超参数优化简易指南。
太长不看;
- 现代优化是通过优化器和早期停止策略的组合来完成的
- 如果您想要一个简单但比随机搜索好得多的替代方案,请使用贝叶斯优化作为您的优化器。
- 使用 Hyperband 作为早期停止器以提高效率
- 注意不要将时间作为早期停止预算

网格搜索很容易,但效果不太好。随机搜索稍好一些,并且仍然易于使用。如果您愿意花一点时间了解贝叶斯优化的一些更有用的设置,您可以用更少的投入获得更多的产出(并且无需统计学博士学位)。
大多数高级优化器实际上由两部分组成:一个优化器和一个早期停止策略。
流行的超参数优化框架包括
- Optuna:提供广泛的优化器和他们称之为“修剪器”(早期停止器)。
- HpBandSter:以 BOHB 闻名,BOHB 是一种贝叶斯优化器,并使用 Hyperband 作为早期停止器。
这两者都可以在 ClearML 中使用,您可以在我们之前的博客文章中查看它们的用法,并在文档中此处查看详细信息。
选择优化器:只需使用贝叶斯优化。

优化器选项包括
网格搜索
切勿使用
随机搜索
如果您拥有几乎无限的计算资源、大量时间或非常高的维度数量,请使用此方法。不过,通常比网格搜索好得多。
贝叶斯优化
总的来说,如果您只想要一个开箱即用、比随机搜索好得多的替代方案,这是您的最佳选择。当您的优化预算(我们将在下文介绍)较小到中等时,这也是一个不错的选择。BO 被认为是超参数优化领域新算法的基准。
HpBandSter 使用他们自己的树状帕森估计器 (TPE) 变体,这基本上是您唯一的选择,但它是一个非常可靠的选择。
Optuna,另一方面,实现原始的 TPE 算法作为其贝叶斯优化选项。
然而,这些估计器将优化单个目标指标;如果您有多个目标需要优化,您可以查看 Optuna 的 MOTPE,它是 TPE 的多目标版本。
其他算法
然后在 Optuna 中还有其他更“研究性”的算法可以尝试,例如协方差矩阵自适应进化策略 (CMA-ES) 以及非常有有趣且直观的遗传算法,如非支配排序遗传算法 II (NSGA-II)。
这些非常有趣,但需要对实际底层算法有更多了解,并且在某些情况下会比 BO 效果更好,而在另一些情况下则更差。
然而,与从随机搜索转向 BO 相比,这种差异并不那么显著。
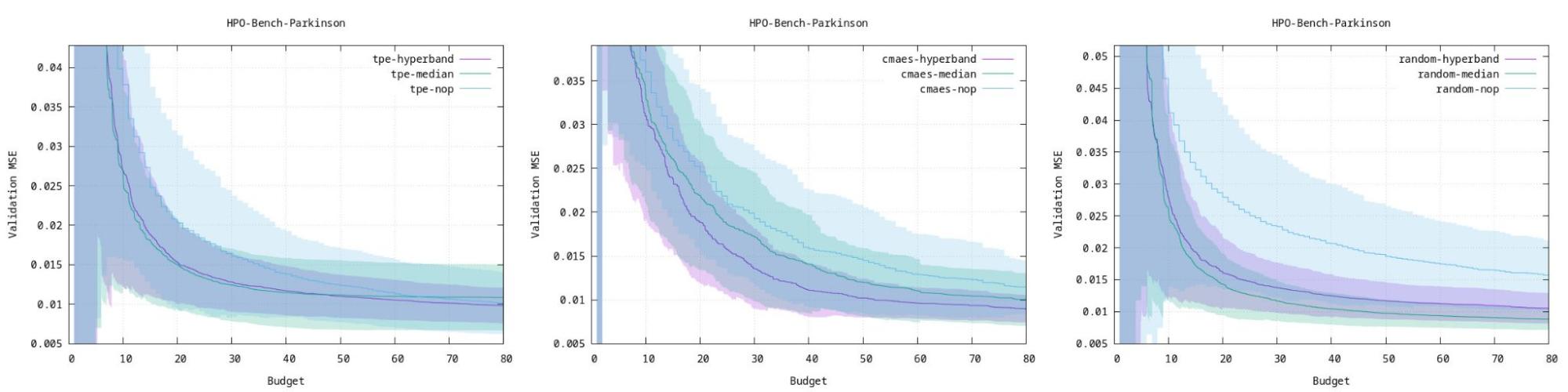
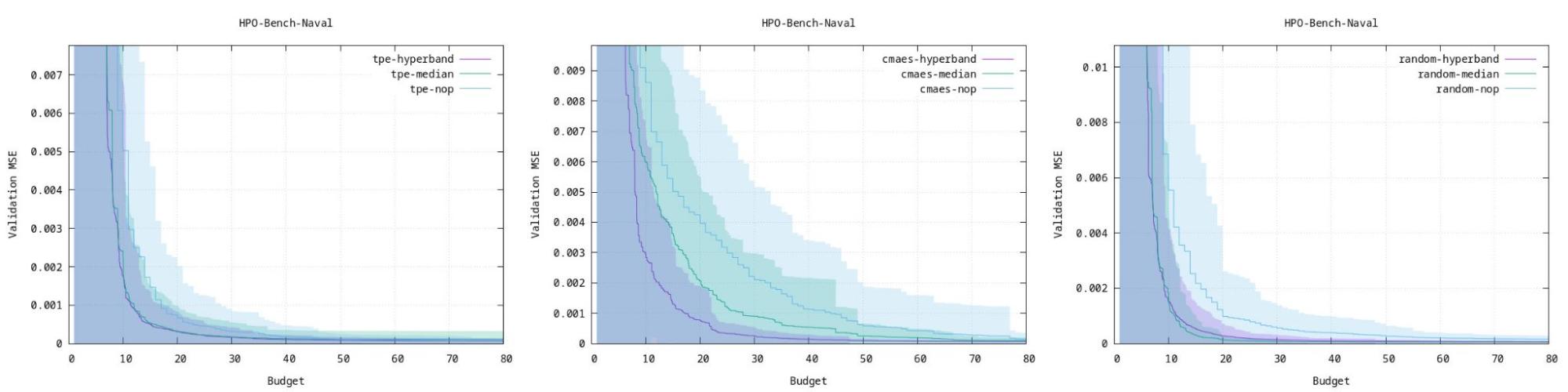
Optuna 有一个非常好的页面,他们在其中比较了 3 种算法在几种不同类型的 ML 工作负载上的基准测试。可以使用这些图表来估计哪种模型最适合您的应用程序。
早期停止:预算解释

为了不浪费时间,许多优化器都与早期停止机制相结合。这些机制旨在接收一定量的“预算”,并将其最优地分配给最有希望的超参数配置。换句话说:它们会为您节省大量时间。
预算是一种衡量标准,当预算较低时,模型会快速训练但相对不准确;当预算较高时,训练时间会很长,但模型性能会更好。
例子总是更容易理解,可能的预算包括
- 时间
- 迭代次数(相对于时间而言,不受硬件影响,并忽略设置时间)
- 训练样本数量
- 要使用的特征数量
- 交叉验证折叠数
- 训练图像大小
- ...
因此,如果我们的预算例如是训练样本数量,优化器可以决定使用低预算(训练数据的子集,更少的训练样本)训练 100 种超参数配置。这可以显著加快训练速度,但会产生较差的结果。
但如果您选择好预算,它将作为同一超参数组合在更高预算(或在我们的示例中,更多的训练图像)下性能表现如何的指示。
使用时间作为预算时要小心
将时间用作预算是直观的:花在模型训练上的时间越多,性能应该越好,这是良好预算的标志。
但时间是相对的,尤其是在数字世界中。更快的机器在相同时间内会获得比慢机器更多的训练迭代次数,并且即使在同一台机器上,网速差异也可能导致不同的设置时间,例如 pip 安装。
因此,使用模型迭代次数而不是时间会更有意义,无论获得这些迭代所需的时间是多少。只有当您为每个候选配置使用完全相同的环境时,才使用时间。
选择早期停止器:使用 Hyperband
逐次减半
简单来说,这种方法在每一轮都会淘汰掉性能最差的一半配置。然而,我们仍然需要自己决定轮数。又一个超参数!因此,通常选择 Hyperband 是更好的选择,因为它无需参数设置!
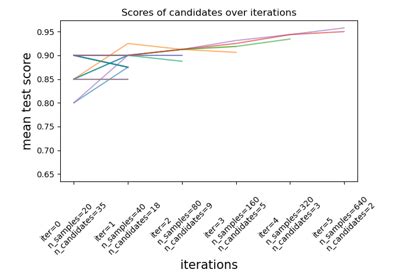
Hyperband
Hyperband 基于逐次减半,但会运行多个不同版本的逐次减半,每个版本使用不同数量的轮数,以便找出哪种版本效果最好。这就是为什么当您使用它时,会首先遇到一些“热身”轮次。它正在为超参数优化器优化超参数!
ClearML 中的 HPO 设置
ClearML 在超参数调优方面采用了一个非常酷的概念。通过将代码抽象成一个黑盒“任务”并优化该任务,而不是将例如 optuna 直接集成到您的代码中,我们可以:
- 优化任何东西而无需修改代码
- 轻松切换优化器、早期停止器,甚至框架本身,并重新运行任务
- 轻松扩展到多台机器
请查看我们之前的博客文章了解更多信息。
现在您了解了以上所有内容,ClearML 优化器设置应该更容易理解了。
ClearML 允许您使用 3 种类型的预算
- 计算时间
- 作业/任务数量
- 迭代次数
您可以通过为其各自的参数设置值来配置 ClearML 使用其中任何一种。只需将其他参数设置为 None 即可忽略这些预算。
计算时间预算
正如在预算部分介绍的那样,这是最直观的预算,但很少是最佳选择。相反,训练深度学习网络或任何其他基于迭代的模型时,您应该选择迭代次数;如果您的模型不基于迭代(例如 SVM 或随机森林),则选择基于作业的预算。
您可以通过使用 compute_time_limit 设置来设置此预算。
但是,如果您在本地(在现有环境中的单台机器上)运行 HPO,使用它仍然有意义,因为您可以确切地知道整个过程将花费多长时间。(尽管由于设置时间和其他一些非计算相关的微小延迟,实际时间会比设置值长一些)
作业预算
作业预算简单地将 ClearML 任务的总数作为其预算。因此,无论每个任务需要多长时间,Hyperband 知道它只有这么多任务来划分配置。
对于任何非基于迭代的模型来说,这是一个不错的选择。
您可以通过使用 total_max_jobs 设置来设置此预算。
迭代预算
迭代次数由 ClearML 自动捕获,因此只要您训练基于迭代的模型,使用此预算就很有意义。
您可以通过使用 total_max_iterations 设置来设置此预算。
您还可以设置 min_iteration_per_job 以确保每个候选在有资格被早期停止器终止之前,至少有机会训练这么多次迭代。
最后,您可以设置这些预算的任意组合,首先耗尽的预算将决定超参数优化的结束。在这种情况下,使用时间预算来确保在截止日期前完成过程是有意义的,同时允许 Hyperband 优化迭代次数以保持跨机器的一致性。
