ClearML 实验管理工具助力 ArgoScout 成长!
作者:Yaniv Menashe,AgroScout 有限公司人工智能工程师。
在AgroScout,我们正在应对一个巨大的挑战,这对我们和客户来说都有令人兴奋的益处:创建一个自动化、AI 驱动的侦察平台,用于早期检测广阔农业区域的病虫害。通过精确的、数据驱动的洞察(手动定期采样无法获得),农民可以在提高单位面积产量的同时主动预防作物和相应收入的重大损失——这一切都通过更精确地定位问题区域来减少农药使用。
为什么如此困难?
现在,问题来了——为了收集作物数据,我们使用无人机和摄像头画面来识别这些威胁的细微迹象。如果这一切只是像专注于 AI 图像分析的公司(医疗、建筑、交通等)面临的常见大数据挑战,我们只需投入大量计算资源就能解决。但农业领域的图像分析工作带来了一些独特的挑战:
- 标注并非易事;即使专家也无法找到所有植物缺陷
- 分析需要聘请一组专业的全球专家进行标注;管理他们的工作和标准化他们的术语需要精确
- 高数据模态。每个田地——甚至每个田地的数据集——都有独特的多输入特征需要学习和合并(例如,不断变化的光照或飞行角度)。
- 规模——仅一张图像就可以产生数千个标注,且标注质量检查很困难;通常有数万张这样的图像。
构建数据管道的关键在于工具
那么我们是如何直面这些挑战的呢?我们意识到需要在工作流程中集成一套数据科学工具,以分担所有这些任务中的繁重工作。
我们研究的首选是ClearML,因为它声称易于集成,并且提供我们所需的大部分功能,全部集成在一个平台中:从跟踪我们的研究到管理我们的云机器,再到数据管理。
![]()
用单一平台应对六大挑战
挑战 1
处理这些高分辨率图像。
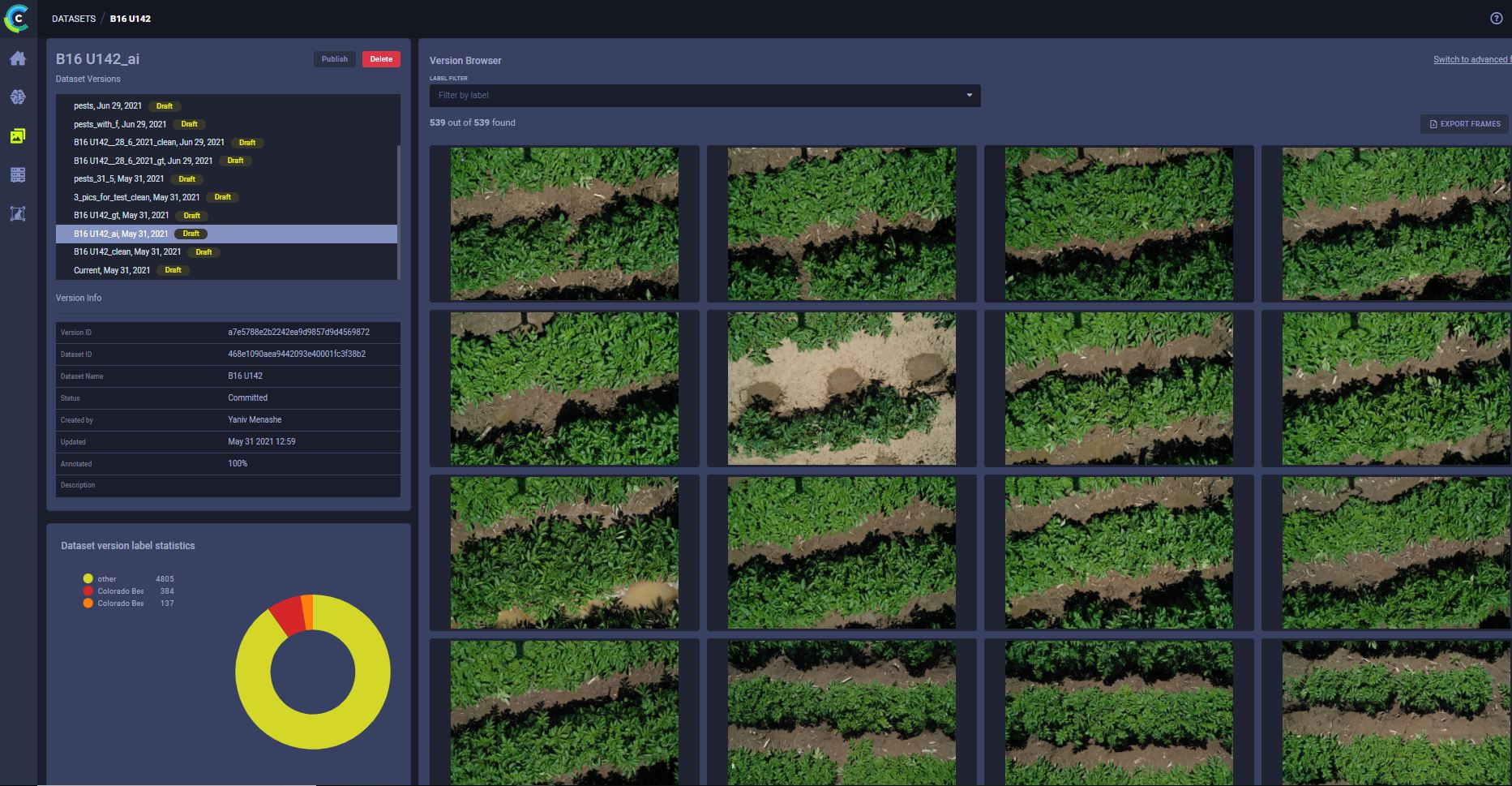
这些大图像对处理它们的 GPU 来说负担很重,因此我们在用于训练之前将图像切割成子图像,使其更易于管理。通过创建较小子图像的“版本”,可以在数据集中创建“预处理版本”,从而减少每个训练阶段所需的时间,并倍增我们管理的小文件数量。借助 ClearML 的数据集管理功能,我们可以为每个数据集创建多个版本,包括已完成预处理阶段并准备好进行训练阶段的版本。
由于存储空间比计算资源便宜得多,这是我们的自然选择,ClearML 使这一切变得容易。仅这一点就改变了游戏规则,但这仅仅是个开始。
挑战 2
处理生物领域难以泛化的问题。
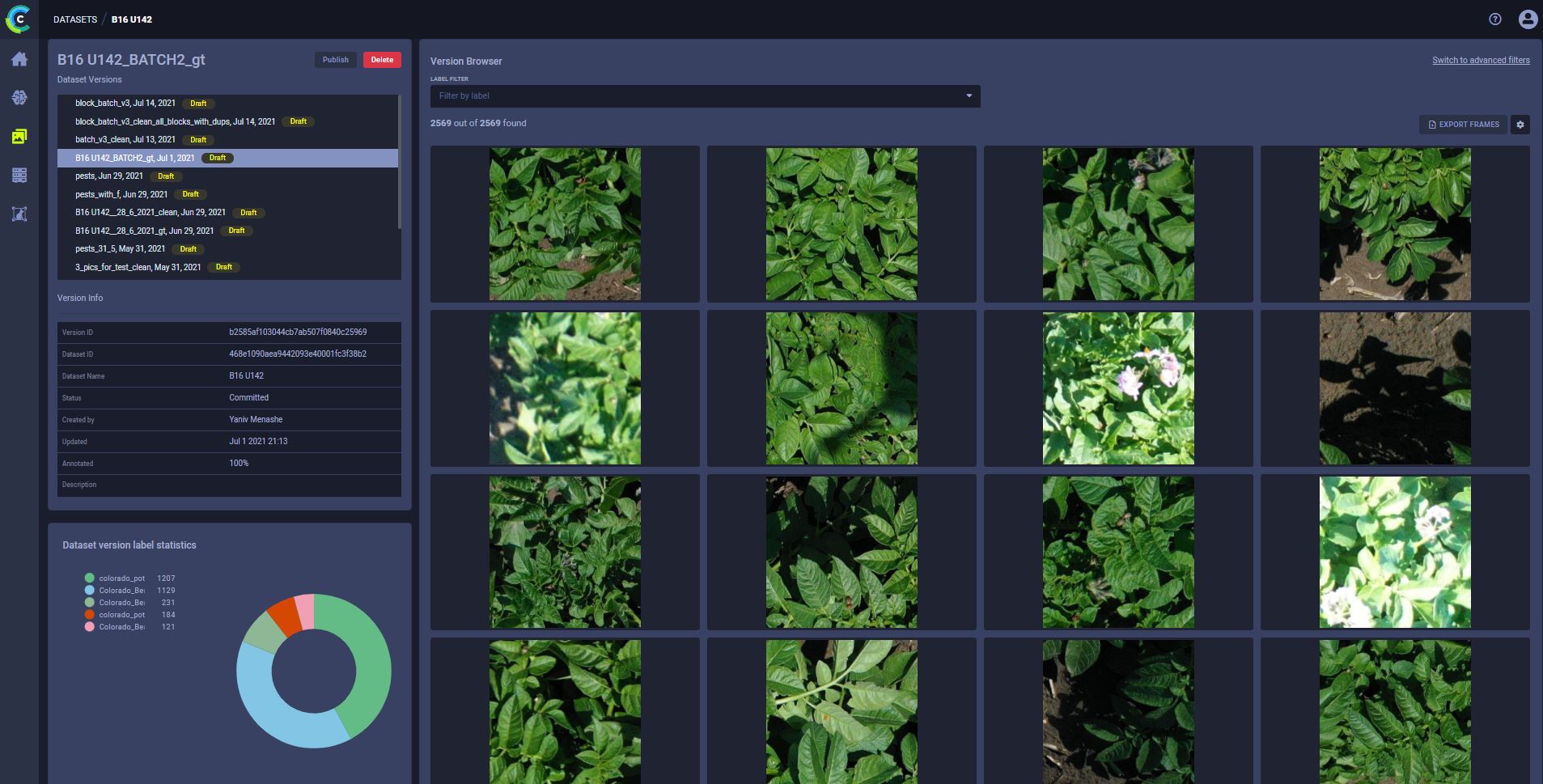
为了说明这一点,我们先看一张照片

正如您所猜测的,即使是人类,也很难检测出所有的病虫害,并决定如何准确分类所检测到的内容。但它们确实存在。成百上千种。
如前所述,对于这些任务,我们需要熟练的农艺师标注人员来帮助我们的模型。但要找到足够多具有各种专业知识的人员,需要与不止一家公司合作,并与首次担任标注员的农艺师合作。从一开始,我们就意识到需要处理来自不同公司使用不同 JSON 格式的标注不一致问题。
解析了各公司使用其独特的 JSON 模式的输出后,我们发现虽然我们给了所有公司相同的标签名称,但它们对这些标签返回了不同的输出。更棘手的是……差异不仅限于不同公司;即使同一家公司在不同项目上工作,我们也发现了这些差异!
解决方案?我们发现在 ClearML 的 UI 中的数据集统计数据中 可以 立即发现差异。在识别出不匹配项和所需的统一策略后,我们部署了 ClearML 便捷的映射工具,为代表同一类别的所有标签创建了别名规则。
挑战 3
标注不断增长的数据集,具有相当大的差异,并且尽量减少错误。
由于 AgroScout 在全球五大洲开展农业业务,每个田地都有其独特的特征:作物类型、天气、作物年龄、土壤等等。此外,每次飞行都可能受到不同变量的影响(一天中的时间、天气、飞行路径)。因此,具有独特元数据的数据集的数量也随之增加。
然后,管理数据是一个问题。一方面,您希望所有元数据都随时可用;另一方面,为每种数据类型维护多个文件夹,使得浏览数据和获取“全局概览”并非易事。
我们选择使用 ClearML 的Hyper-Datasets来帮助我们解决数据组织问题。
我们决定将每一次飞行表示为一个不同的版本。
ClearML Hyper-Datasets 使我们能够探索数据,然后将其(使用精细粒度)提交到训练过程中。我们可以控制模型查看哪些田地、作物类型、一天中的时间或任何其他数据信息,从而可以构建高度专业化的模型。显然,所有内容都已记录,以便我们可以在训练后进行分析,并根据需要重现模型。
挑战 4
处理包含数千个标注的图像
ArgoScout 的产品之一是植株计数 (Stand Count)。该产品允许用户高分辨率监测田地,将拼接的照片马赛克作为地图上的一个图层显示。在这个图层之上,用户可以看到数千个标注,代表农民需要精确了解植物生长情况的四种不同类别:
- 土壤隆起 (Ground lift) – 地面向上隆起,表明很快会有植物在那里发芽
- 初生 (First emergence) – 植物发芽后的最初几天
- 植株 (Plant) – 一棵成熟的植物
- 空缺 (Gap) – 田地内没有上述任何情况的区域
这种多模态意味着每张图像的标注数量异常高。如此大量的标注不仅给标注人员带来了问题,它还将标注软件推向极限。我们必须选择能够随着我们规模扩展而扩展(图像增长 10 倍可能意味着标注增长 10k 倍)的数据管理软件,并看到 ClearML 在处理这种数量的元数据方面没有问题。它还允许我们如果发现错误,可以即时编辑标注。
挑战 5
管理 GPU 实例上的工作负载
训练和测试我们的许多模型需要 GPU 资源。像许多公司一样,我们选择使用 AWS 作为我们的计算资源。使用 AWS Lambda 作为获取田地数据的接口,我们构建了由 AWS Lambda 触发的数据摄取管道。然后,使用 ClearML,我们在 EC2 实例上管理用于训练的工作负载。通过这种方式,我们可以直接从一个地方启动实验,然后使用 ClearML 的编排 UI 进行监控和管理。同样,从理论上讲,我们可以手动完成,但这比 ClearML 专为此类任务设计的优雅管理工具更笨拙、更耗时。
挑战 6
确定哪些模型更适合我们的任务
显然,这是数据科学公司最常见的任务:在训练许多模型(通常是同时进行)以及多种环境(包括本地和云端)时,我们需要有效的工具来比较不同实验的结果。在 ArgoScout,由于我们的“模糊”生物数据代表了有机景观不断变化和不可预测的性质,这种模型比较过程异常流畅和动态。在这些实验运行时,拥有一个强大的比较工具至关重要:我们用它来决定停止哪些实验,以及让哪些模型运行到最后进行比较。没有它,我们可能需要“自己动手”构建解决方案,但我们宁愿使用经过验证的工具,而不是自己构建——这会分散我们核心科学的注意力。
结论
归根结底,每个机器学习公司都面临着基于其每天处理的独特、专业数据输入和输出的自身挑战。ClearML 的工具套件在我们的模型开发工作流程中的关键时刻提供了核心帮助,并将继续作为我们基础设施的核心组成部分。
