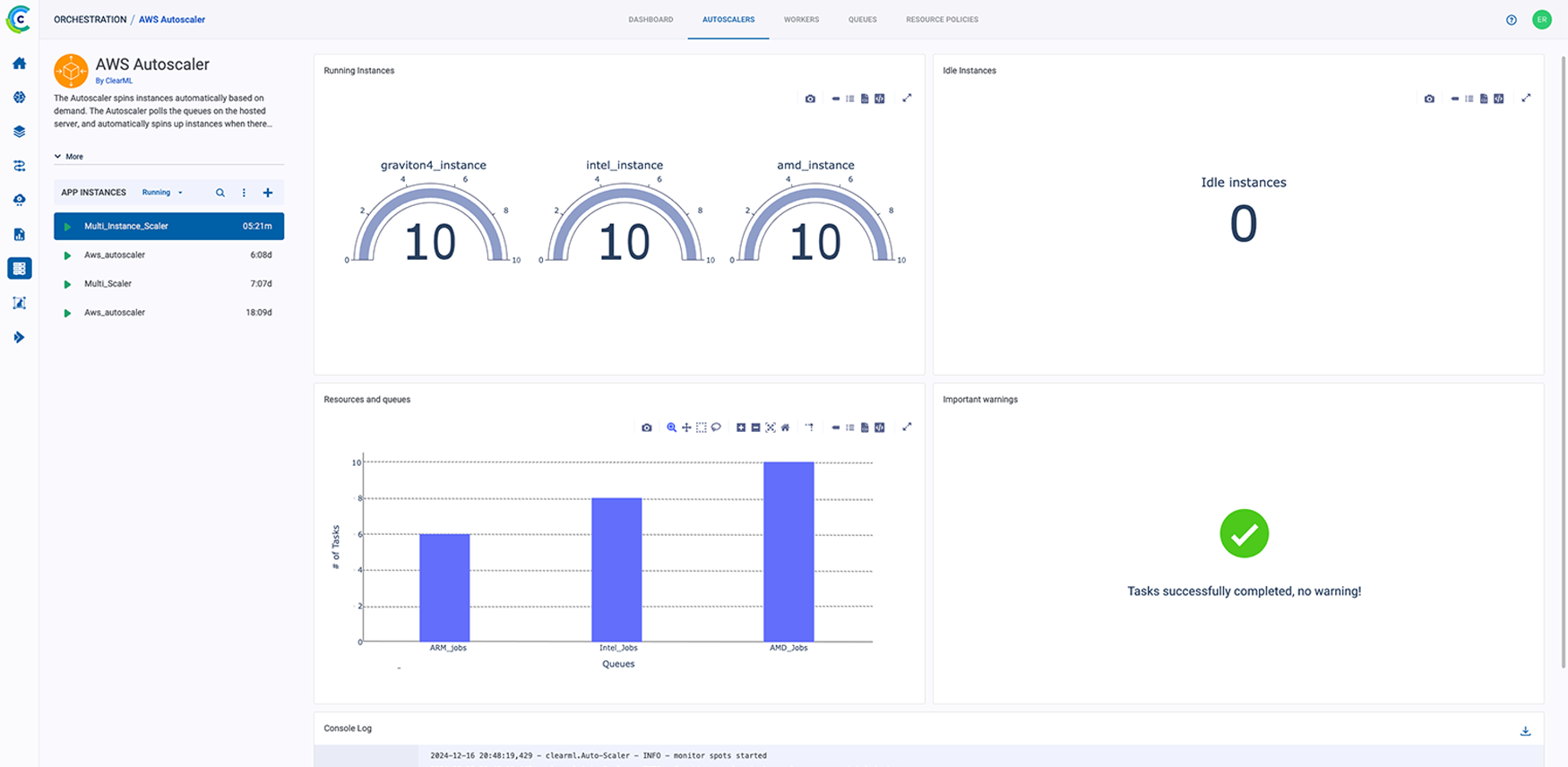
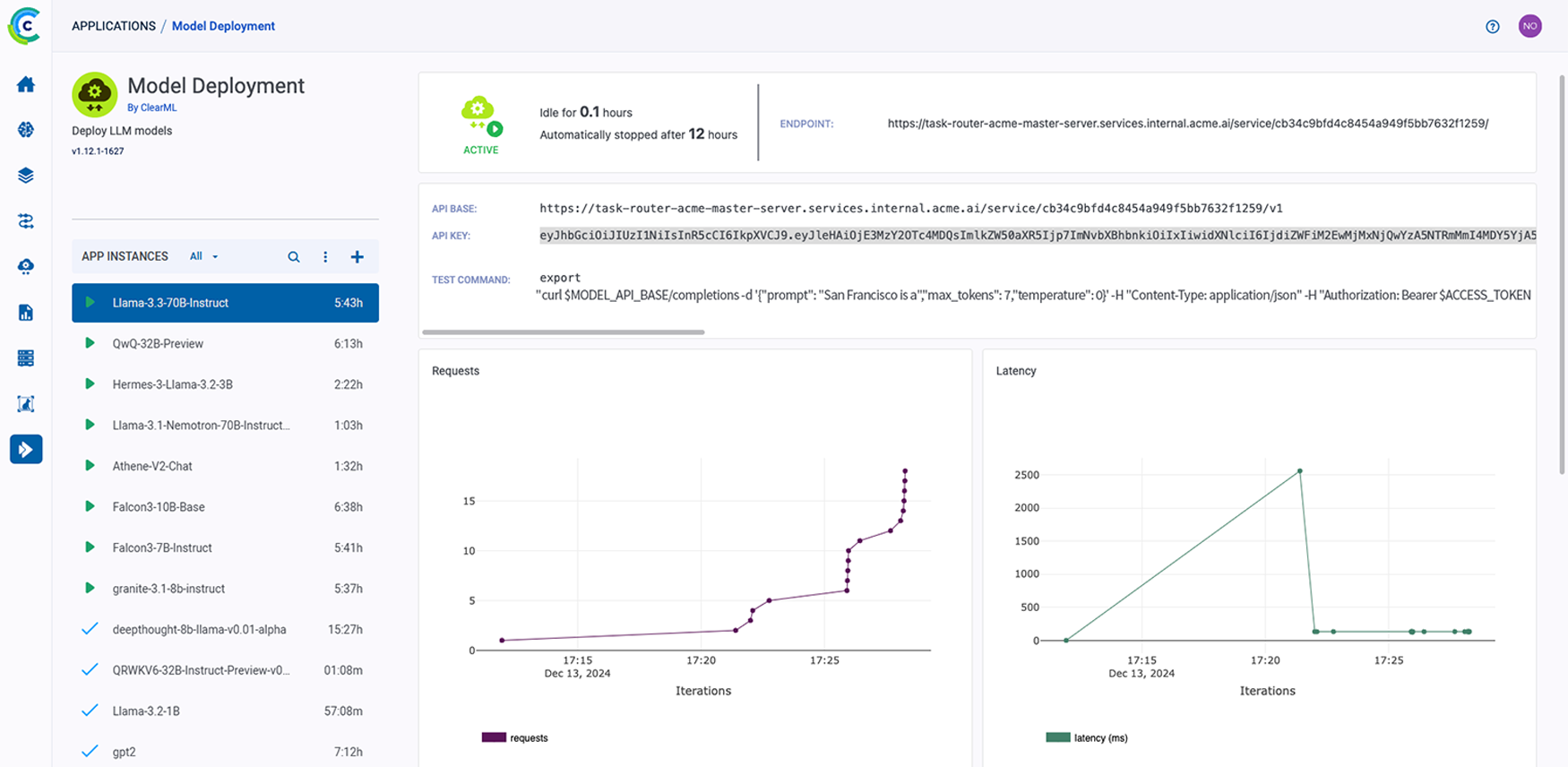
ClearML 的 AI 开发中心为您的 AI/ML 工作流程提供了基础构建模块。它简化了数据准备、编目和流程设计,实现了无缝协作和可扩展性。凭借诸如用于自动化数据跟踪和版本控制的数据运营 (DataOps)、用于动态管理非结构化数据的超级数据集 (Hyper-Datasets) 以及用于跟踪和重现 ML 实验每一步的实验管理器 (Experiment Manager) 等功能,ClearML 确保您的工作流程高效且可追溯。从集中的模型库 (Modelstore) 管理到连接和自动化任务的逻辑驱动型管道 (Pipelines),ClearML 使您的团队能够简化运营、专注于创新,并更快、更智能地构建 AI 解决方案。功能包括