作者:Alberto Garcia,高级机器学习工程师;Ksenia Yashina 博士,Orbem AI 负责人
Orbem 是一家处于工业 MRI 前沿的深度科技初创公司,每天处理海量 MRI 数据,以便在自动化生产线上对鸡蛋或种子等物体进行分类。这些专用 MRI 扫描仪会产生数 TB 的数据,我们的 AI 模型必须在边缘设备上实时处理所有数据——在那里,每一毫秒都至关重要。

在这样的环境中,调试训练失败、优化推理速度以及确保一切在生产环境中按预期运行可能会让人感到力不从心。我们曾熬夜与 SSH 会话、不匹配的库和 GPU 故障作斗争,只为重建一次崩溃的训练运行。在生产环境中追踪性能瓶颈通常需要仔细检查硬件时间线和内存日志。这实在太麻烦了。
ClearML Session 彻底改变了整个过程。ClearML Session 是一项功能,允许用户启动 JupyterLab、VS Code 和 SSH 会话,并在更能满足资源需求的远程机器上执行代码。此功能提供本地链接,通过安全加密的 SSH 连接访问远程机器上的 JupyterLab 和 VS Code。现在,我们无需手动进行繁琐的设置,就能无缝地进入任何过去的实验,以交互方式诊断问题,并在类似生产的环境中优化模型,所有这一切都无需通常的运营麻烦。
使用 ClearML Session 调试 AI 训练运行
为工业 MRI 训练深度学习模型不仅仅是为了达到高精度;我们需要稳定的数据版本控制和训练管道,以及处理意外错误的策略。我们经历过不少训练崩溃的情况:不稳定的损失曲线、数据标签错误或形状不匹配,以及只在大型运行中出现的难以捉摸的数据加载器 bug。
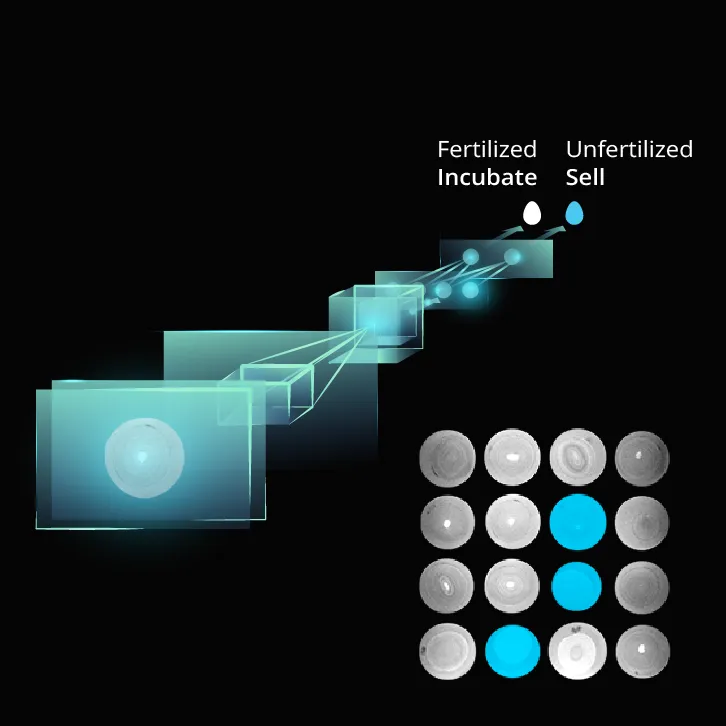
在 ClearML Session 之前,调试这些问题既缓慢又令人沮丧。日志通常缺少细节,环境可能已经改变,而且 GPU 通常被其他任务占用。我们会浪费时间手动尝试重建旧实验,希望能找到相同的数据和依赖版本。与硬件相关的问题,如 CUDA 驱动程序不匹配或内存溢出,在不同机器上的表现也不同,因此本地调试并不总是可靠。
现在,当模型崩溃时,我们可以在其失败的确切环境中启动交互式调试会话。一个命令即可恢复数据集、依赖项甚至未提交的代码更改,与本地环境或硬件无关
clearml-session --debugging-session <task-id>
在该会话中,我们可以逐行调试代码、检查变量并重新运行部分训练步骤。我们甚至可以可视化 mini-batch,以便尽早发现标签错误的数据并分析 GPU 瓶颈。我们无需花费数小时重建失败的运行,而是可以立即修复问题,通常只需几分钟。
由于 ClearML 的数据集版本控制会跟踪每个数据集版本,这些调试运行完全可重现。如果特定数据集版本是罪魁祸首,我们可以使用完全相同的数据集重新启动新会话。模型工件也与其来源实验保持关联,因此我们可以检索已训练的模型,并在其最初开发的环境中准确验证其性能。
ClearML Session 在协调跨多个计算环境的工作流程方面也表现出色。无论我们在 AWS、Google Cloud、Azure 还是本地自建硬件上运行,ClearML Session 都可以在任何连接的实例上启动交互式调试或开发会话。这种灵活性有助于我们在不同类型的硬件上对训练管道进行故障排除。
规模化模型的性能分析、优化和部署
一旦训练稳定,我们的下一个挑战是确保训练好的模型能够处理现实世界的性能需求。我们的 MRI 扫描仪每小时处理数千次扫描,因此即使是很小的效率低下也会代价高昂。调试会话有助于我们修复故障,同时也可以在推广模型之前,在目标硬件上测试和优化模型。
为了在类似生产环境的硬件上分析推理性能,我们运行
clearml-session --queue gpu_queue_A100 --docker registry/nvidia_tensort:latest --session-name "Production GPU profiling"
此命令会自动启动与我们生产环境匹配的交互式会话。使用 Nsight Systems 或 PyTorch Profiler 等工具,我们可以检查内核执行时间线并识别数据传输或处理瓶颈。基于这些洞察,我们尝试进行优化,例如固定内存 (用于更快的数据移动) 和混合精度推理 (用于速度/精度之间的权衡)。
瓶颈解决后,我们在会话中验证吞吐量和内存使用情况,以确保 GPU 得到有效利用。通过将真实数据输入 ClearML Session,我们在模型投入生产之前确认其延迟和资源需求。
Orbem 为何信赖 ClearML Session
ClearML Session 已成为我们开发 AI 模型不可或缺的一部分。我们可以在几分钟内调试失败的训练运行,尽早发现性能瓶颈,并在模拟生产环境的硬件上验证模型。这为我们节省了数天的试错时间,并避免了与基础设施的斗争。因此,我们可以将时间投入到真正的创新中,训练模型来解决世界上最棘手的挑战。
如果您曾难以重现失败的运行或担心您的模型是否符合生产约束,ClearML Session 值得探索。申请 ClearML 演示,了解更多关于其 AI 基础设施平台的信息,该平台包括用于简化 AI/ML 工作流程的 AI 开发中心、用于管理 GPU 集群和优化计算利用率的基础设施控制平面,以及用于轻松部署生成式 AI 模型的 GenAI 应用引擎。
不再有“在我机器上可以运行”的情况——只有快速、可扩展且可用于生产的 AI。
关于 Orbem 的更多信息
在 Orbem,我们通过为万事万物释放 AI 驱动的成像力量,来揭示世界上最棘手的挑战。对我们而言,这意味着开发快速、准确且易于获取的成像解决方案,从而揭示隐藏的知识来源。
Orbem 成立于 2019 年,是慕尼黑工业大学的衍生公司,其基础源于 AI 和成像技术交叉领域多年的科学研究。我们的总部位于慕尼黑,拥有一支顶尖、国际化、多元化和多学科的团队,每天都在构想新的前沿,以构建可持续和健康的未来。访问 https://orbem.ai/ 和 https://orbem.ai/blog/ 了解更多信息。
