我们最近与 Incode 机器学习工程副总裁 Alex Golunov 探讨了该公司如何使用 ClearML。以下是他的看法。
关于 Incode
Incode 是一家世界一流的身份验证解决方案提供商,结合了前沿的人工智能和机器学习技术,帮助企业区分良好用户和欺诈用户。Incode 技术的核心是 100 多个专有的机器学习模型,用于验证每次入驻会话。
解决成长中的难题
为了做到这一点,团队随着时间的推移而壮大;然而,随着团队规模的扩大,他们在管理不断增长的数据集方面面临着重大挑战,其中包括训练数据和测试数据。复杂性还延伸到硬件管理,特别是分布在不同云提供商和裸金属机器上的 GPU 资源,这些资源需要高效的编排来处理模型训练的计算需求。此外,团队还需要强大的实验跟踪能力来监控和比较不同的模型迭代,以及一个可靠的远程执行训练任务的系统。没有一个集中的 MLOps 平台,他们难以解决诸如不可靠的测试、重复性工作以及难以有效协调资源等问题。随着数据集增长到太字节级别,在维护数据质量和实验可重复性的同时扩展基础设施的需求变得越来越关键。正是在那时,他们转向了 ClearML。
使用 ClearML 进行 GPU 编排
ClearML 通过 ClearML 代理提供了一个易于使用但仍然非常灵活高效的 GPU 编排层。这些代理可以部署在不同的机器和云提供商上,自动接收排队的实验并在可用的 GPU 资源上执行它们。该系统支持动态资源分配、队列管理和优先级设置,使其成为处理分布式计算资源的团队的理想选择。
动态 GPU 分配
“对我们来说最重要的功能之一是 动态 GPU 分配,这是 ClearML 企业版计划提供的功能,” Incode 机器学习工程副总裁 Alex Golunov 说。“这个功能允许您将代理连接到多个队列,每个队列都配置为使用特定的资源分配运行——这是多 GPU 节点的一项基本能力。” 以下是 Incode 配置示例:
clearml-agent daemon \\
--detached \\
--docker \\
--dynamic-gpus \\
--queue onprem.1xA100=1 onprem.2xA100=2 onprem.4xA100=4 \\
--gpus 0,1,2,3,4,5,6,7
AWS 自动伸缩器
Incode 的另一项重要功能是 AWS 自动伸缩器。这个强大的自动化工具通过根据工作负载需求自动配置和终止 EC2 实例来实现动态资源管理,同时保持在用户定义的资源预算范围内。自动伸缩功能智能监控队列长度和资源利用率,通过根据需要扩展或缩减计算资源来确保最佳成本效益。
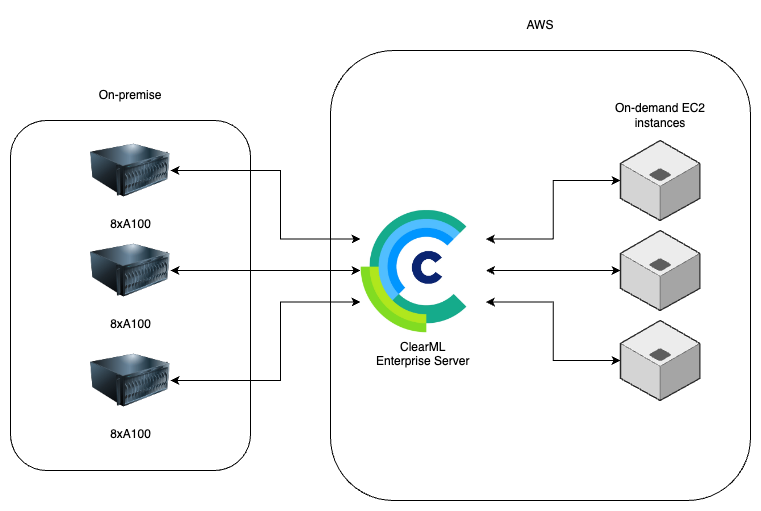
Incode 架构
让我们看看 Incode 当前的高级架构,它展示了其系统的全面集成,并说明了不同组件如何交互以创建强大且可扩展的基础设施
数据管理
在高效协作和实验可重复性方面,强大的数据管理对于维护有条理的工作流程和确保团队之间的结果一致性至关重要。”Incode 机器学习工程副总裁 Alex Golunov 表示:“在 Incode,我们面临着管理和协调大量数据集的复杂挑战,其中包括数百个不同的数据集合,包含数亿个独立数据点。” “这些多样化的数据点涵盖多种格式和类型,包括高分辨率图像、视频、结构化和非结构化文本文档以及全面的表格数据集。我们的数据基础设施总量已达到一个重要的里程碑,目前已超过 10 太字节且仍在持续增长。为了有效管理、组织和维护如此大量的数据,同时确保无缝访问和版本控制,我们正在使用 ClearML 企业版计划提供的复杂的 Hyperdatasets 解决方案,这是一种企业级数据管理系统。”
Incode 使用 ClearML Hyperdatasets 的经验
- 通过在 Hyperdatasets 中实现版本控制,他们能够跟踪数据集中所有的变化,并在需要时快速恢复到以前的版本,这对他们的迭代开发过程至关重要
- 元数据管理功能帮助他们维护数据集属性和标注的详细记录,使团队更容易理解和使用不同的数据集合
- 随着团队的壮大,细粒度的访问控制对于管理谁可以访问和修改特定数据集至关重要,这确保了数据的安全性和完整性
- Incode 经常使用高级查询功能来过滤其庞大的数据集,这在处理特定数据子集时显著提高了他们的工作流程效率
- 与现有机器学习管道的无缝集成节省了他们大量开发时间,并减少了潜在的集成问题
构建高级数据管道
Incode 全面身份验证平台提供的核心功能之一是先进的文档读取和分析。经过多年的专注研究和开发,他们精心设计并完善了一种最先进的、市场领先的自动化解决方案,该方案无缝集成了多个高级组件,包括精确的文档检测、准确的分类以及高度可靠的光学字符识别(OCR)。这个代表着广泛工程努力结晶的复杂技术管道,需要持续的改进和细致的维护以保持其卓越的性能水平。这样一个复杂系统的有效性根本上取决于卓越的数据质量以及持续的数据增强和完善。通过实施 ClearML Hyperdatasets,Incode 成功建立了强大且高度可扩展的数据收集和标注基础设施。这个复杂的管道是生成高质量训练数据的基本要素,这些数据对于支持和持续改进其机器学习模型至关重要。
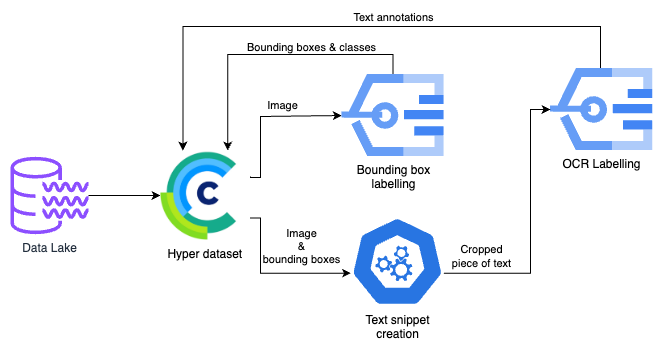
该管道包含以下组件
- 数据湖
- 流程始于存储在数据湖中的数据。这里存放着初始图像以及初始模型预测结果。
- Hyper Dataset
- 来自数据湖的数据被传输到 Hyperdataset。这一步涉及组织和准备数据进行进一步处理,重点在于创建一个结构化数据集。
- 边界框标注
- Hyper dataset 中的图像被发送到边界框标注流程。在此,对每张图像进行分析,以识别特定的感兴趣区域,并用边界框标记出来。同时识别这些框内包含的对象类别。这有助于隔离图像中包含文本或其他关键信息的部分。
- 文本片段创建
- 从经过边界框标注的图像中创建文本片段。这包括提取和裁剪边界框内包含文本的图像特定部分。
- 文本标注
- 对文本片段进行人工审查和标注。在此过程中,人工解读片段中的文本并创建准确的标注。这些标注对于训练和验证专注于文本识别的机器学习模型至关重要。
在此流程结束时,结果是组织成 Framegroups 的结构良好数据,这些数据后续用于训练多个机器学习模型。
结论
ClearML 的实施对 Incode 的机器学习运营带来了变革。通过其全面的工具套件,包括 GPU 编排、AWS 自动伸缩器和 Hyperdatasets,该公司在工作流程效率和可扩展性方面取得了显著提升。该平台使 Incode 能够
- 有效管理和分配其基础设施中的 GPU 资源,优化资源利用率并减少计算瓶颈
- 根据需求自动扩展其 AWS 基础设施,确保成本效益,同时保持高性能
- 通过强大的版本控制和元数据管理,成功处理了其目前已超过 10 太字节的大规模数据集
- 简化其机器学习管道流程,从数据收集到模型训练和部署
采用 ClearML 不仅解决了他们最初的挑战,还使他们能够应对未来机器学习运营的增长和复杂性。该平台的企业级功能在保持我们作为领先身份验证解决方案提供商的地位方面发挥了宝贵作用。
如果您想了解 ClearML 如何帮助简化您组织的机器学习工作流程,请申请演示。
