GPU即服务 - 企业版
通过共享计算以及无摩擦的AI开发和部署,实现跨部门和业务单元的更高计算基础设施利用率
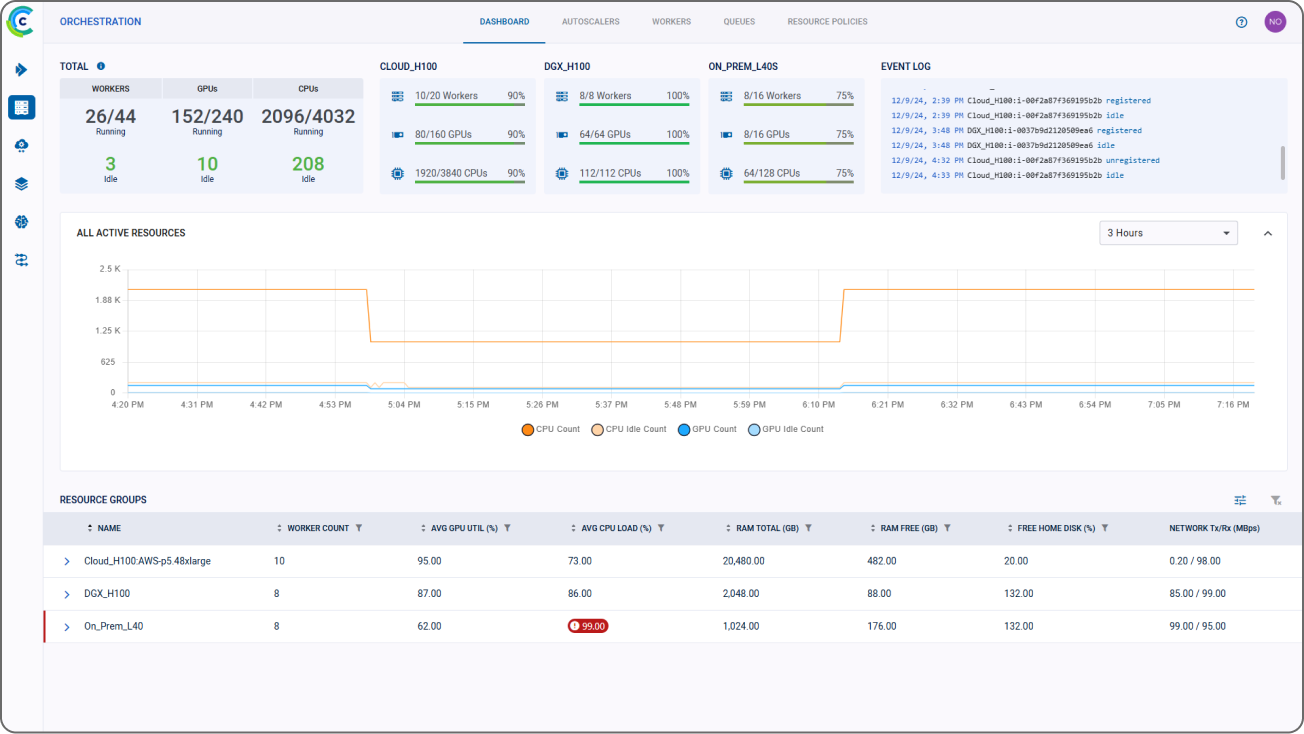
在每个业务部门都需要更多GPU来应对AI和HPC工作负载需求的时代,ClearML通过其全新的GPU即服务解决方案,为企业提供了一个强大的数据中心级解决方案,用于优化计算基础设施。该方案提供了安全的多租户、细粒度的资源分配管理和策略、动态分块GPU、治理以及实时的使用情况报告。
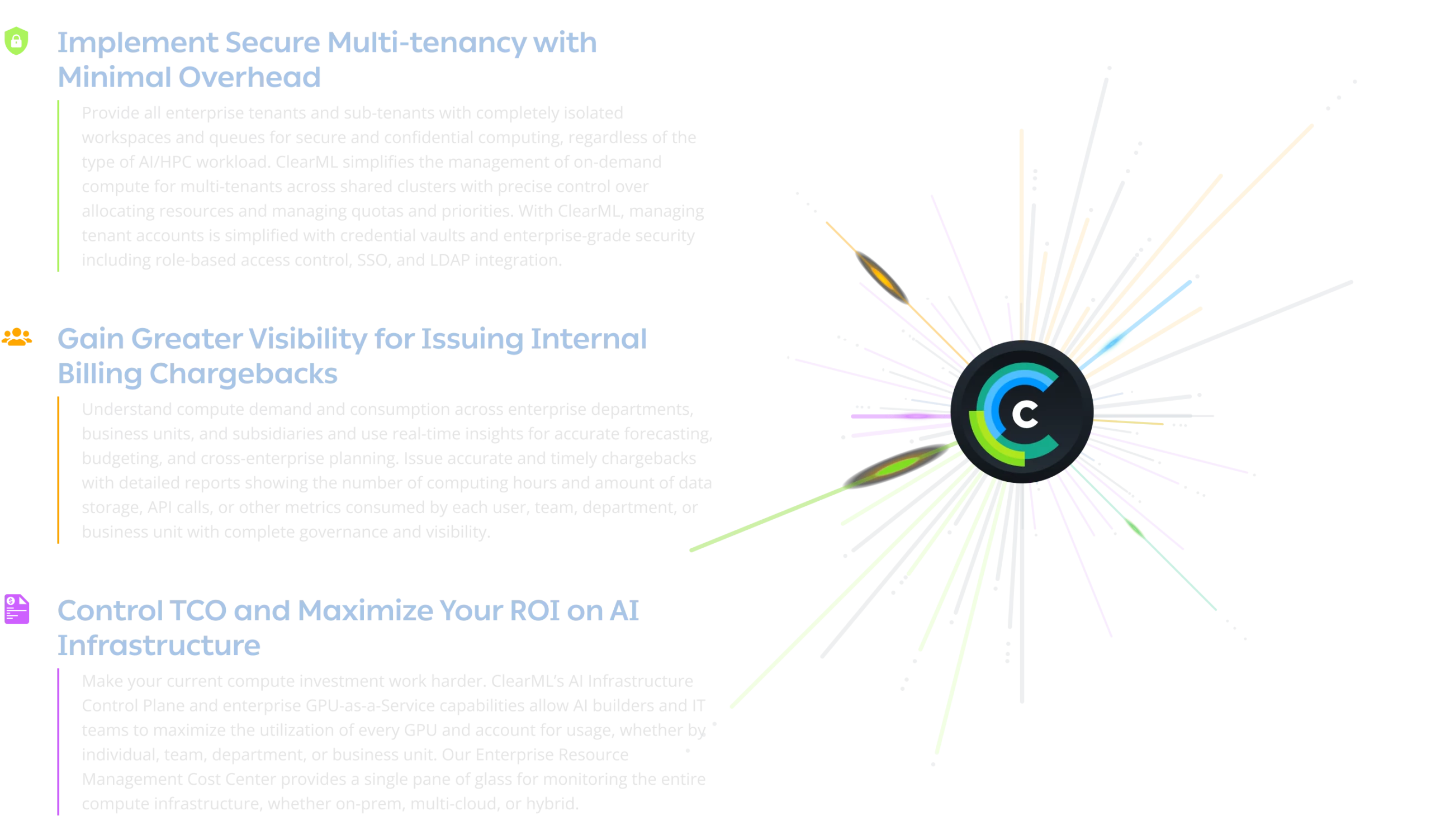
借助ClearML,AI基础设施负责人可以通过密切监控和控制资源使用情况,确保最昂贵的计算集群始终得到充分利用,并能够发出准确的内部计费回溯,反映计算小时、数据存储、API调用及其他可计费指标,从而从现有硬件投资中提取更多价值。
ClearML的端到端AI平台专为最复杂、要求严苛的环境和新颖的企业用例而构建,位于您现有计算投资之上,并加速利益相关者进行GPU密集型AI开发和部署。我们的开源、端到端架构为企业提供了一种无摩擦且可扩展的方式,使其能够在共享的GPU池上无缝运行整个AI生命周期——从实验室到生产环境。
通过易于管理的多租户功能,让多个团队访问相同的基础设施并运行安全、并行的AI/HPC工作负载,从而最大限度地利用您的计算资源。通过实时跟踪计算消耗、数据存储及其他指标并发出准确的费用回溯来控制成本。用于最大化计算利用率的其他功能包括GPU切片以及支持层级、优先级和配额的细粒度资源分配策略,以进一步确保计算资源不会闲置或未得到充分利用。
生产上线时间减少70%
硬件利用率提高5倍
在现有基础设施上运行10倍的AI/HPC工作负载