☁️ 现也提供云服务!
我们最近与Genesis Cloud合作推出了我们自己的GPU自动伸缩器,它取得了相当大的成功。此外,Ultralytics的YOLOv8最近也发布了,它是新的目标检测、分割和分类王者。在这篇博客文章中,我们将看到,使用ClearML/Genesis Cloud自动伸缩器训练计算机视觉模型所需的成本,仅为竞争对手云服务(如AWS或GCP)的一小部分。而且它甚至100%使用绿色能源运行! 😎
🎮 用于深度学习的云消费级GPU
消费级GPU,比如众所周知的NVIDIA RTX 3090,拥有巨大的显存,即使在原始速度方面,它们也毫不逊色。所以这篇博客文章的主要问题是:这些消费级GPU在深度学习工作负载方面,与像T4和A10G这样的真正数据中心级显卡相比表现如何?(剧透警告:它们是非常强大的竞争者!)
ClearML已与Genesis Cloud合作,为您提供从ClearML内部轻松访问这些消费级显卡的途径。当然,正如您所看到的,您也可以轻松地在AWS和GCP上启动机器,所以这是一个极好的起点来比较这些机器!
Genesis Cloud是一家欧洲云基础设施提供商,致力于提供100%的绿色计算能力,并具有高性价比。通过ClearML应用,您可以访问3种类型的消费级GPU:NVIDIA® GeForce™ RTX 3060Ti、3080和3090,它们有不同的配置(多GPU、优化内存和CPU等)

💰 数据中心级GPU与消费级GPU的成本效率
正如您可能预料的那样,数据中心级GPU与现成的消费级GPU之间的成本差异可能相当大。当然,像A100这样的超高端数据中心级显卡能够处理比最好的现成GPU大几个数量级的模型和数据集,但现实情况是,大多数人并不是从头开始训练巨大的LLM。
为了正确比较这两种类型的GPU,我们选择了YOLOv8中的“正常”工作负载(详情见下文),并选择了最受欢迎和经济的AWS GPU机器进行比较。下表列出了撰写本博客文章时(2023年3月23日)这两种机器的价格。
| 机器类型 | ClearML价格(由Genesis Cloud支持) |
| RTX 3060Ti | 0.20 |
| RTX 3080 | 0.30 |
| RTX 3090 | 0.42 |
| RTX 3080(内存和CPU优化)* | 0.36 |
| RTX 3090(内存和CPU优化) | 0.504 |
| AWS 机器类型 | GPU | AWS每小时价格(美国东部北弗吉尼亚**) |
| p3.2xlarge | V100 | 3.06 |
| g4dn.xlarge | T4 | 0.526 |
| g4dn.2xlarge | T4 | 0.752 |
| g4dn.4xlarge | T4 | 1.204 |
| g4dn.8xlarge | T4 | 2.176 |
| g5.xlarge | A10G | 1.006 |
| g5.2xlarge | A10G | 1.212 |
* 所有机器中最具成本效益的配置。详情见下文!
**我们特意选择了最便宜的AWS区域,以给AWS机器最好的竞争机会。
结果摘要
| 机器类型 | 每Epoch美元(成本效率) |
| ClearML RTX 3060Ti | 0.0102 |
| ClearML RTX 3080 | 0.0106 |
| ClearML RTX 3090 | 0.0128 |
| ClearML RTX 3080(内存和CPU优化) | 0.0096 |
| ClearML RTX 3090(内存和CPU优化) | 0.0098 |
| AWS p3.2xlarge | 0.0881 |
| AWS g4dn.xlarge | 0.0174 |
| AWS g4dn.2xlarge | 0.0213 |
| AWS g4dn.4xlarge | 0.0330 |
| AWS g4dn.8xlarge | 0.0588 |
| AWS g5.xlarge | 0.0235 |
| AWS g5.2xlarge | 0.0208 |
所有价格均为按需价格
由于基准测试总是涉及无限的可能性,我们无法涵盖所有情况。对于这篇博客文章,我们仅关注两类竞争者计算资源的按需价格。这意味着我们不考虑任何承诺使用折扣!
无多GPU
我们也不关注多GPU机器。同样,这是为了保持简单。此外,Genesis Cloud已经发布了一篇出色的博客文章,专门讨论了这一点!去看看吧,并告诉他们是我们推荐的。 😄
这也是我们不将A100包含在此次基准测试中的原因,因为目前无法在AWS上获得配备单个A100 GPU的机器。
关于Spot实例的说明
Spot实例完全是另一回事,有着非常明显的权衡。
- 当您选择Spot实例时,您知道机器可能随时被终止。这意味着您必须小心在其上运行的任务类型,并确保其进度以规律的间隔得到充分保存。如果检查点设置不正确,完成模型训练的成本可能会更高!
- Spot实例也很难找到,尤其是在北美。如果您想使用Spot实例,请在欧洲区域搜索!它们稍微贵一些,但通常实际可用。请记住,在Spot实例上运行训练可能意味着连续几天都没有进展。
另一方面,这些机器非常便宜。与任何云服务(包括Genesis Cloud/ClearML)的正常按需计算价格相比,Spot实例的成本明显更低,根本没有可比性。
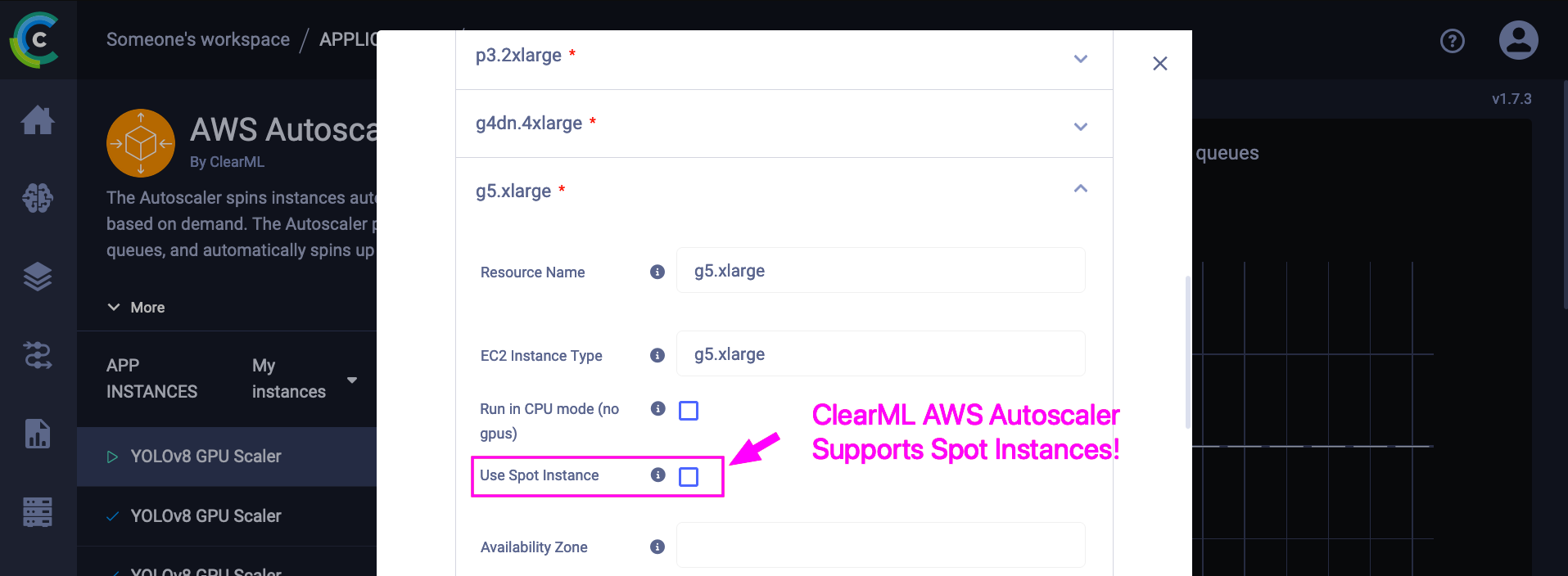
因此,是否在Spot实例上运行取决于您的这些考虑。如果您确实想使用,我们也为您提供了支持。😄 使用ClearML AWS自动伸缩器,您可以勾选此按钮直接从ClearML启用在Spot实例上运行,就像在普通AWS机器上运行一样简单。这同样适用于GCP Spot实例,使用GCP自动伸缩器。
🚀 使用YOLOv8作为基准负载
YOLOv8来自与YOLOv5相同的优秀团队:Ultralytics。YOLOv8超越了所有竞争对手,但最重要的是,它易于使用且友好。通过对其API的全新改进,您现在只需几行代码甚至一个CLI命令即可训练目标检测模型、分割模型和分类模型!
使用 ClearML 运行 YOLOv8
YOLOv8 凭借其简洁易用的 SDK,使事情变得非常简单。ClearML 在 YOLOv8 中原生集成,但如果我们以后想在不同的机器上使用不同的参数重新运行实验,则必须在初始化 YOLOv8 之前显式初始化 ClearML。
from clearml import Task
from ultralytics import YOLO
# Explicitly call ClearML init before YOLOv8
task = Task.init(project_name="YOLOv8",
task_name="detection_training",
tags=['YOLOv8'],
auto_connect_frameworks={'pytorch': False, 'matplotlib': False})
# Set some basic settings to prepare for remote execution later
task.set_base_docker("nvidia/cuda:11.4.3-runtime-ubuntu20.04", "--ipc=host")
# Put all our YOLOv8 arguments in a dictionary and pass it to ClearML
# When later we change any parameter in the UI, it will be overridden here!
args = dict(data="VisDrone.yaml", epochs=10, imgsz=640, task='detect')
task.connect(args)
# Turn the chosen model into a parameter too, so we can change this later!
model_variant = "yolov8n"
task.set_parameter("model_variant", model_variant)
# Load the YOLOv8 model
model = YOLO(f"{model_variant}.pt") # load a pretrained model
# Train the model using our arguments from before
# If running remotely they may have been changed by ClearML
results = model.train(**args)
运行此脚本就像运行其他任何 YOLOv8 训练一样,只不过现在所有内容都在 ClearML 实验管理器中被跟踪。您可以在 app.clear.ml 查看捕获的所有内容,或者在您 自己的自托管服务器 上查看。结果应该如下图所示
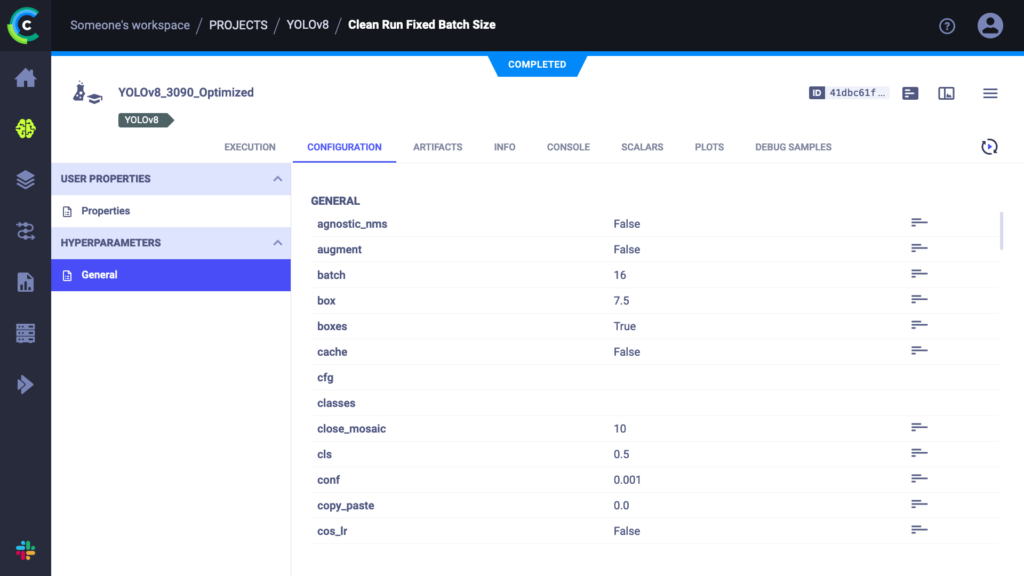
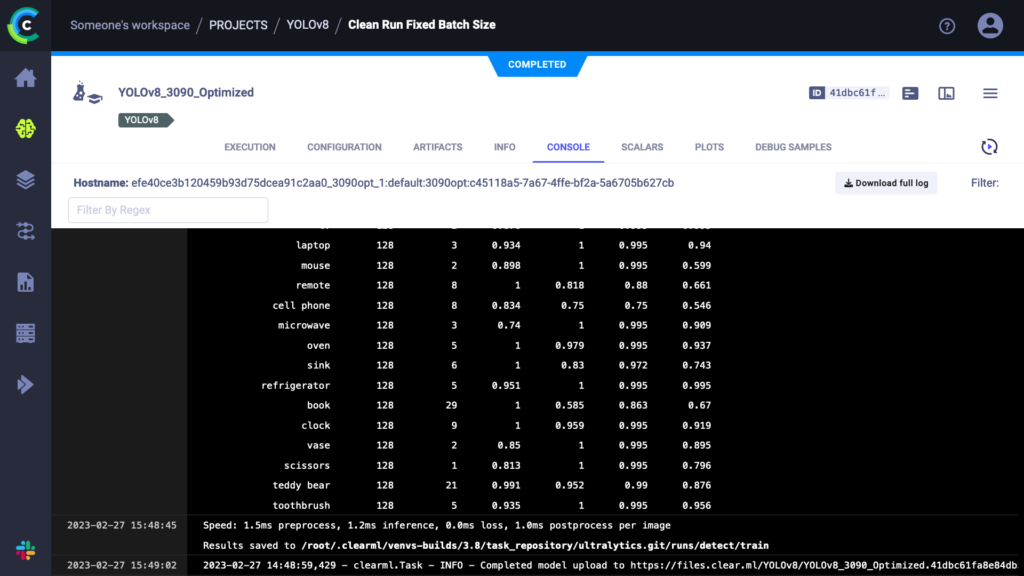
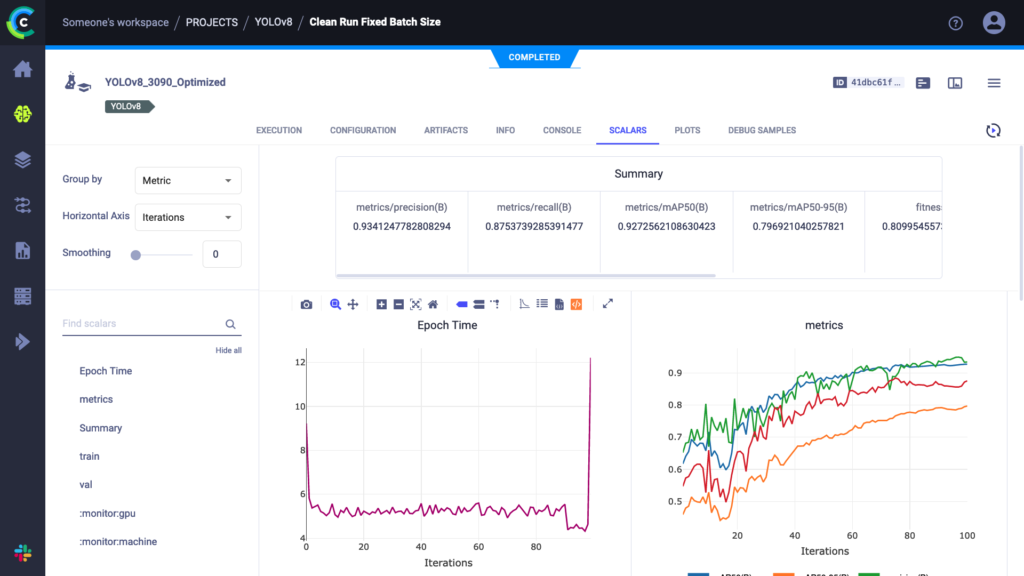
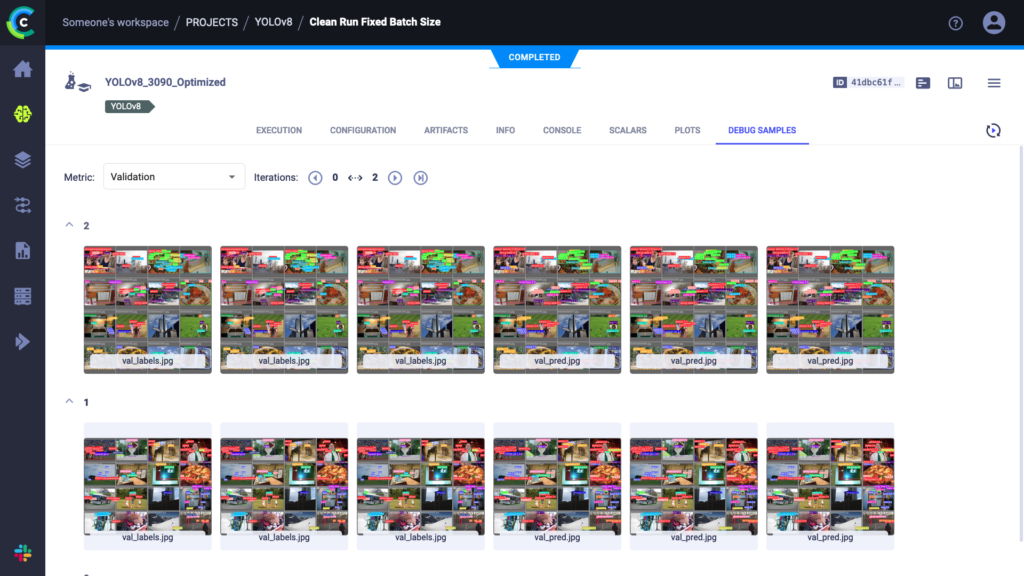
如您所见,我们需要的一切都在里面。事实上,YOLOv8 自动提供测量的时间,包括训练周期的持续时间和训练模型的推理时间。这些就是我们将在此博文的基准测试中使用的计时数据。
远程执行 YOLOv8:自动扩缩器
ClearML 还可以协调远程机器并在其上为您安排任务。在使用实验管理器在本地运行实验后,ClearML 现在也会在服务器上拥有该实验的一个副本。然后您可以从服务器设置任意数量的任务队列,并轻松将您的实验加入其中。一个工作程序(称为 ClearML Agent)将监听队列并能为您运行任务。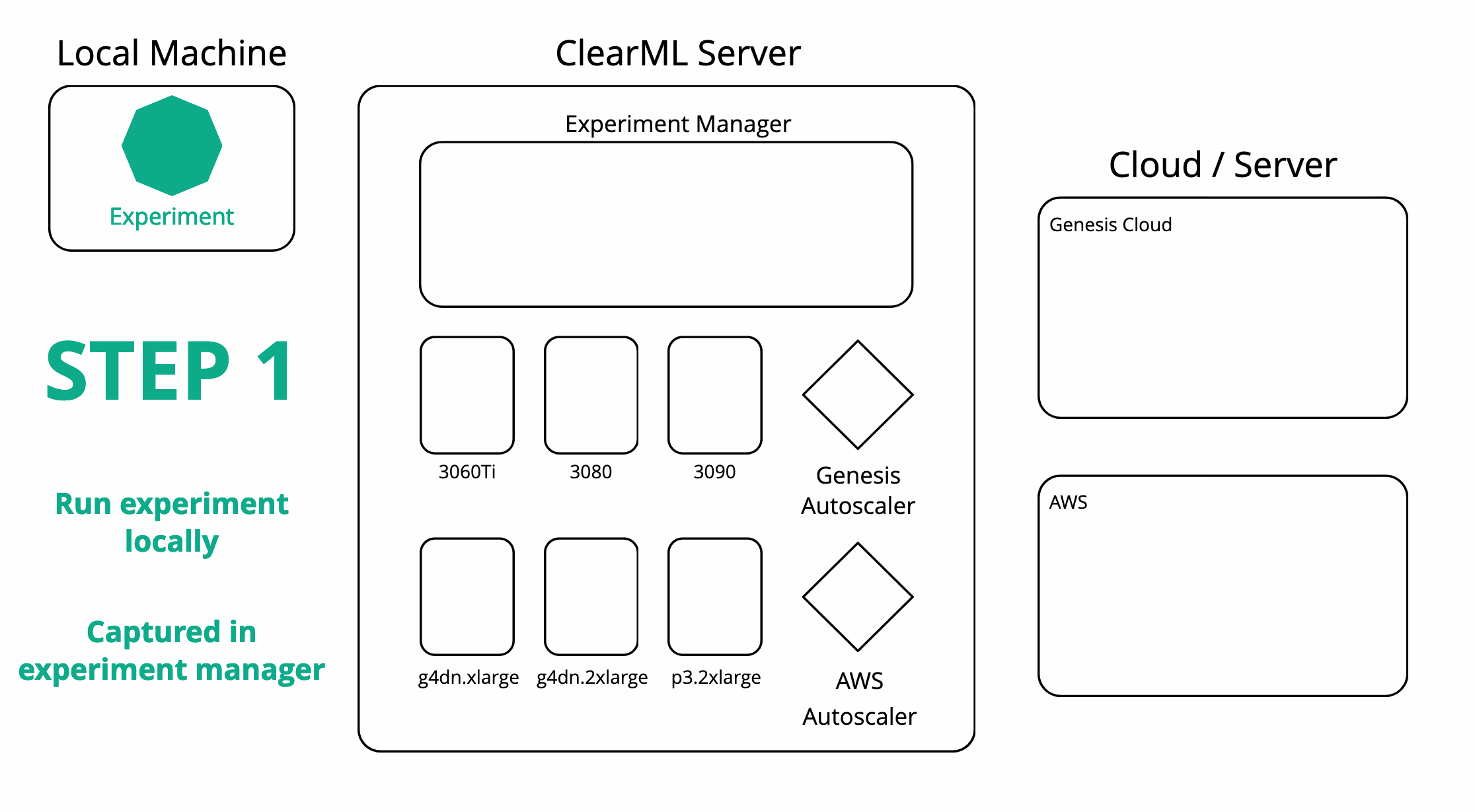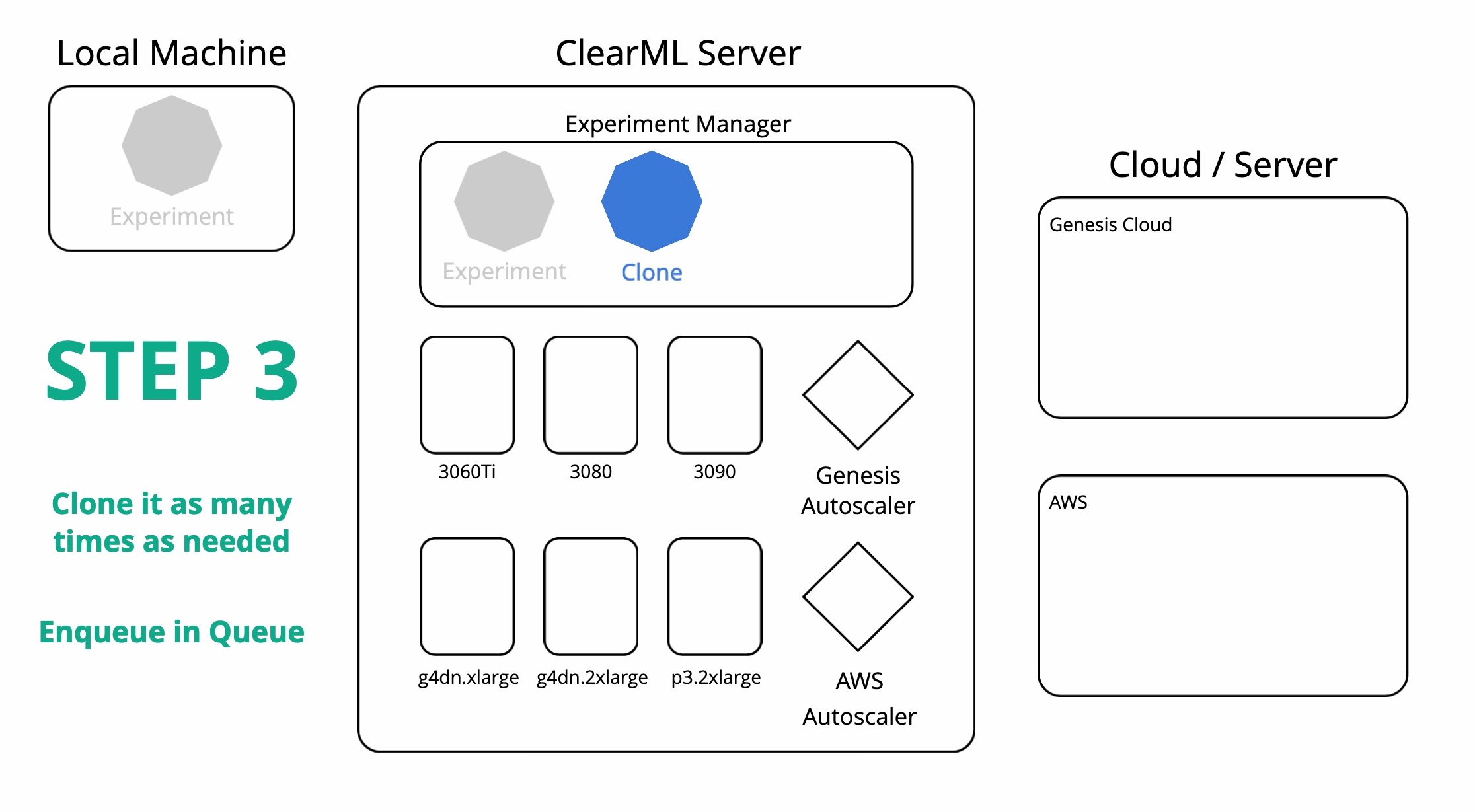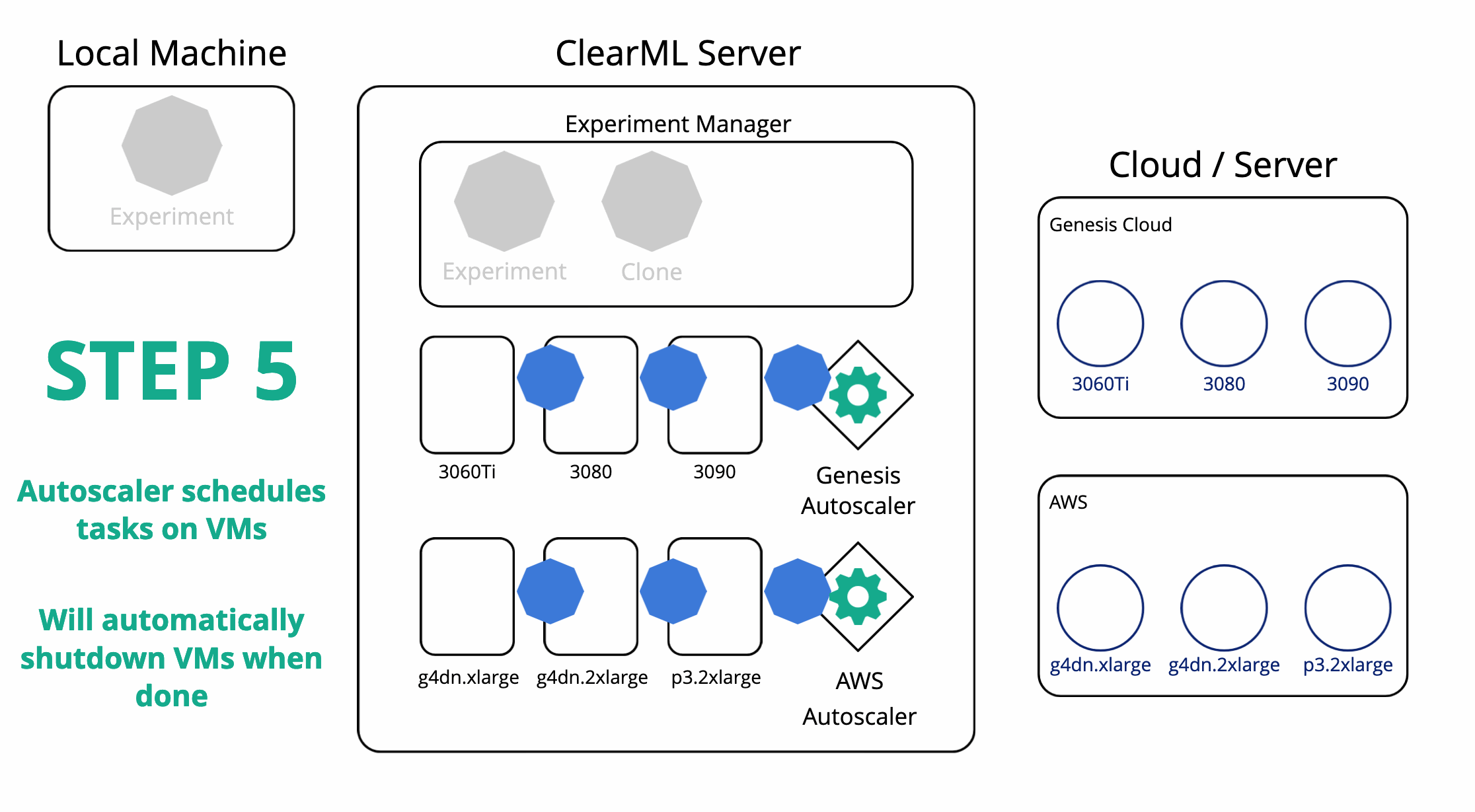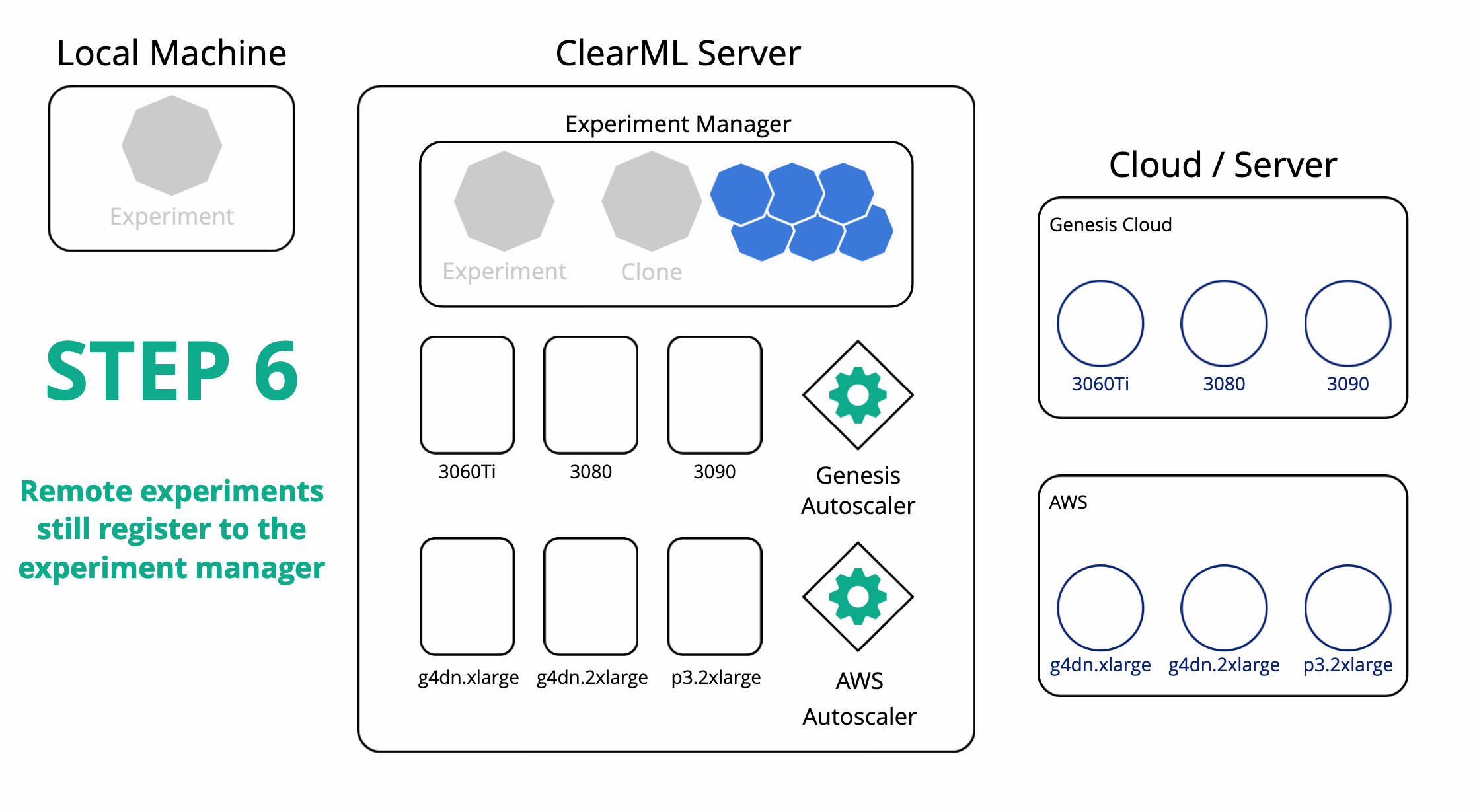
为了让工作程序运行您的任务,您可以自己设置一个,或者使用自动扩缩器。在 ClearML 中,自动扩缩器本质上是一个持续运行并监控特定 ClearML 任务队列以查找任何传入任务的服务。如果发现任务,它将自动启动一个工作程序来处理该任务。每个队列一种机器类型,您可以设置一个“预算”,限制该类型机器同时运行的数量。
现在,在任何目标云机器上重新运行我们的实验就像克隆它并将其放入正确的队列一样简单。相应的自动扩缩器将接收任务,并开始启动所需类型的虚拟机。所有结果当然都会实时流回实验管理器,我们可以在其中跟踪进度。
🔥 基准测试结果
如您在上面的代码片段中所见,我们选择了VisDrone数据集作为我们的示例基准测试数据集。我们针对每个参与者调整了批量大小,使其尽可能高,然后对它们中的每一个运行了YOLOv8训练。
原始性能数据
下表列出了每个机器类型针对完全相同的任务(不同的批量大小)的平均训练运行时长。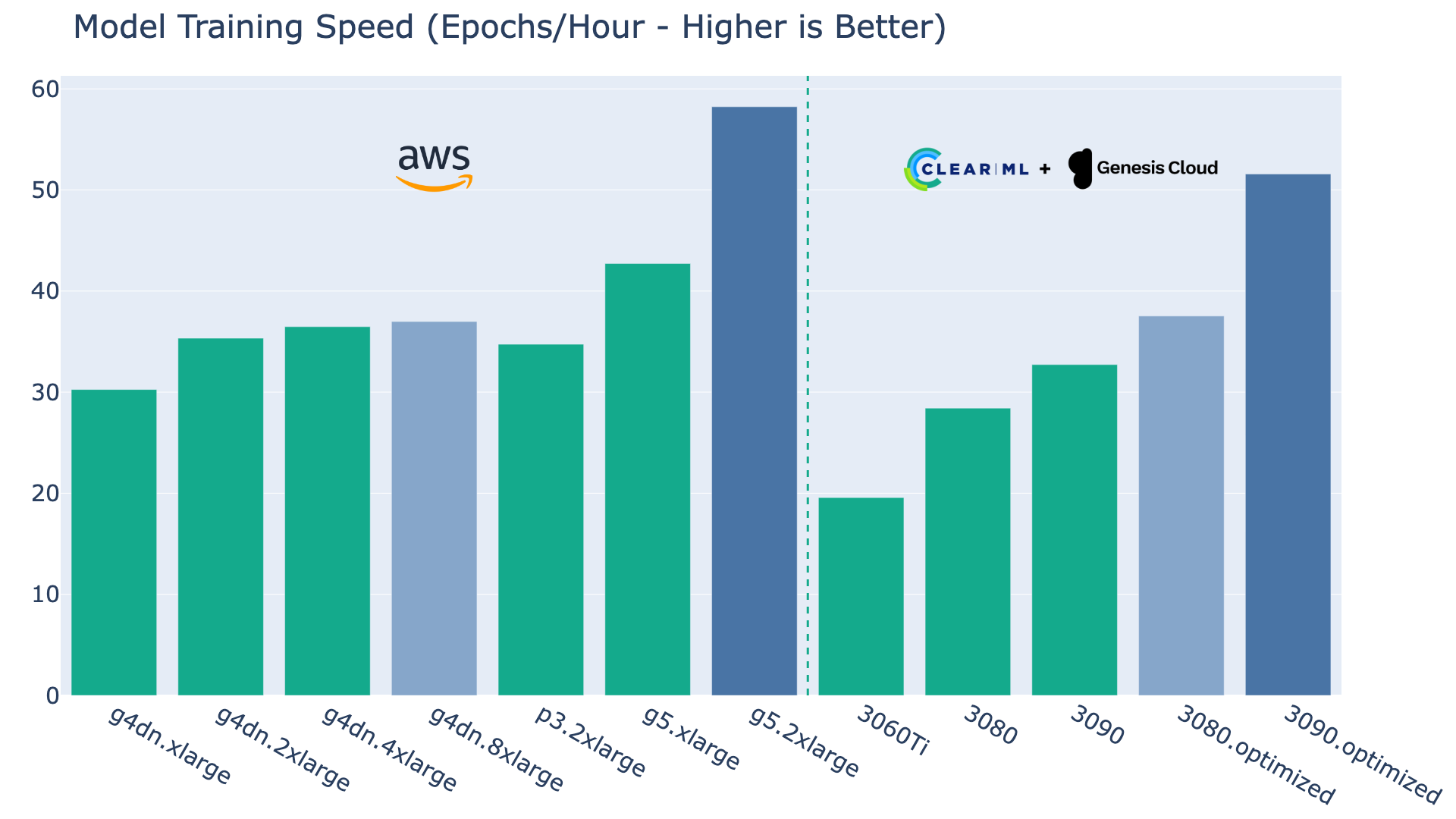
不出所料,3060Ti的性能远低于其他机器,但记住它的价格也显著较低,我们稍后会分析。
3080和3090机器表现良好,与g4dn的NVIDIA T4显卡相比,它们通常能够独当一面。然而,在较低端,我们确实看到两种机器类型都受到了CPU瓶颈的影响。VisDrone数据集图像较大,所以这可能取决于使用场景。
3080和3090的内存和CPU优化版本显然克服了CPU瓶颈,并因此将整个g4dn系列甩在了身后,进入了g5的领域。事实上,Genesis Cloud在他们自己的博客文章中也得出了同样的结论,为这一说法提供了额外的证据。特别是优化的3090配置能够与价格显著更高的g5.2xlarge抗衡。话虽如此,纯粹的性能赢家仍然是g5.2xlarge。
考虑成本
当然,我们并非在此简单地确定最快的GPU机器,如果您不担心成本,您可能已经在您的8x A100虚拟机之上微笑了。然而,对于我们其余的人来说,成本效率确实很重要。
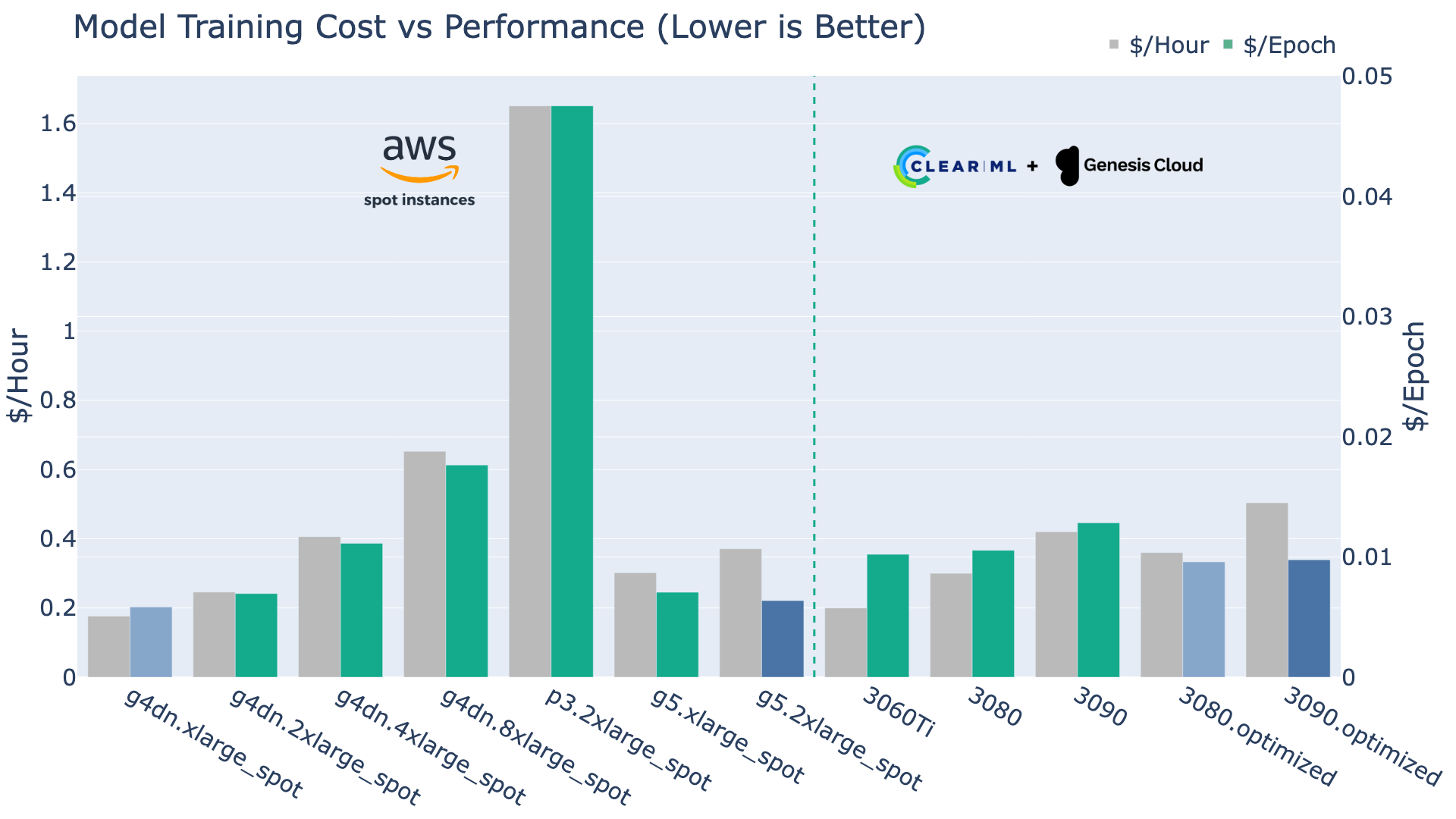
下图向我们展示了每台机器每小时的价格,然后,至关重要的是,每epoch的成本,也可以理解为成本效率。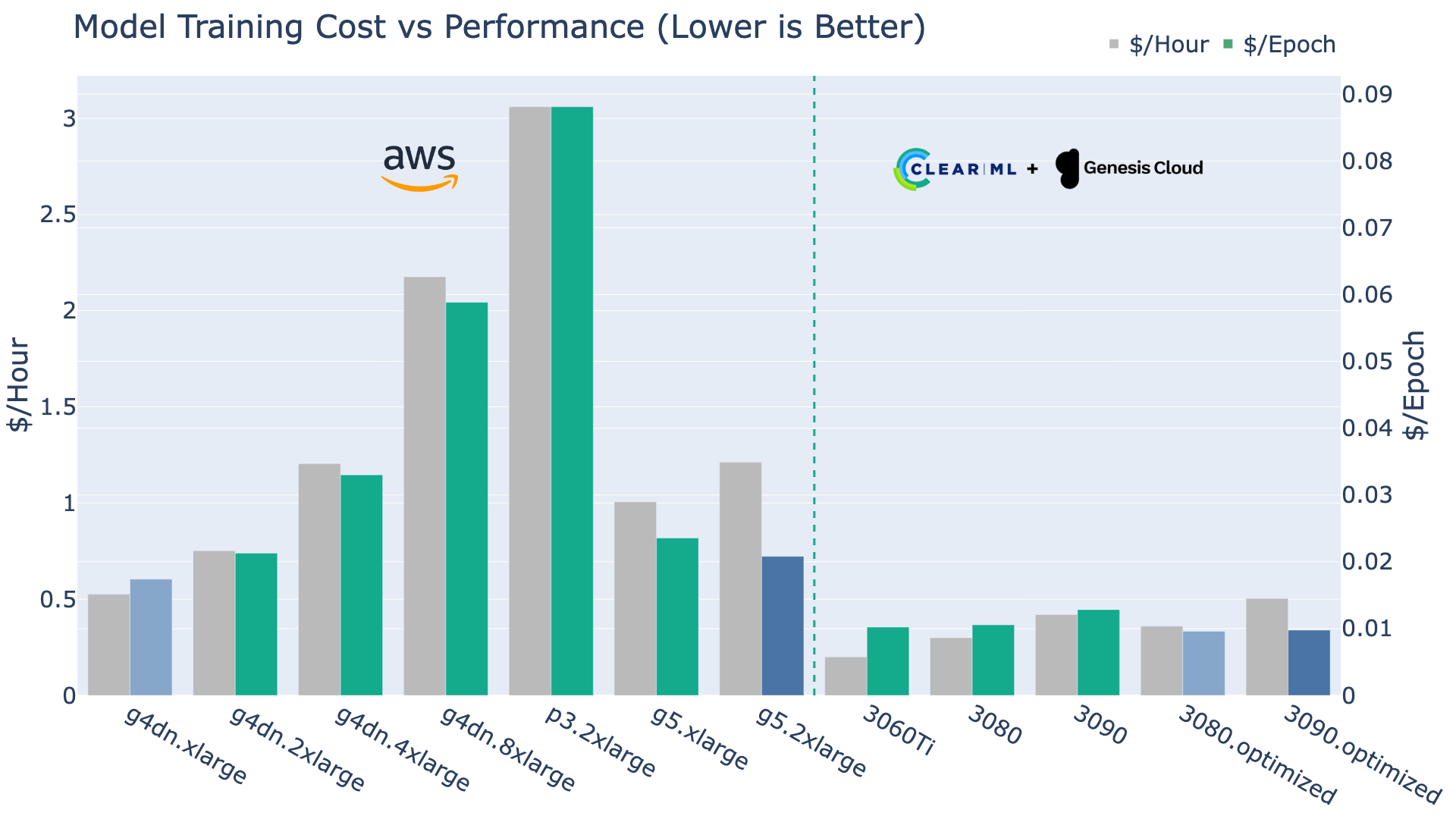
自然,这就是情况发生变化的地方。首先,基于V100的已停产的P3机器比其年轻的同类产品既慢又贵,这体现在数据上:P3 V100效率非常低!
g4dn系列在g4dn.2xlarge及以上版本中迅速开始失去成本效益。从那时起,转用更昂贵但更高效的g5机器可能在财务上更具意义。
在ClearML方面,尽管3060Ti是迄今为止最便宜的,但它不一定是您这里的最佳选择。标准3080和3090机器的CPU瓶颈也在这里表现为效率低下。
然而,这些显卡的内存和CPU优化版本表现出色!优化的3080和优化的3090是训练YOLOv8模型最具成本效益的方式。
消费级GPU可以与Spot实例竞争?!
即使我们将AWS Spot实例的成本效率进行比较(Spot实例有非常明显的权衡,见上文),消费级GPU仍然提供了具有吸引力的价值。请注意,在这张图中,我们比较的是瞬时性Spot实例定价与ClearML的按需定价。它们甚至能在同一级别竞争,这相当令人印象深刻。
较小的训练任务
请记住,此基准测试旨在针对具有大图像的大型训练任务,这些任务可以充分利用更昂贵GPU更高的显存。如果您的数据集要小得多,图像也小得多,那么结果可能对您来说就不一样了。
除此之外,较小的训练任务通常花费的时间也较短。考虑到设置机器、安装环境、拉取数据和开始训练每台机器都需要花费几分钟,您也应该将这些固定成本考虑进去!在安装了10分钟的软件包后,训练5分钟而不是8分钟,对于昂贵的GPU来说并不是一个好的用例!在这种情况下,像3060Ti这样成本最低的显卡仍然是一个非常好的选择。
结论
对于深度学习工作负载来说,消费级GPU是一个非常有趣的选择。如果您只需要微调预训练模型或在中小型数据集上训练较小规模的模型,那么它们实际上是最具成本效益的选择。
理想的解决方案是购买这些显卡并自行运行,因为它们是现成的。但在此之外,Genesis Cloud是您按需获取这些GPU的最佳选择,而ClearML则使在其上调度任务变得容易,并提供更低的价格。
如果您需要从头开始训练大型模型,例如LLM或其他大型Transformer模型,并使用巨大数据集,AWS仍然提供比最佳消费级显卡强大得多的A100等显卡,消费级显卡无法望其项背。此外,如果您不赶时间,也不介意中断,AWS Spot实例的价格仍然是最便宜的选择。
无论您决定如何,ClearML都开箱即用地支持本地或云、Spot或按需计算!
| 机器类型 | 每Epoch美元(成本效率) |
| ClearML RTX 3060Ti | 0.0102 |
| ClearML RTX 3080 | 0.0106 |
| ClearML RTX 3090 | 0.0128 |
| ClearML RTX 3080(内存和CPU优化) | 0.0096 |
| ClearML RTX 3090(内存和CPU优化) | 0.0098 |
| AWS p3.2xlarge | 0.0881 |
| AWS g4dn.xlarge | 0.0174 |
| AWS g4dn.2xlarge | 0.0213 |
| AWS g4dn.4xlarge | 0.0330 |
| AWS g4dn.8xlarge | 0.0588 |
| AWS g5.xlarge | 0.0235 |
| AWS g5.2xlarge | 0.0208 |
后续步骤
请告诉我们您希望我们考察哪些机器!我们列表上的第一个是A100,看看它在成本效益方面表现如何。
我们也很想测试除了YOLOv8以外的更多模型,例如LLM Transformer模型,看看不同模型架构如何改变效率。
最后,我们期待看到新一代消费级GPU的表现,即将推出的RTX 4090看起来绝对是一台巨兽。
