大语言模型 (LLMs) 现在已经发展到具备简化和/或增强广泛工作的能力。
随着企业考虑在其员工或应用程序中广泛采用 LLMs,务必注意虽然基础模型提供了逻辑和理解命令的能力,但它们缺乏业务的核心知识。这就是微调成为关键步骤的原因。
本博客解释了如何通过使用您自己的组织数据微调现有开源模型,从而为您的用例获得性能最佳的 LLM。
创建数据集
假设一家公司希望构建一个知识库,以帮助客户支持更快、更准确地回答查询。数据集可以从现有支持工单或聊天记录中创建,这些记录可以被解析并输入到向量数据库中。
Q: Does clearml-task need requirements.txt file? A: clearml-task automatically finds the requirements.txt file in remote repositories. If a local script requires certain packages, or the remote repository doesn't have a requirements.txt file, manually specify the required Python packages using --packages "<package_name>", for example --packages "keras" "tensorflow>2.2" Q: How can you use clearml-session to debug an experiment? A: You can debug previously executed experiments registered in the ClearML system on a remote interactive session. Input into clearml-session the ID of a Task to debug, then clearml-session clones the experiment's git repository and replicates the environment on a remote machine. Then the code can be interactively executed and debugged on JupyterLab / VS Code. Note: The Task must be connected to a git repository, since currently single script debugging is not supported. In the ClearML web UI, find the experiment (Task) that needs debugging. Click on the ID button next to the Task name, and copy the unique ID. Enter the following command: clearml-session --debugging-session <experiment_id_here> Click on the JupyterLab / VS Code link, or connect directly to the SSH session. In JupyterLab / VS Code, access the experiment's repository in the environment/task_repository folder.
数据集需要干净,而数据摄取可能是一个具有挑战性的步骤。然而,借助 ClearGPT 等工具,预构建的向导使该过程变得简单,并且对于将来的更新来说是可复制的。ClearGPT 是 ClearML 面向企业的低代码、安全、端到端 LLM 平台,具有数据摄取、训练、质量控制和部署功能。
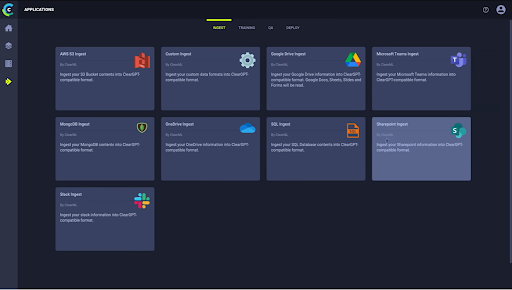
选择您的数据摄取向导(或构建您自己的向导)
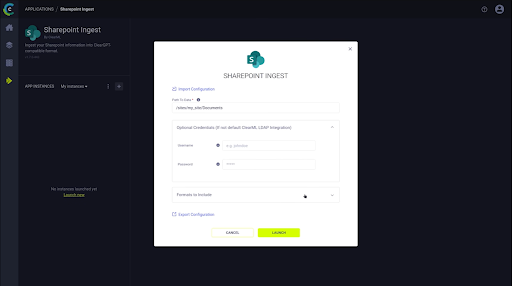
输入必要的文件路径和参数
微调模型
对于大多数业务用例而言,准确性是不可妥协的。使用那些给出方向正确但不具体的泛化模型并非理想选择。像 GPT-4 这样的模型非常适合需要从广泛数据中获取推荐或答案的消费者。虽然它们可能满足公司对 LLMs 的初步好奇心,甚至可以作为可行的 POC,但就其现状而言,这些模型无法为深入的、特定领域的知识请求提供正确的答案。
这些模型不仅会提供不准确的结果,而且庞大且笨重。在尝试提取最佳响应时,其知识库的巨大规模很容易导致延迟(以及随之而来的高昂 token 成本)。

与普遍的看法相反,使用 Embedding 和 VectorDBs (RAB) 丰富答案并不能解决问题。当检索过程成功时(即查询 VectorDB 获取答案/文档),会提供良好的参考信息,但主要的注意事项是 VectorDB 结果缺乏控制。没有机制可以“选择”或“评分” VectorDB 中的不同条目。请关注未来的博文,了解如何添加控制并结合使用 VectorDBs。
如果常识告诉我们,针对特定用例的数据训练的模型会表现更好,那么就没有必要构建最大、最智能的模型。在 ClearML,我们提倡为每个特定用例构建最佳模型。在您的组织中运行多个“较小”(这是一个相对的术语,因为这些模型至少仍有数十亿甚至数百亿参数)的模型可以是一个高效且有效的选择。
在 ClearGPT 中,您可以轻松地将数据集应用于基础模型进行训练。
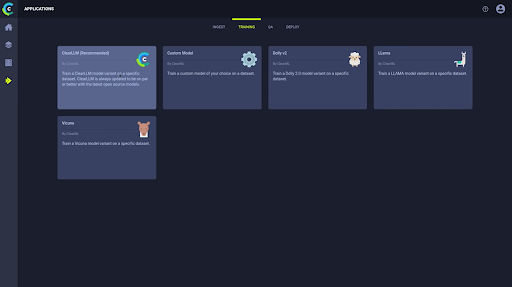
选择您的基础模型
选择您的基础模型
模型质量保证
LLM 与“标准”ML 模型之间的一个主要区别在于需要主动进行质量保证。大多数情况下,构建和训练 LLM 的数据工程师并非主题专家。由于 LLMs 的生成性质,让业务领域的利益相关者参与测试并就模型的准确性提供反馈(通过人类反馈的强化学习)至关重要。这些数据也应最新地反馈到模型微调过程中。ClearGPT 专为要求最苛刻的企业环境而设计,旨在革新您的业务绩效,帮助您的组织更智能、更快速地运行。
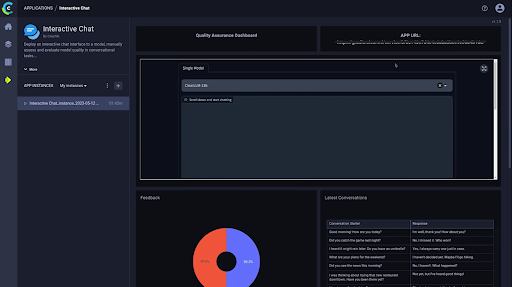
质量保证示例:一个捕获主题专家反馈的 Gradio 应用程序
部署模型
恭喜,您已成功为您的业务创建了一个可用的 LLM!您可以将模型嵌入到应用程序中或将其部署为 API。请记住将模型访问权限限制在适当的业务用户组内。ClearGPT 通过 SSO、身份验证和权限设置来促进这一点。ClearML 基于角色的访问控制将个体用户与数据集和模型关联起来,确保他们(以及他们使用的模型)只能访问他们有权限访问的数据。
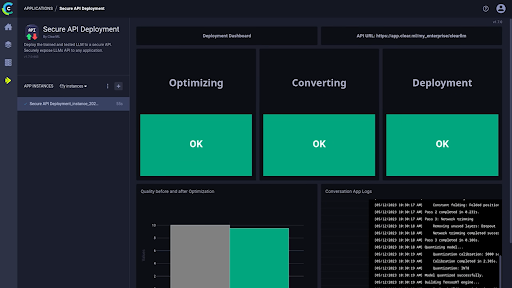
部署您的模型!
更小、更“精准”的 LLMs 更适合专业用例
LLM 基础模型前景广阔,使人工智能能够解决现实世界的问题。然而,对于需要领域特定知识的用例的企业而言,它们并非现成的解决方案。虽然可以在模型之上应用诸如提示工程等其他方法来管理输入和输出,但在您自己的数据上微调模型是更具可扩展性和可持续性的解决方案,它能让您的团队完全控制性能并获得更高的准确性。
如需与 ClearML 讨论如何在您的组织中实施生成式 AI,请访问 https://clearml.org.cn/cleargpt-enterprise。
