使用 ClearML Data 构建全自动再训练循环
好的,所以你想创建一个全自动的再训练循环,设置一次就可以几乎忘记它的存在。我们该从何开始呢?!

计划
一个常见的再训练循环可能看起来像这样
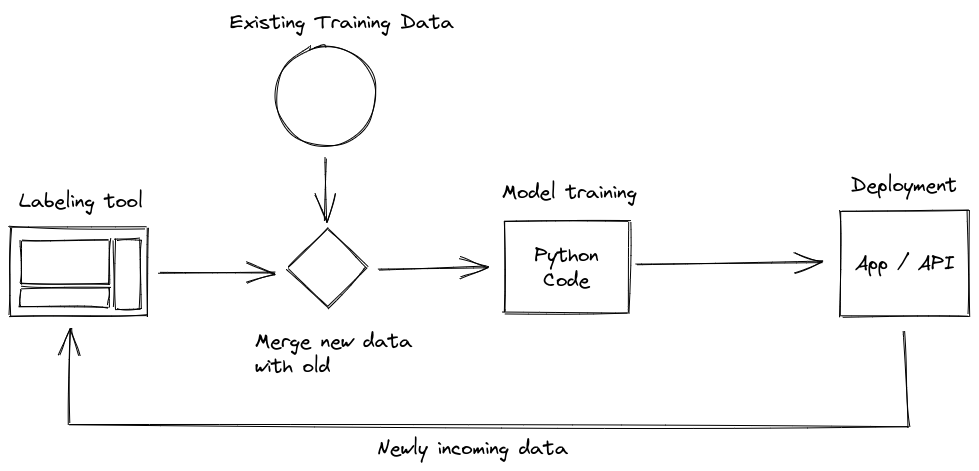
有一个标注工具可以生成新标注的数据。这些数据随后需要与已有的标注数据主体合并,然后再进行预处理。最后,这些数据就可以用来训练机器学习模型。如果你想要更高级一点,模型还需要经过评估,并且在性能良好时进行部署。
这些步骤中的每一个都可能因人为错误而出错,特别是如果数据没有被追踪,就很难追溯是哪个模型在哪些数据上训练的。这就是数据版本控制的作用所在。
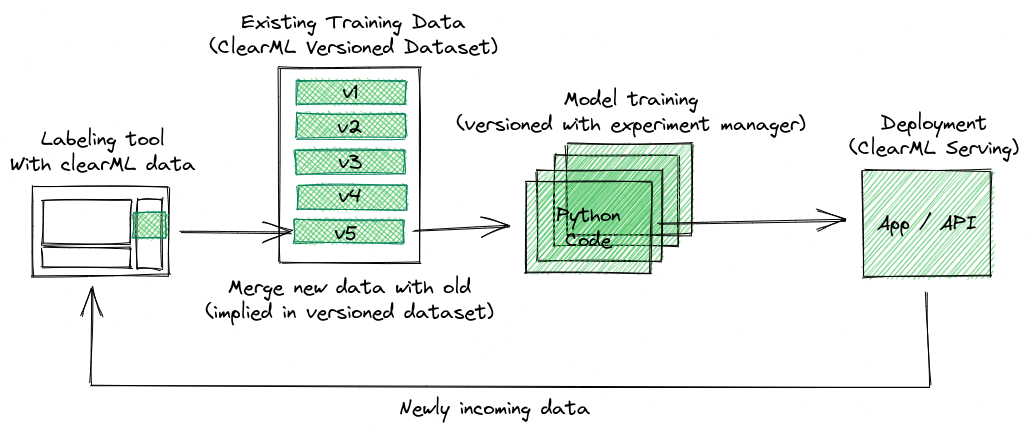
这篇博文的计划是从数据最初被标注时就开始进行版本控制。每当有人完成一些新标注时,我们就会为数据集创建一个新版本。然后,当检测到新的数据集版本时,可以自动触发预处理任务,进而启动一次再训练运行。那么,让我们开始吧!
用例
使用物联网传感器数据,我们可以尝试预测房间在任何给定时刻是否有人占用。数据基于此 Kaggle 数据集:https://www.kaggle.com/datasets/kukuroo3/room-occupancy-detection-data-iot-sensor。
包含的传感器有
- 温度
- 湿度
- 光照
- 二氧化碳
- 湿度比
每个传感器每分钟都有一个测量值,我们可以将每分钟标记为一个二元类别:房间有人占用,或无人占用。
鸣谢:https://www.kaggle.com/code/kukuroo3/start-code-base-eda
与标注工具集成
任何连续的再训练循环都或多或少会包含一个标注工具,前提是我们讨论的是监督式机器学习问题。这可能是人机交互最多的组件,但这并不意味着我们可以放松自动化。
这只是一些轶事证据,但很多项目似乎倾向于使用自己的定制标注工具,这意味着我们可以尝试将 clearml data 直接集成到代码中!出于本博文的目的,我们将使用一个简单的结构化数据标注工具,叫做 Time Series Labeler。它整洁的代码库可以作为一个很好的例子,说明如何与你自己的工具集成。
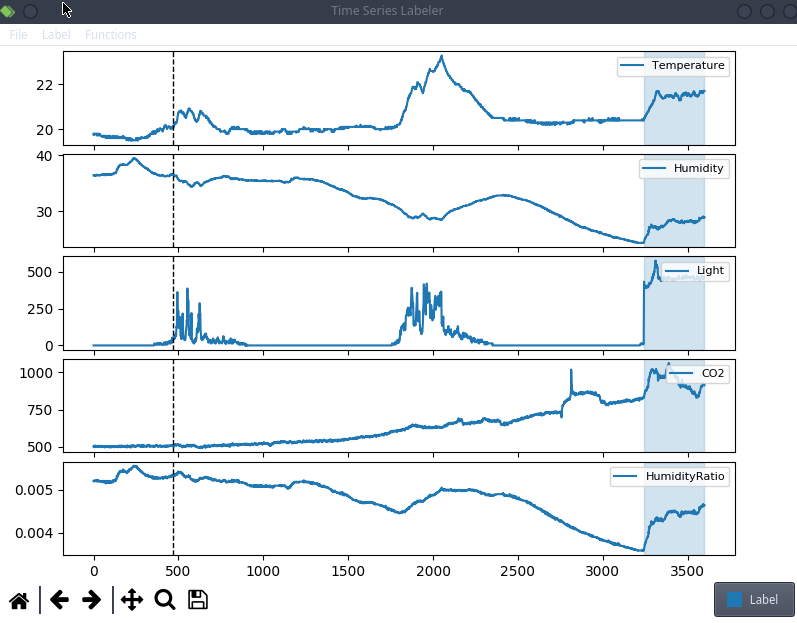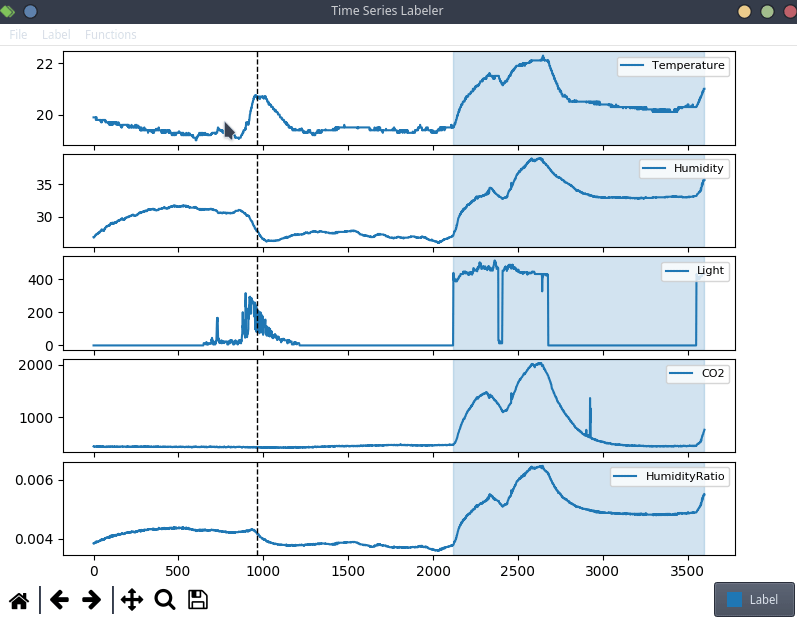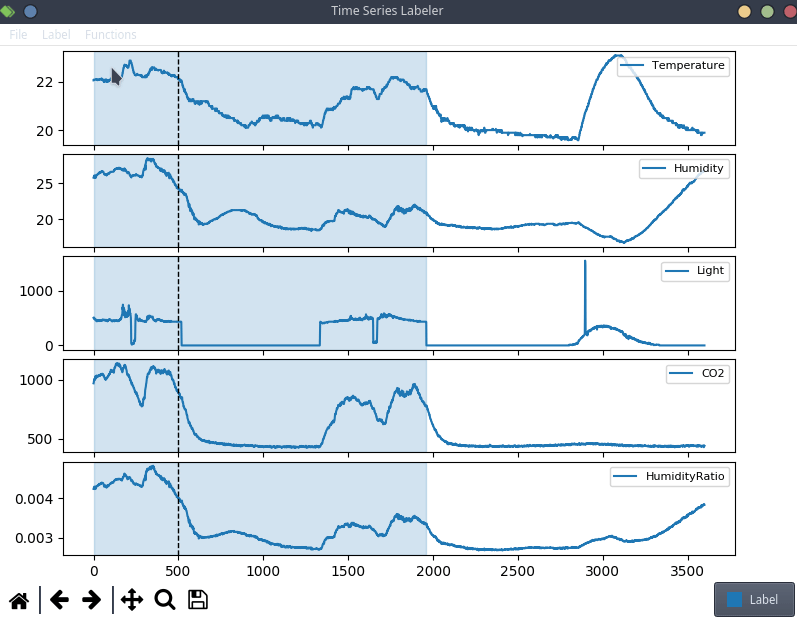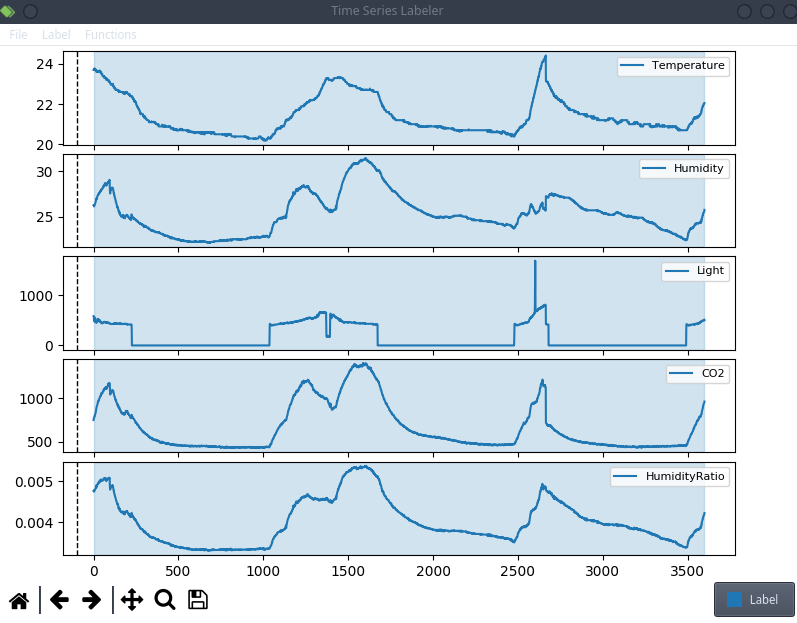
理想情况下,我们希望将数据集版本管理自动化,使其成为常规标注工作流程的一部分,因此我们可以将一个“上传”按钮集成到我们选择的标注工具中,点击同步按钮就会将所有新标注的文件作为新的数据集版本上传。此按钮的具体实现高度依赖于你最终使用的具体标注工具,但 clearml data 的代码很可能是相同的。
Clearml data 持续标注工作流程
当按下上传按钮时,我们首先要做的就是获取(不是下载!)我们想要添加新标注数据的最新数据集版本的元数据。如果数据集尚不存在,我们想要创建它。
dataset = Dataset.get(
dataset_project=CLEARML_PROJECT,
dataset_name=CLEARML_DATASET_NAME,
auto_create=True,
writable_copy=True
)auto_create 参数会在该项目中不存在同名数据集时创建一个数据集。writable_copy 参数实际上会执行以下操作的等效功能:
latest_version = Dataset.get(
dataset_project=CLEARML_PROJECT,
dataset_name=CLEARML_DATASET_NAME
)
new_version = Dataset.create(
dataset_project=CLEARML_PROJECT,
dataset_name=CLEARML_DATASET_NAME,
parents=[latest_version]
)创建一个基于该数据集已有的最新版本的新数据集版本。
现在我们可以添加所有已更改的文件,如果标注工具只列出了更改的文件,那就太好了!但如果不是,你可以直接添加数据集的根文件夹,clearml data 会为你处理重复项并找到差异。
dataset.add_files(path=save_path)然后我们可以完成这个数据集版本并上传它!
dataset.finalize(auto_upload=True)![]()
更进一步
按钮本身仍然是一个相当手动的过程。它的优点在于标注者可以自主决定何时上传以及上传什么,但他们仍然需要时不时地记住点击按钮。另一种选择是,如果标注工具跟踪了已完成的文件,就可以自动添加和上传每个完成的文件。
上传在后台进行,因此可以调用以下代码来启动它:
dataset.add_files(path=done_file_path, dataset_path=/path/of/file/relative/to/dataset/root)
dataset.upload()由于我们现在添加的是单个文件,提供 dataset_path 也就有意义了,它指定了你希望文件最终位于数据集结构的哪个位置。通常,这将与本地路径相同,但这允许你定义一个与标注工具结构不同的数据集结构。
然后,只有当标注工具被自愿关闭时,我们才可以在工具退出之前完成数据集(这是一个简短的过程)。
# A keyboard interrupt is of course for a CLI tool, a GUI tool will have its own
# way of gracefully handling a shutdown
try:
# Run tool here
except KeyboardInterrupt:
dataset.finalize()
# Example for PyQT/Pyside GUI code
class YourMainWindow(QtGui.QMainWindow):
(...)
def closeEvent(self, *args, **kwargs):
super(QtGui.QMainWindow, self).closeEvent(*args, **kwargs)
dataset.finalize()探索数据集版本
现在我们来看一下 ClearML UI,可以看到经过几次标注会话后,我们的数据集已经有了几个新版本。
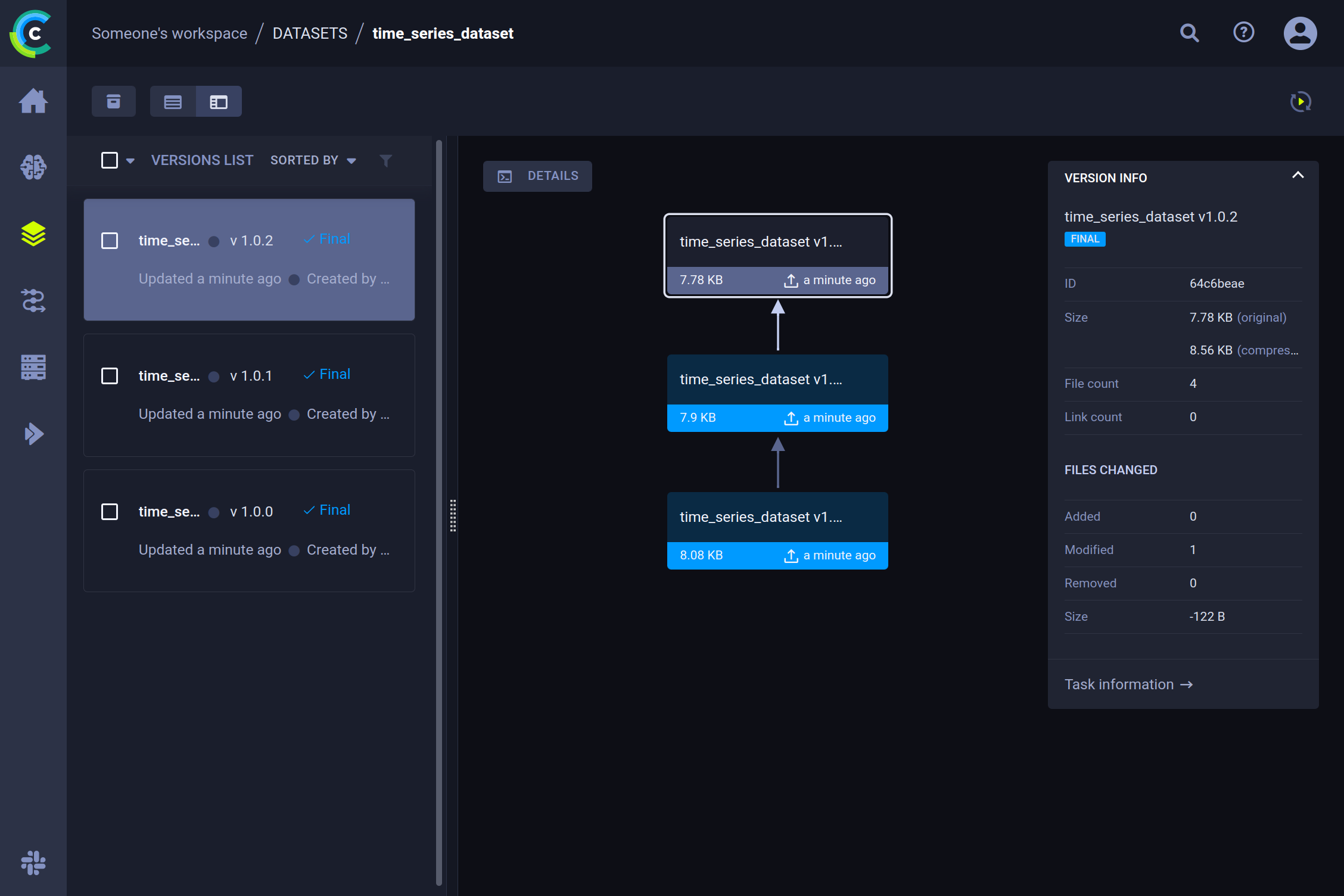
详情
选择特定版本后,我们可以在右侧窗格中看到最重要的详细信息(例如,添加、删除或修改的文件数量、增量大小等)。要获取有关内容的信息,请点击详情按钮。这将提供数据集内容的概览,以及内部数据的预览和用于调试的控制台日志。
添加自定义图表或表格
当我们查看预览选项卡时,可以看到系统为我们的 CSV 文件生成了自动预览,这很棒!但我们可以做得更多。使用数据集管理器的妙处在于,你可以向数据集添加各种额外信息。例如,我们可以绘制前几个 CSV 文件的图表,然后将它们记录到数据集中。结果图表将显示在预览选项卡中。
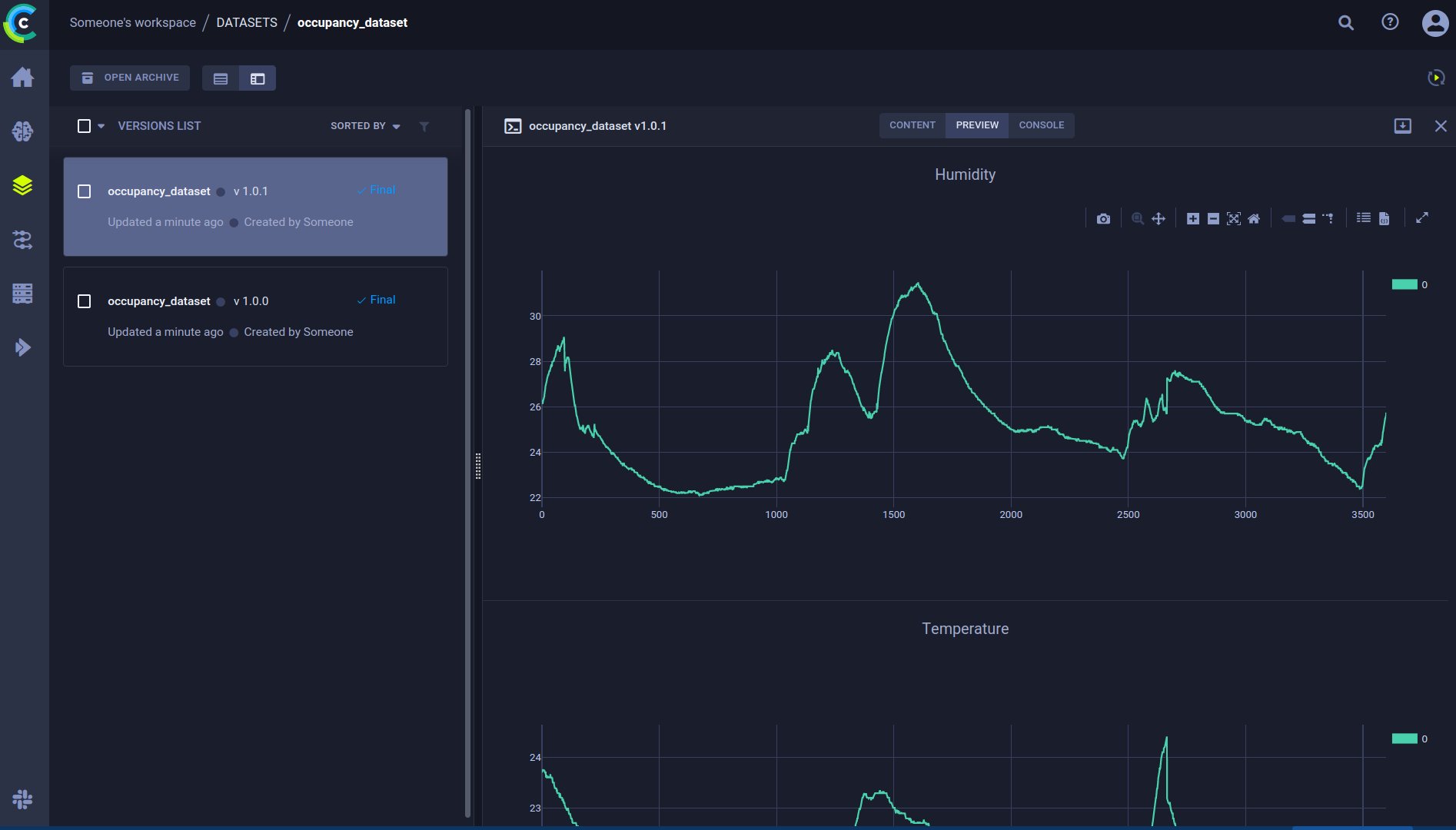
dataset.get_logger().report_scatter2d(
title=column_name,
series=file_name.replace('.csv', ''),
scatter=np.stack([df.index, df[column_name].to_numpy()], axis=1),
iteration=0
)添加标签
使用标签是保持事物井井有条的一种非常方便的方式。添加标签可以让你轻松地对它们进行排序或查询。这样做将只显示你想要看到的版本。标签可以从 UI 添加,也可以从代码添加。我们将在博文后面看到这对于再训练循环的后期阶段有多大用处。
设置训练代码
使用 ClearML 实验管理器,我们可以轻松设置训练脚本并将其连接到我们使用的数据集。
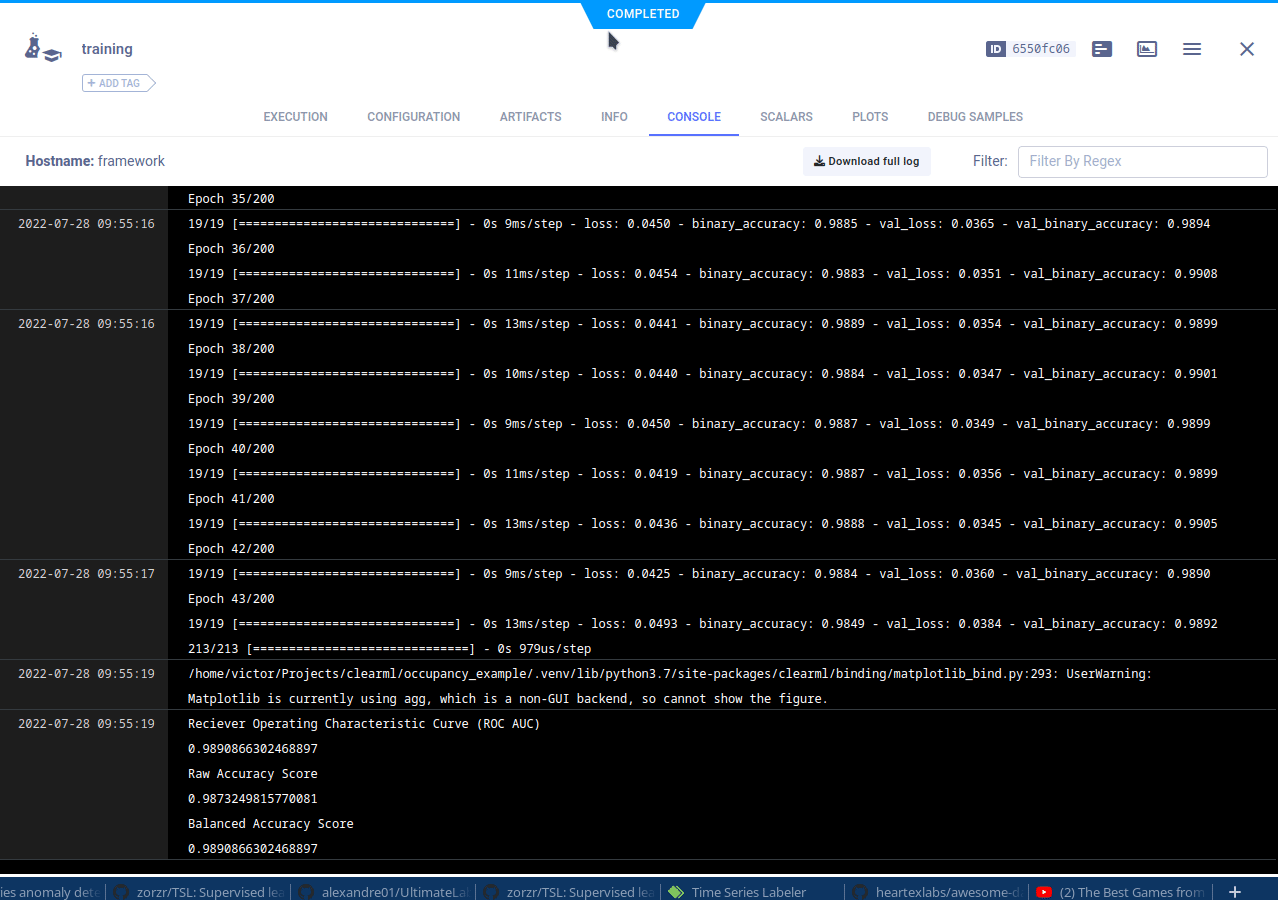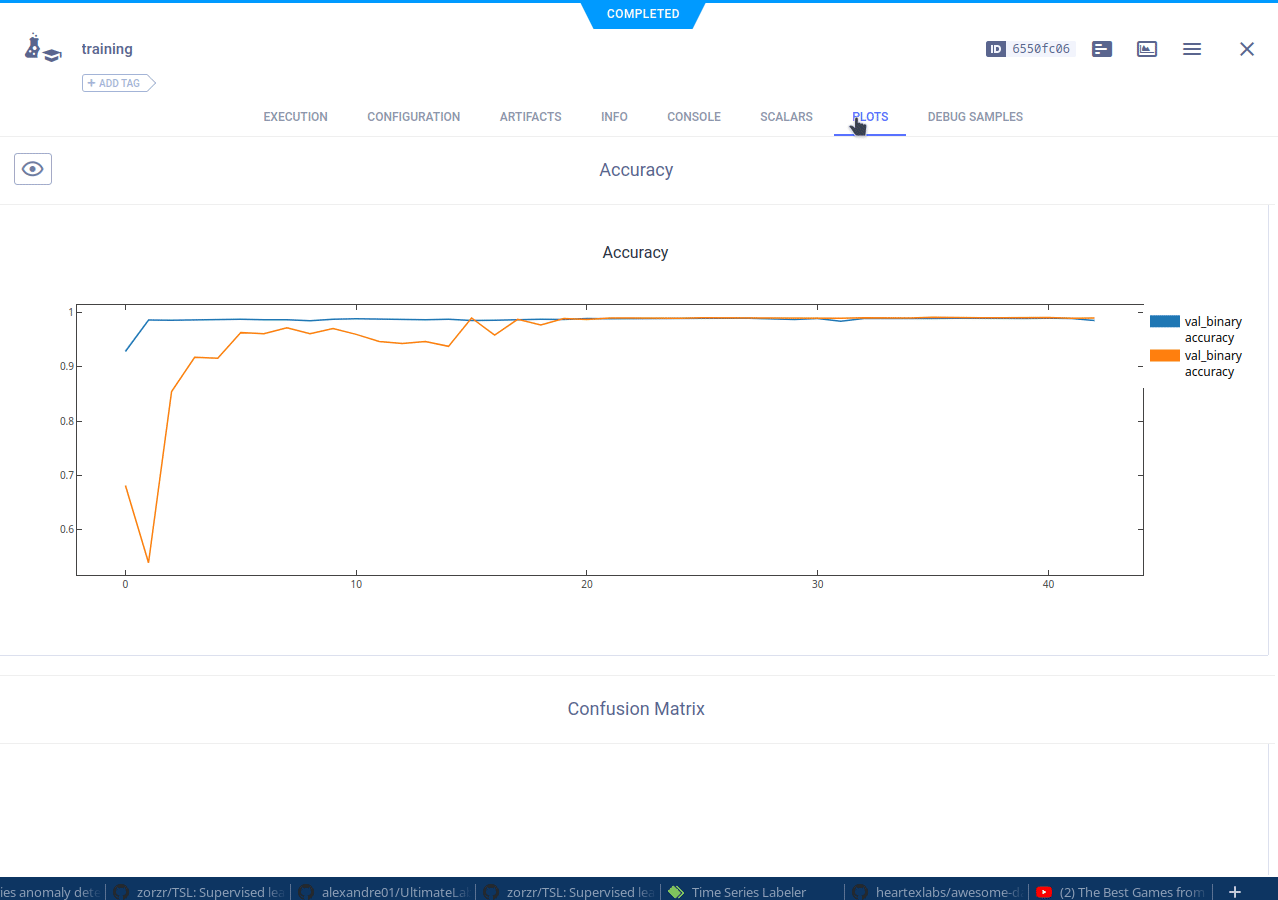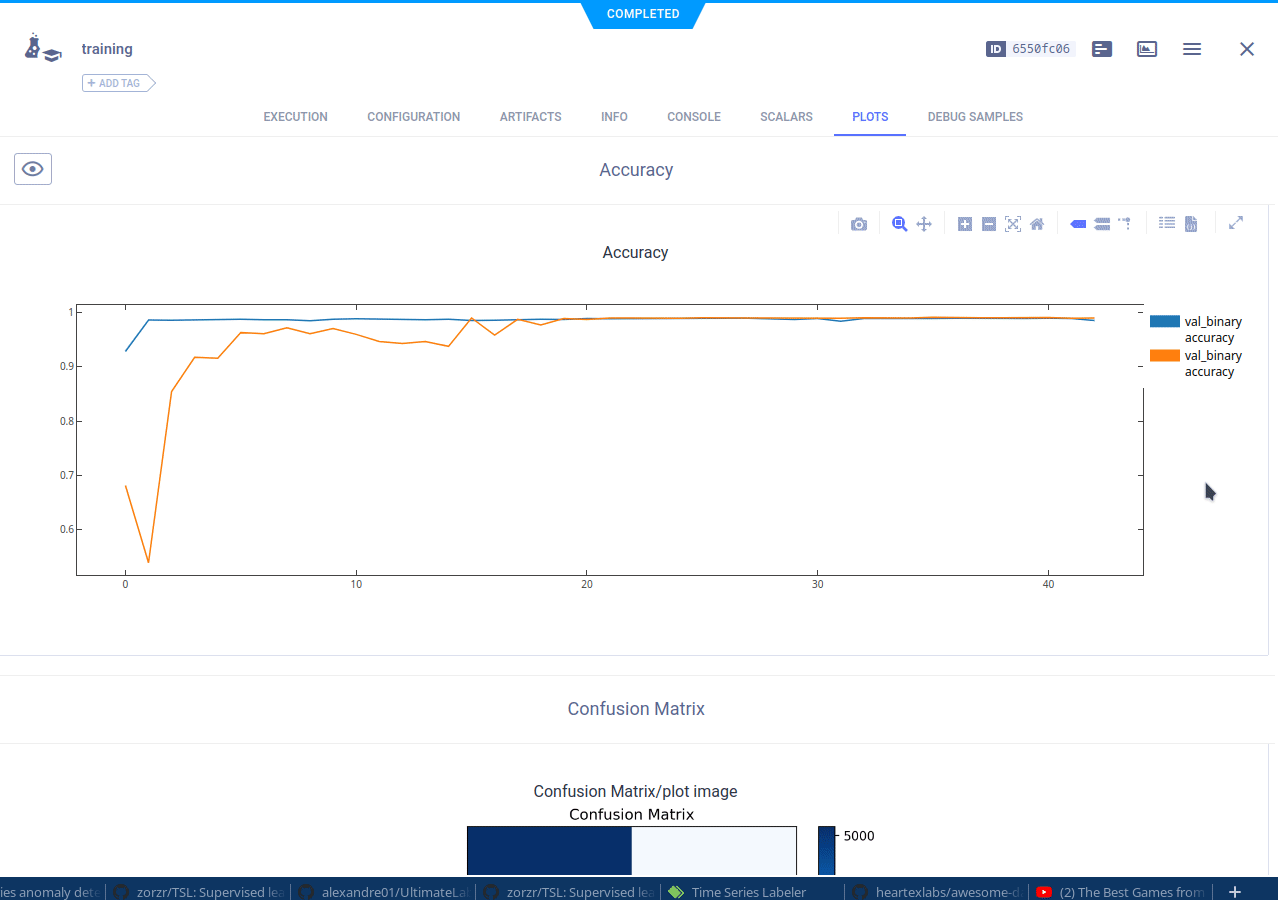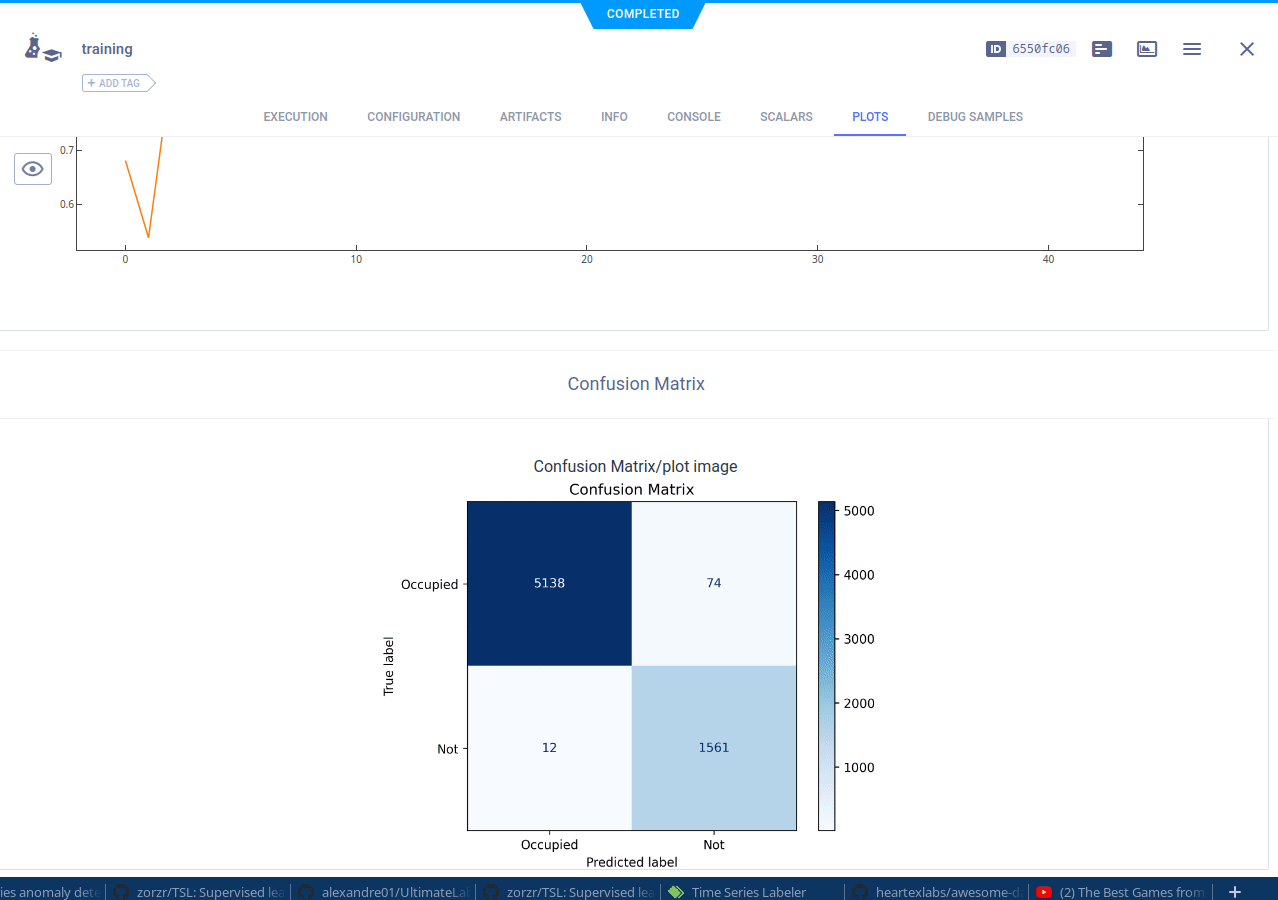
让我们分解一下,为了训练数据,我们首先需要获取一个本地副本。
获取数据集版本的本地副本
获取数据集的本地副本很容易,只需使用 Dataset.get() 方法获取数据集,并提供数据集名称、项目、ID、标签或这 4 个属性的任意组合。这将为你提供一个数据集对象,它实际上是一个持有数据集元数据的代理对象。然后,你必须使用 .get_local_copy() 方法实际下载它,就可以开始了!
from clearml import Dataset, Task
import config
# Initialize the experiment manager
task = Task.init(
project_name='dataset_blogpost',
task_name='training'
)
# Connect the parameters, so we can later change them
task.connect(config)
# Get the data and process it into a dataframe
# Getting the data will actually get a metadata object that represents
# that dataset. It does not actually download these files yet in case
# you just need some metadata like a list of files.
DATASET_PROXY = Dataset.get(dataset_id=config.CLEARML_DATASET_ID)
# Calling .get_local_copy() WILL download the data, to a local cached folder
# and return the path. This folder is read-only.
# Use get_local_mutable_copy() instead to get a mutable version and to choose
# in which folder to download it yourself.
DATA_PATH = DATASET_PROXY.get_local_copy()
# Concat all csv files into 1 dataframe
frames = []
for csv in os.listdir(DATA_PATH):
frames.append(pd.read_csv(DATA_PATH / csv))
raw_data = pd.concat(frames)
# ... Training code ...连接参数(剧透:这样我们以后就可以更改它们)
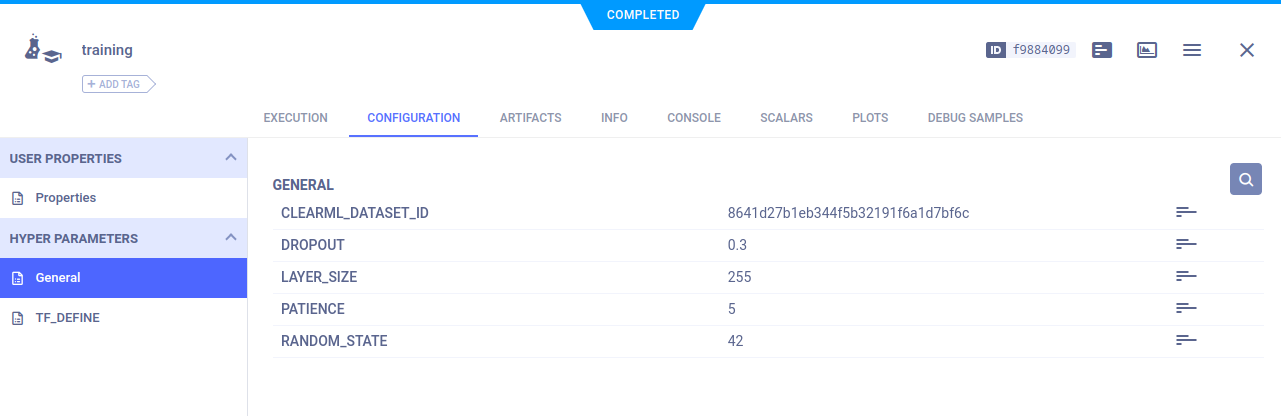
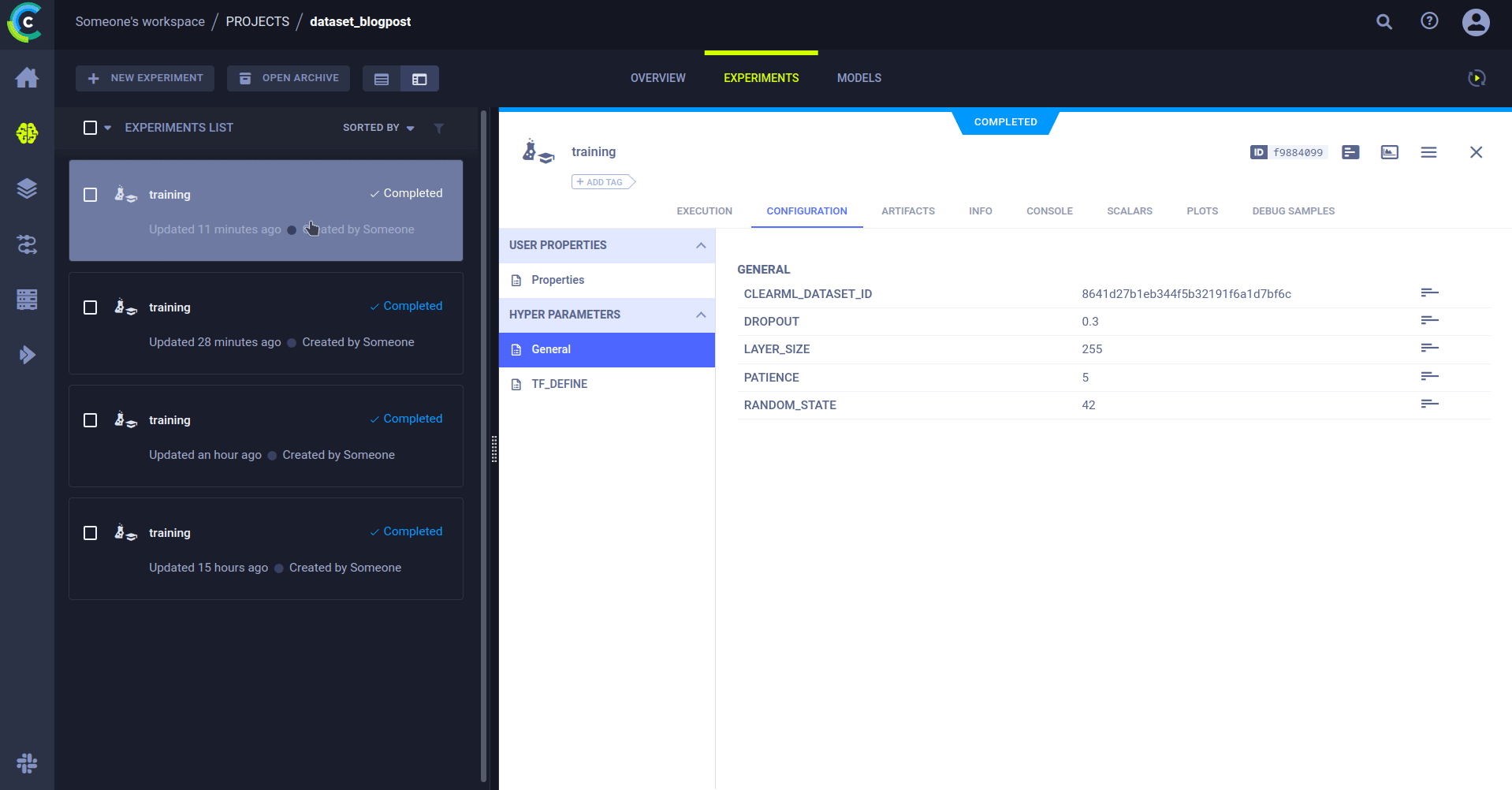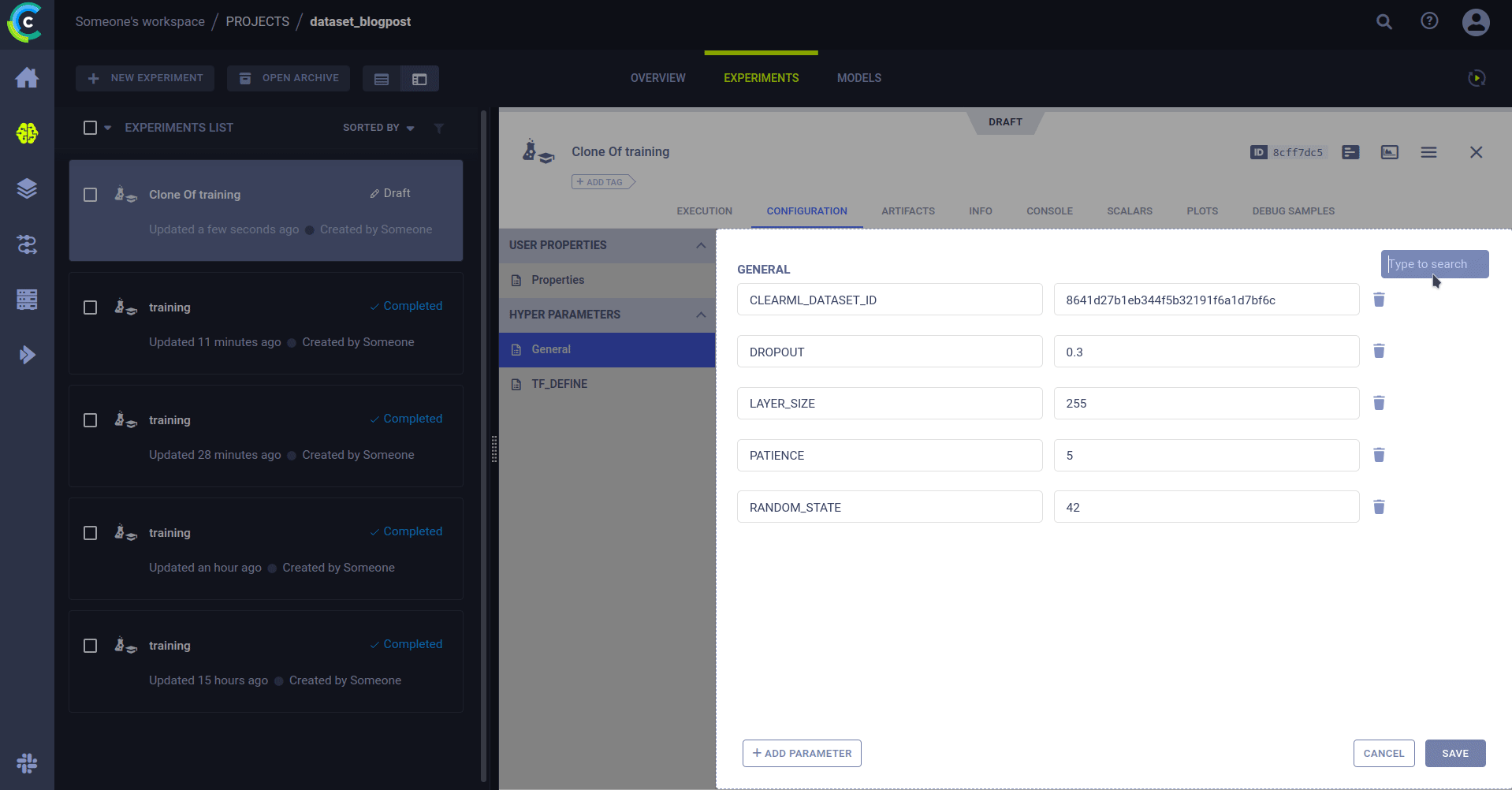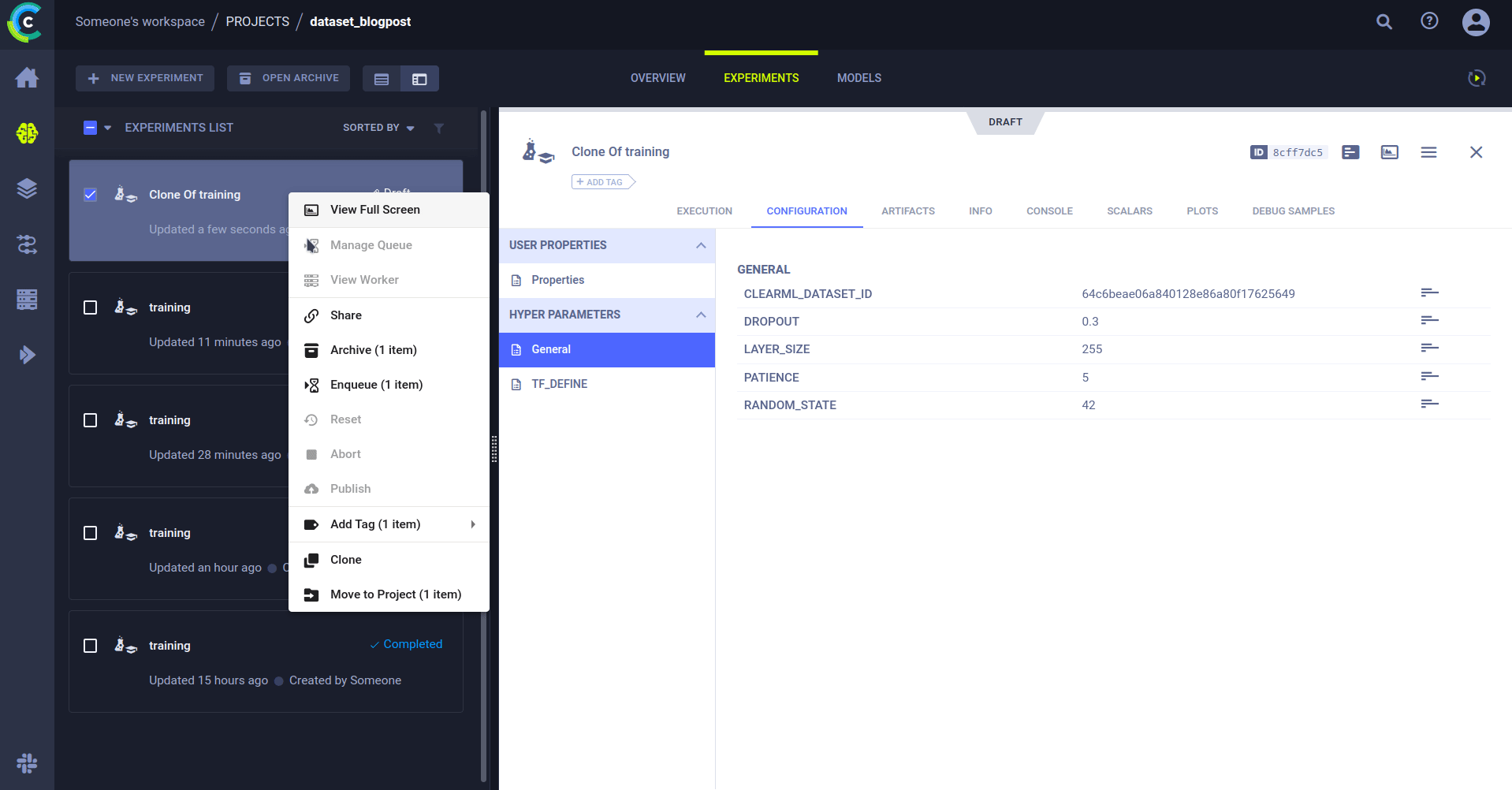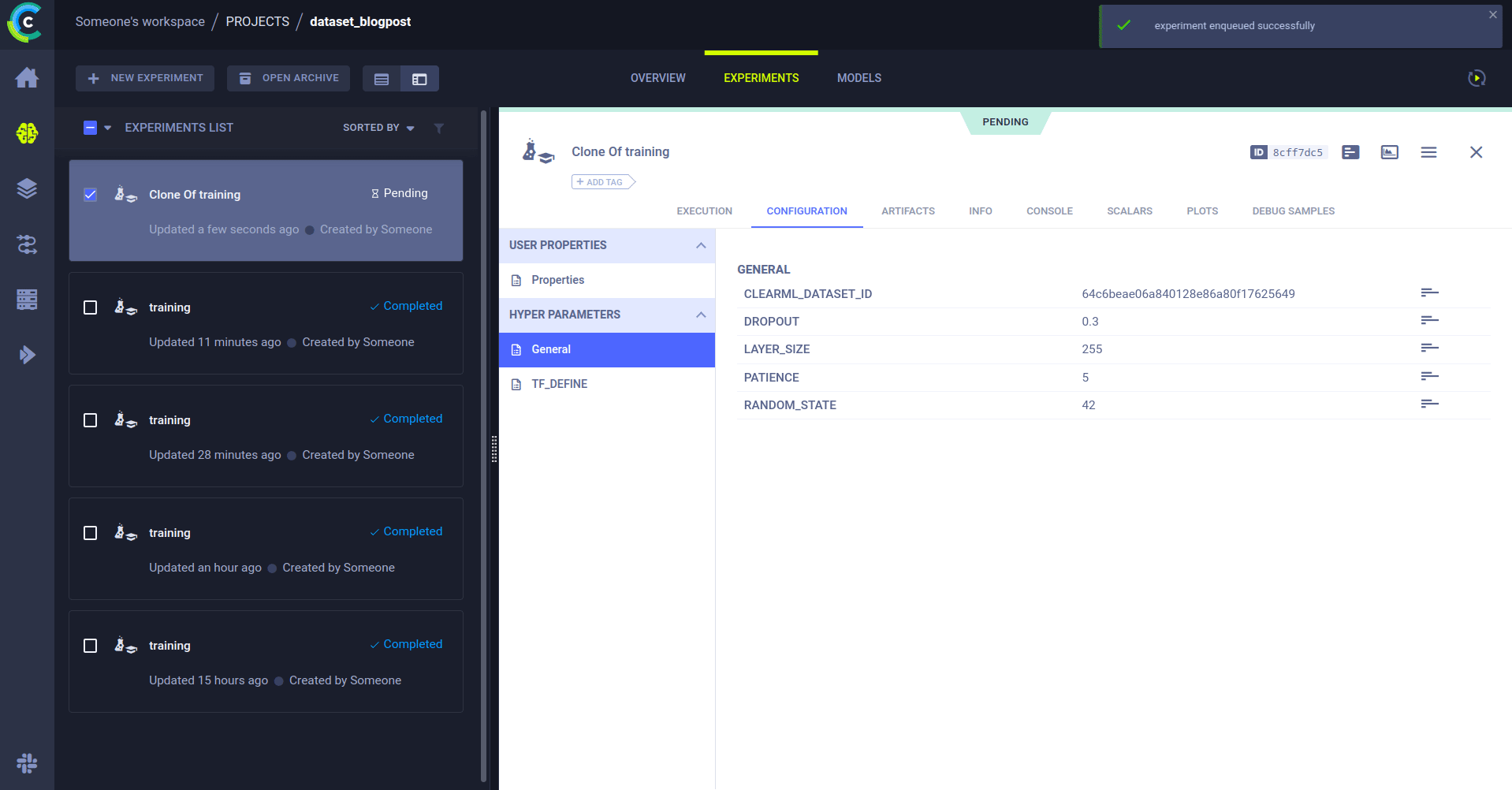
在我们当前的设置中,训练代码唯一需要知道的信息是数据集的 ID。这也很容易可以是数据集名称、项目和标签的组合,但目前我们将重点关注 ID。当然,任何其他可能有趣的参数,例如训练超参数,也可以添加进来。
通常,一个好的做法是将所有配置选项集中存放在某个地方,比如全局字典或配置文件。在这种情况下,我们有一个看起来像这样的 config.py 文件:
# ClearML parameters
CLEARML_DATASET_ID='8641d27b1eb344f5b32191f6a1d7bf6c'
# Model parameters
RANDOM_STATE=42
LAYER_SIZE=255
DROPOUT=0.3
PATIENCE=5在整个模型代码中,我们可以使用这些参数,以便轻松更改和实验。
model = keras.Sequential ([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(config.LAYER_SIZE, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=config.DROPOUT),
layers.Dense(config.LAYER_SIZE, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=config.DROPOUT),
layers.Dense(1, activation='sigmoid')
])告诉 ClearML 它也应该跟踪这些参数非常容易:
task.connect(config)PS:如果你正在使用 argparser、hydra、click 或任何其他受支持的框架,你的配置很可能会被自动捕获,无需使用 task.connect!
这使得在界面中清楚地显示参数是什么,并且更容易根据它们比较实验。但我们想要跟踪参数还有一个更好的理由:自动化。
克隆实验
为了实现全自动流水线,我们需要解释一下克隆。ClearML 已经捕获了在另一台机器上重现实验所需的一切。这包括 Git 信息、未提交的更改、已安装的软件包等。
还有一个使用 ClearML agent 的整个编排组件。它们的具体工作方式超出了本博文的范围,但你可以观看这个简短的 YouTube 视频了解详情。总结来说(TL;DR):你可以在任何(远程)机器上运行 ClearML agent,它将为你运行实验,包括那些被克隆的实验。
但是我为什么想要重新运行一个现有的实验呢?因为你可以更改参数!还记得上一节中我们强调跟踪参数有多么重要吗? 当你克隆一个实验时,你可以更改它的任何参数。当 agent 运行更改后的实验时,它会将新的参数值注入到原始代码中。因此,它将像新值一直存在一样运行。
就这样,我们就可以在不同的数据集上重新运行相同的代码。只需编辑参数中的数据集 ID,然后将其发送给 agent 执行即可。
新数据集到来时实现再训练循环的自动化
设置一个触发器,当新版本数据进来时(可能根据标签过滤),启动训练实验的新克隆。ClearML 在内部跟踪系统中发生的事件。新的数据集版本进来可以触发另一个 ClearML 组件启动。
from clearml.automation import TriggerScheduler
# create the TriggerScheduler object (checking system state every minute)
trigger = TriggerScheduler(pooling_frequency_minutes=1.0)
# Add trigger on dataset creation
trigger.add_dataset_trigger(
name='retrain on dataset',
# You can also call a function that would get the latest experiment version
# instead of hardcoding the training task ID
schedule_task_id='<training_task_id>',
task_overrides={'General/CLEARML_DATASET_ID': '${dataset.id}'},
# What to trigger on
trigger_project='dataset_blogpost',
trigger_on_tags=['Production'],
)
# start the trigger daemon (locally/remotely)
# trigger.start()
trigger.start_remotely()就是这样!现在,当一个新版本的数据进入项目 dataset_blogpost,并且该项目带有标签 Production 时,触发器将克隆你指定的 ID 的任务,并将 CLEARML_DATASET_ID 参数覆盖为触发该事件的数据集的 ID。
克隆的任务将被调度,然后由 ClearML agent 运行。它将在实验列表中创建一个新的实验,包含实时更新的标量、图表、控制台日志等。
后续步骤
克隆任务、编辑参数并重新启动的想法不仅限于实验。流水线也可以被克隆和编辑。因此,很容易想象一个复杂的预处理 → 训练 → 评估流水线,例如由带有“Production”标签的新传入数据集触发。然后,该流水线可以生成一个模型文件,进而可以使用 ClearML Serving 触发金丝雀部署。利用这些概念,你可以构建一个真正令人印象深刻的再训练循环!
