作者:Erez Schnaider,ClearML 技术产品营销经理
在我们之前的一篇博客文章中,我们展示了利用 AWS 上基于 Arm® Neoverse™ 的 Graviton 实例运行训练工作负载是多么容易。在这篇文章中,我们将探讨 ClearML 如何简化在基于 Arm 的实例上使用 llama.cpp 进行 LLM 推理的管理和部署,并帮助实现与 AWS 上的 x86 替代方案相比高达 4 倍的性能。
(想直接运行 llama.cpp?请查看此指南,了解如何在基于 Arm Neoverse 的 AWS Graviton 实例上设置 llama.cpp)
LLM 推理
任何关于 LLM 的博客文章都不能不快速浏览一下 LLM 推理!随着大型语言模型日益普及,运行这些模型变得越来越容易。在本地运行模型提供了关键优势:
- 确保敏感提示和数据不会被外部提供商泄露或重复使用
- 通过取消按请求收费来降低成本
- 可以使用针对特定需求定制的数据进行微调的自定义模型
像 llama.cpp、vLLM 和其他 LLM 服务引擎这样的推理框架允许用户在其自己的硬件上直接运行现成模型和微调模型。
Llama.cpp 是一个强大的推理框架,提供了最先进的开箱即用优化,包括支持不同的量化级别、优化的内存管理等。其独特之处在于它支持在 CPU 和 GPU 上进行推理,并针对基于 Arm Neoverse 的 AWS Graviton CPU 进行了特定优化。在 CPU 上运行推理可以非常经济高效,利用通常更大的 CPU RAM 来支持更大的模型。
虽然 llama.cpp 简化了本地 LLM 推理,但通常需要额外的设置才能将其用于生产环境。管理计算资源、对外暴露端点、管理性能仪表板、跟踪使用情况以及实施安全和访问控制对于一个强大且可用于生产的 LLM 服务解决方案至关重要。ClearML 解决了这些挑战,提供了一个完整透明的解决方案来管理、监控和扩展 LLM 推理。
简化 LLM 管理
ClearML 在底层工具和基础设施之上增加了一个管理层,通过一个统一的界面提供优化的性能和易用性。
首先,ClearML 提供了一个自动扩缩器,可根据实际工作负载需求自动对 AWS、GCP 和 Azure 实例进行纵向或横向扩展。只需创建一个自动扩缩器实例,然后指定符合您需求的 AWS Graviton 实例类型,瞧!ClearML 的自动扩缩器已准备好根据您的要求实时处理机器扩展。
下一步是设置 Llama.cpp 实例,它提供了一键式 Hugging Face 模型部署——只需一键即可完成!通过用户界面,您可以调整模型类型、设置 Hugging Face token 以及配置缩放至零超时等设置,使设置变得简单直接。
服务应用程序启动后,自动扩缩器会检测应用程序产生的工作负载,根据您的配置启动一个云实例,并部署模型。实例准备就绪后,应用程序会检索指定的模型,运行它,并暴露一个端点和一个聊天界面供立即使用。
但这还不是 ClearML 的全部!端点启动后,我们会为您提供一个管理仪表板,显示所有活动的端点、它们的状态和使用统计信息,让您拥有完整的可见性和控制权。
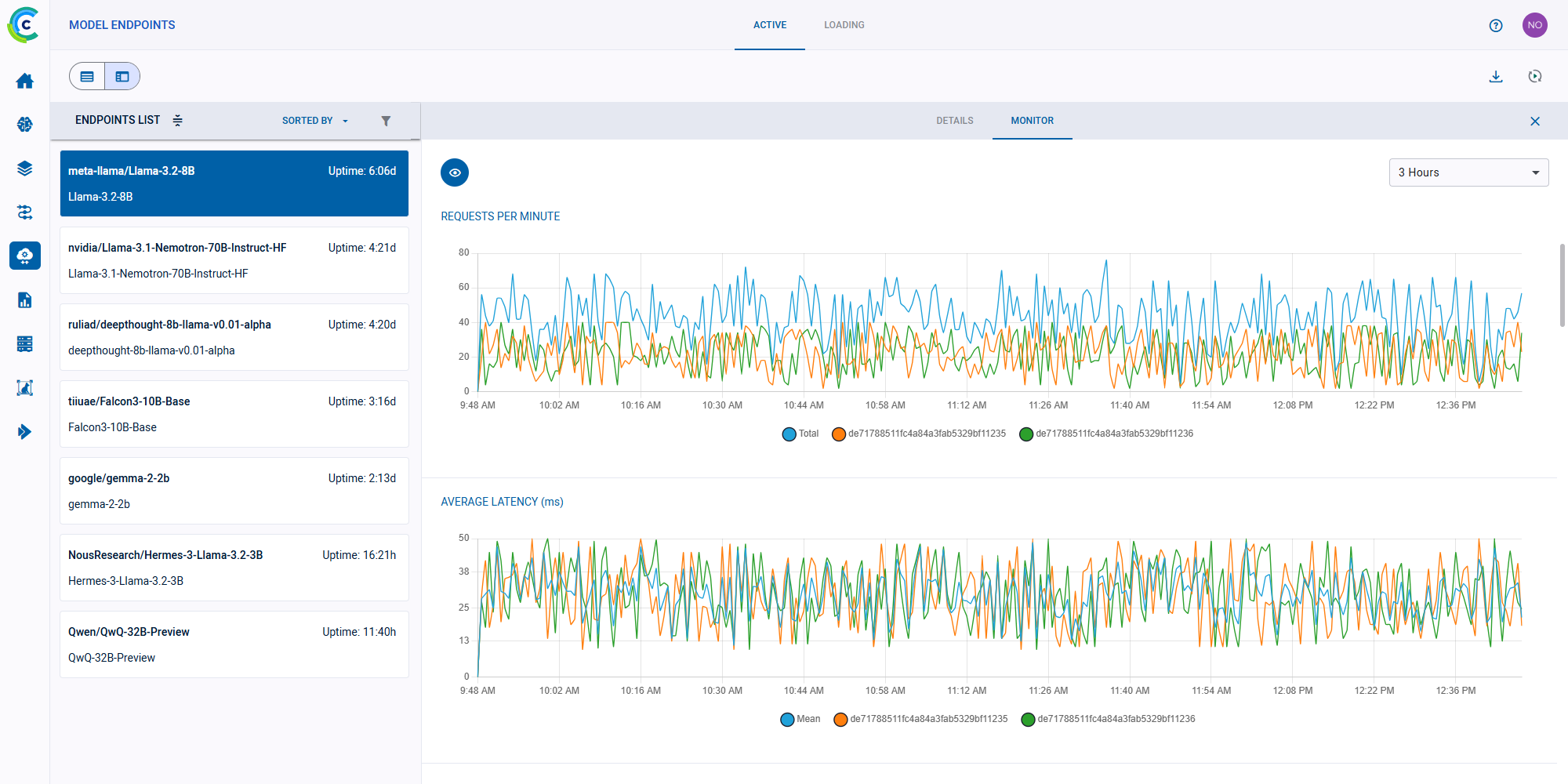
ClearML 模型端点仪表板
ClearML 还添加了一个安全层来保护模型,通过用户身份验证和 RBAC 规则只允许特定用户访问它们。这使得管理员能够跟踪用户级别的模型使用统计信息。除了安全层之外,ClearML 还管理所有进出推理服务器的网络路由,因此您无需担心配置或路由的复杂性。
Arm 上的 Llama.cpp
正如我们在之前的博客文章中强调的,在基于 Arm 的实例上运行 llama.cpp 是无缝的,无需修改代码或进行特殊配置。这得益于Arm Kleidi™ 技术,它优化了在基于 Arm 的机器上的推理工作负载,以及 llama.cpp 对 Arm64 架构的内置支持。
为了进行这次比较,我们使用用于 LLM 基准测试的开源库 llmperf,在不同的机器上测试了几种流行的量化 LLM 模型。我们对各种大小的多个模型进行了基准测试,对每个模型使用了重复测量,并取了结果的平均值。
所有测试均在 us-east-1 区域的 AWS 实例上进行。
结果不言自明:在每美元的 tokens 吞吐量方面,基于 Arm 的 AWS 实例的性能比 x86 替代方案高出多达 4 倍。
我们可以看到,在性价比方面,基于 Arm 的实例比基于其他 CPU 供应商的实例好 2-4 倍。
结论
正如我们向您展示的,在 Arm CPU 上使用 llama.cpp运行推理,借助 Arm Kleidi™ 技术,就像即插即用一样简单。ClearML 使启动端点的过程只需几次鼠标点击,您可以在此处阅读如何进行设置。我们的经验还表明,与 x86 替代方案相比,Arm 在性价比方面提供了更优越的选择。想了解更多?阅读 ClearML 如何帮助团队通过硬件、云和供应商无关的互操作性充分利用其计算基础设施。如果您有兴趣了解 ClearML 的实际应用,请申请演示。
| 模型 | 实例类型 | $/小时 | vCPU | 内存 | Token/秒 | 每美元 Tokens |
| granite-7b-instruct | c8g.2xlarge | 0.31792 | 8 | 16 GiB | 14.41 | 163173 |
| granite-7b-instruct | c7i.2xlarge | 0.357 | 8 | 16 GiB | 4.48 | 45176 |
| granite-7b-instruct | c7a.2xlarge | 0.46368 | 8 | 16 GiB | 5.41 | 42003 |
| Llama 3 8b | c8g.2xlarge | 0.31792 | 8 | 16 GiB | 12.43 | 140752 |
| Llama 3 8b | c7i.2xlarge | 0.357 | 8 | 16 GiB | 3.91 | 39428 |
| Llama 3 8b | c7a.2xlarge | 0.41056 | 8 | 16 GiB | 4.56 | 39984 |
| QWEN 32B | r8g.4xlarge | 0.94256 | 16 | 128 GiB | 6.09 | 23260 |
| QWEN 32B | r7i.4xlarge | 1.0584 | 16 | 128 GiB | 3.7 | 12585 |
| QWEN 32B | r7a.4xlarge | 1.2172 | 16 | 128 GiB | 4.22 | 12481 |
| Llama 3 70b | r8g.4xlarge | 0.94256 | 16 | 128 GiB | 2.5 | 9548 |
| Llama 3 70b | r7i.4xlarge | 1.0584 | 16 | 128 GiB | 1.36 | 4625 |
| Llama 3 70b | r7a.4xlarge | 1.2172 | 16 | 128 GiB | 1.45 | 4288 |
