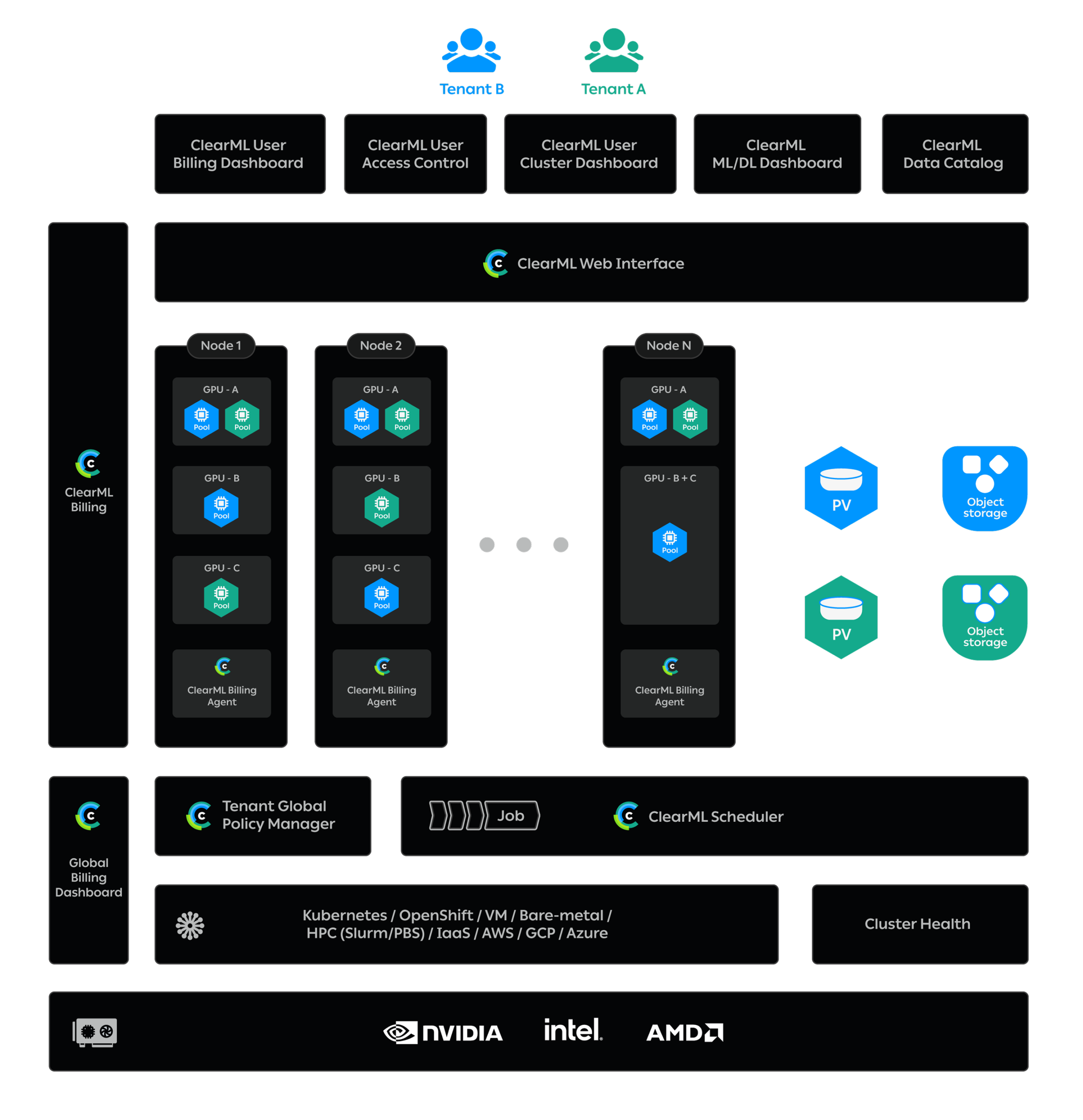
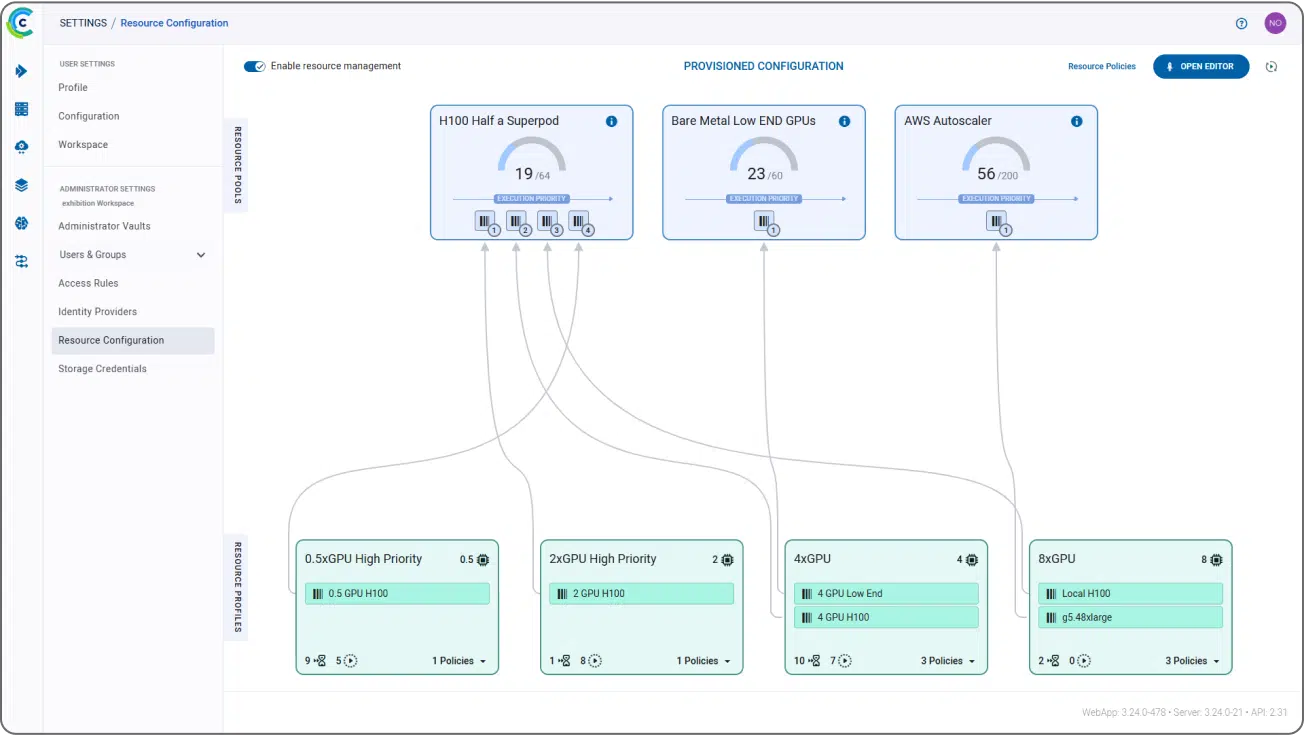
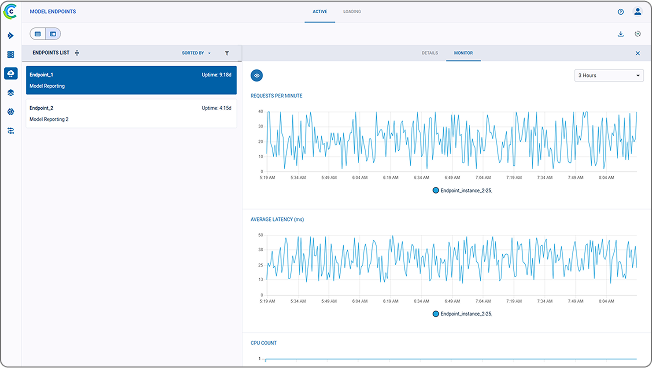
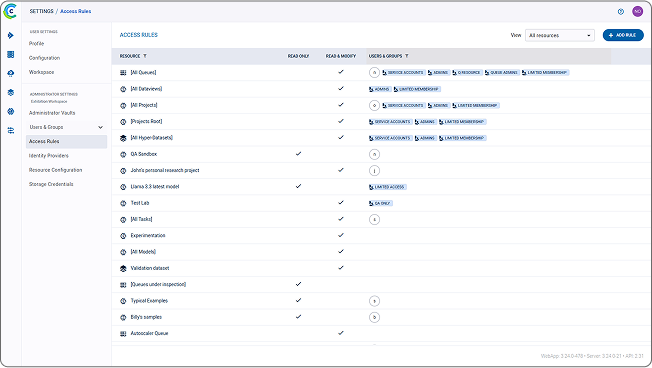
Genesis Cloud 长期以来一直能够为我们的客户提供安全的多租户云计算,但我们觉得缺少的一点是,我们的客户可以在 Genesis Cloud 提供的实例内部进一步对其工作负载进行分区和编排。通过将 ClearML 集成到我们的云平台,我们使客户能够(根据自己的选择!)按照他们认为合适的方式对其工作负载进行分区和编排,并向客户开放一系列工具,包括 Slurm 等。这为我们的客户提供了我们提供的资源的更大灵活性。总的来说,它使我们的客户能够减少集群空闲时间,保持集群高利用率,从而实现更高的性价比。
Norman BehrendGenesis Cloud 首席商务官