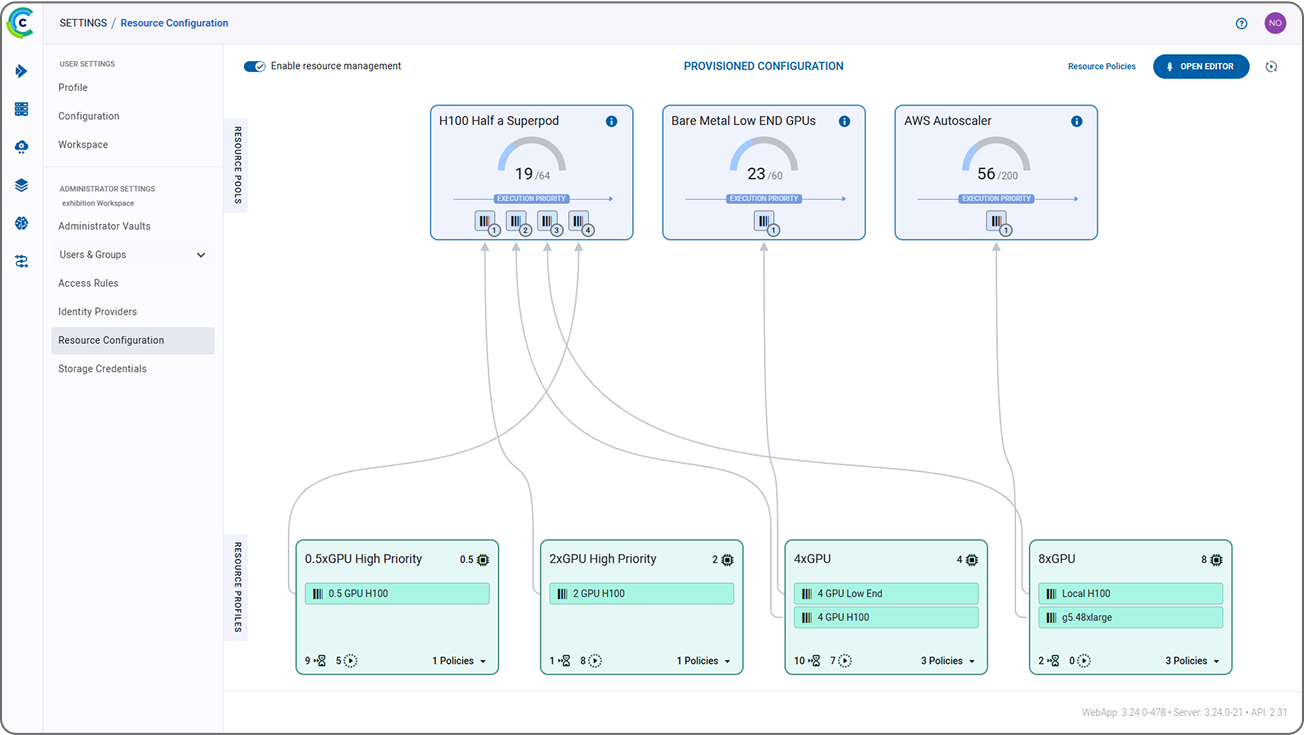
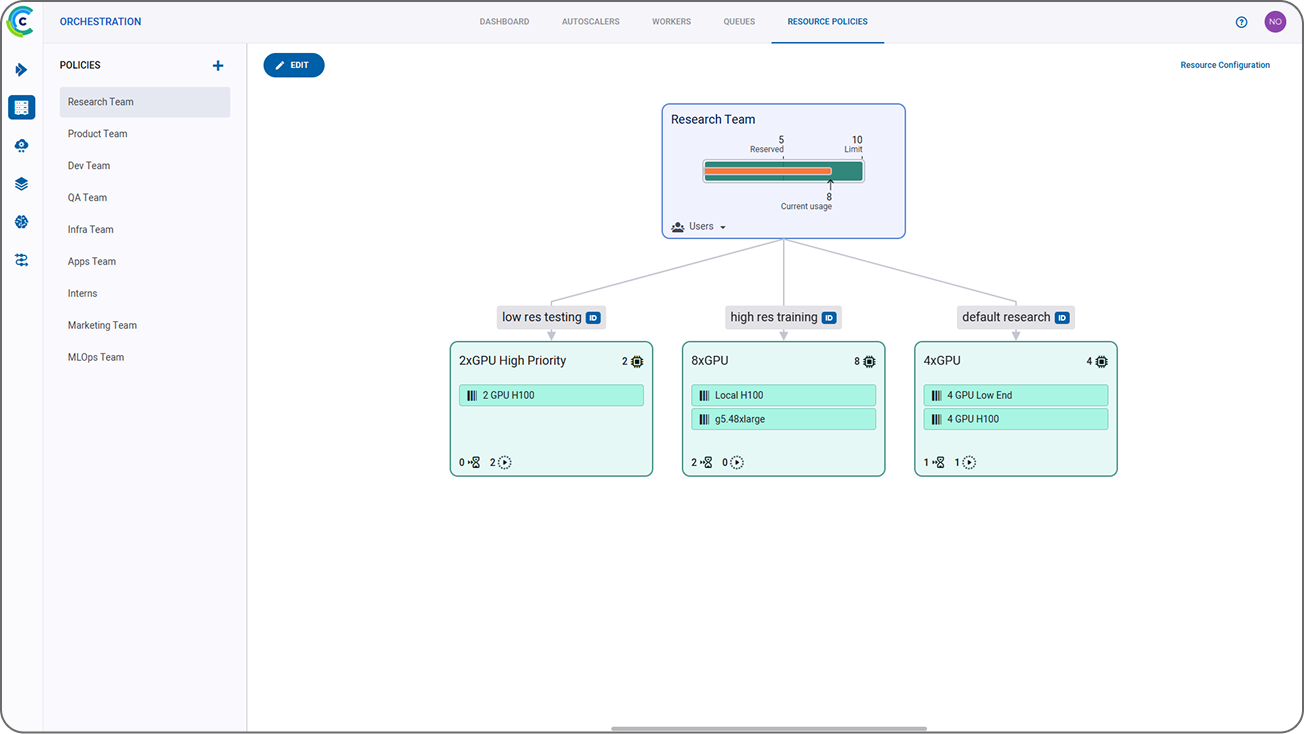
ClearML 为您的整个 AI 基础设施提供统一的视图。我们的基础设施控制平面简化了软件和硬件的集成,最大化资源利用率,从而在无需额外投资的情况下加速 AI 的采用。它通过精细的计算控制,实现了异构集群之间工作负载的优化分配,从而提高了运营效率并提供了稳定的性能——使组织能够从现有基础设施中获取最大价值。
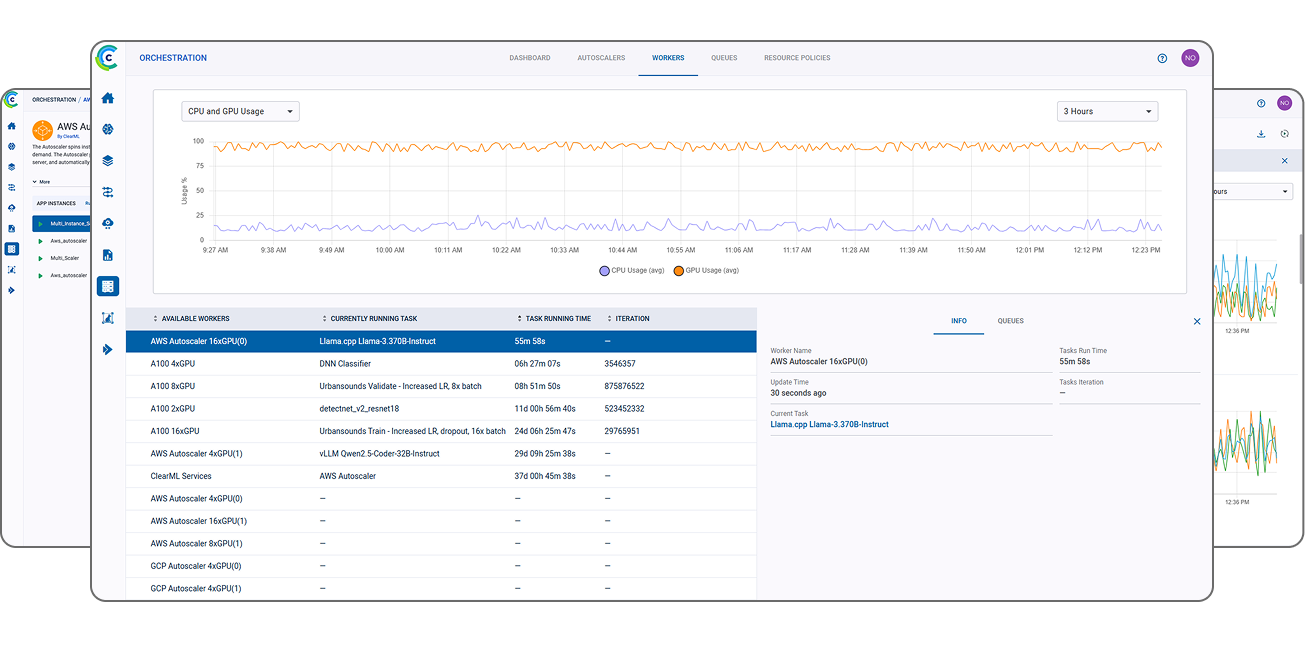
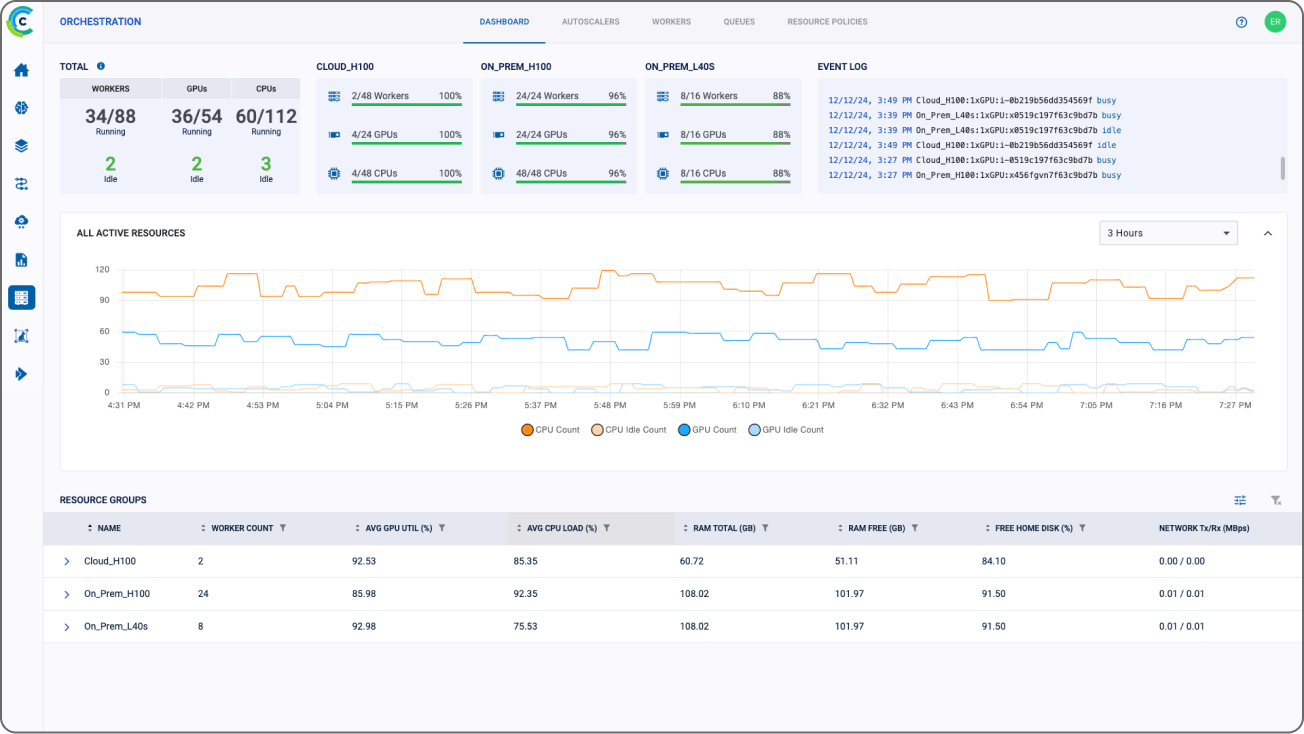
资源仪表板
监控您的基础设施的统一视图
ClearML 的集中式资源仪表板为 IT 管理员提供了集群性能和跨团队使用情况的实时可见性,从而实现更好的决策和最优的资源分配。它提供了整个基础设施的宏观视图,包含资源使用情况的详细分解以及按团队或项目设置配额和预算的能力。通过这种透明度,组织可以监控使用趋势,强制执行计算使用限制,并有效管理预算。