作者: Victor Sonck,ClearML 开发者布道师
在真实的生产环境中对新生事物进行基准测试
模型部署变得越来越容易,特别要感谢像 Transformers-Deploy 这样的优秀教程。它讨论了如何转换和优化 Huggingface 模型并将其部署到 Nvidia Triton 推理服务器上。Nvidia Triton 是一个非常快速且稳定的工具,在寻找部署模型的方法时应优先考虑。如果你还没有阅读那篇博客文章,请先去读一下,在这篇博客文章中我将多次引用它。
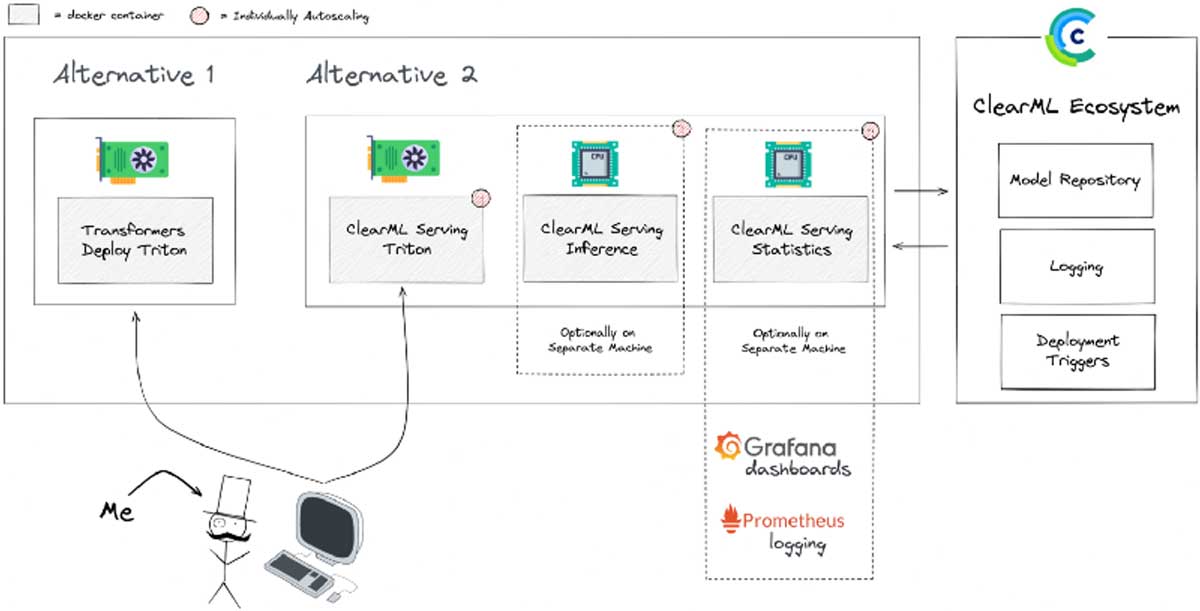
我还会使用一个名为 ClearML 的开源工具。ClearML 是一套旨在帮助数据科学家的工具。你可以单独使用每个工具,也可以将它们组合成一个完整的“MLOps 平台”。它包含实验管理器、远程执行管理、数据集版本管理器、模型仓库等。ClearML Serving 是其中最新的工具;它基于 Triton,允许你通过命令行提供模型,我想看看它的表现如何!
使用 ClearML Serving 设置此示例的代码可以在此处找到。你还可以在下面找到如何设置 Triton 和 FastAPI。如果你想了解更深入的信息,可以在 ClearML 博客的此处找到这篇博客文章的更长、更技术性的版本。
生产环境对 MLOps 的要求
速度不是一切
Triton 推理服务器速度非常快。但虽然速度非常重要,也是这篇博客文章的主要焦点,它只是完善 MLOps 最佳实践并使你的基础设施具备生产部署能力的一部分。
Triton 设计为一个推理服务微服务,这意味着你需要花相当多的时间来确保它与你现有技术栈良好协作。这没问题,因为它允许 Triton 专注于并擅长它最擅长的事情,但在真实的生产环境中你仍然需要一些额外的功能。
模型部署
首先,它应该连接到你的模型仓库,这样你就可以轻松部署模型的新版本并在需要时自动化该过程。同时,如果能够对新模型进行金丝雀部署(Canary Deployment),逐步将流量从旧模型转移到新模型,那就太好了。当然,这一切都可以实现,但这需要宝贵的工程时间和对 Triton 工作原理的深入了解。
自定义统计信息
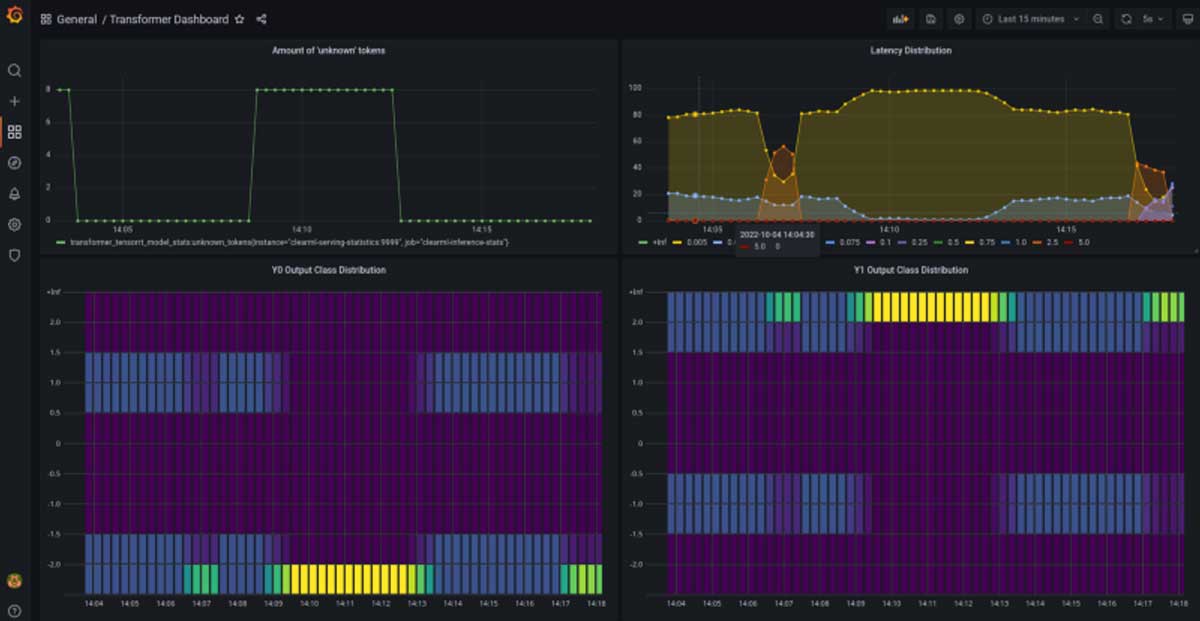
自定义统计信息是 Triton 开箱即用体验相对有限的另一个领域。理想情况下,人们可以轻松定义不仅是延迟和吞吐量的自定义用户指标,还可以分析输入和输出数据的分布,以便稍后检测漂移。这在 Triton 中是可能的,但你必须使用 C 语言定义它们。
可追溯性
最后,Triton 未开箱即用集成的一个结果是可追溯性有限。你需要确保当监控检测到问题或错误时,可以轻松地从已部署的模型“点击穿透”,追溯到用于训练它的管道,再到该管道的每个步骤,甚至追溯到用于训练模型的数据集版本 ID。将所有组件的日志集中管理也很好。
这些只是 ClearML Serving 试图解决的部分“生活质量”功能。为了了解你会为了这些便利性“放弃”多少速度,我将运行一个基准测试。(剧透:你根本不需要放弃任何东西,甚至可能还会获得速度提升!)
基准测试设置
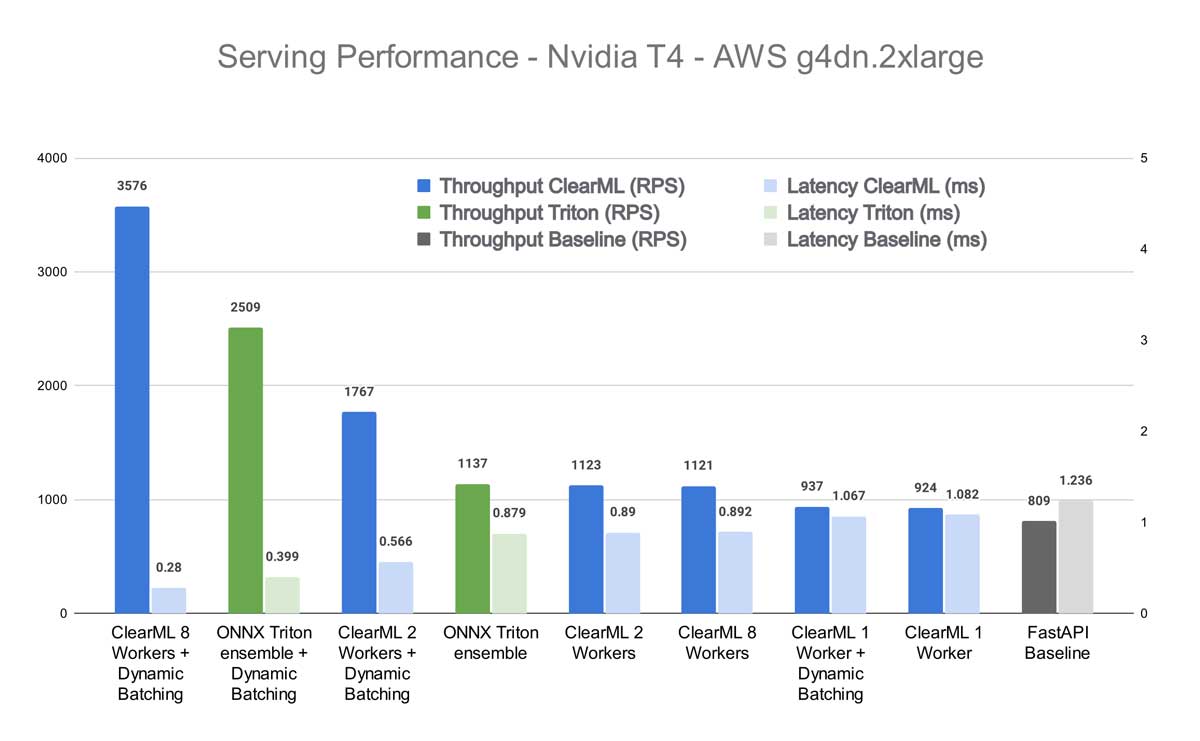
首先,原始的 transformers-deploy 博客文章只测量了单请求延迟。在这篇博客文章中,我将测量负载下的延迟以及吞吐量(每秒请求数),因为这些指标更能反映生产部署情况。我还使用了 ONNX 而不是 TensorRT,因为即使在原博客文章的基准测试中 ONNX 也更快,而且我无法让 TensorRT 的动态批处理工作。当我最终弄清楚时,预计会有另一篇博客文章。
我在两台机器上进行了测试:我自己的 PC 和一台 AWS T4 GPU 云实例。详细信息在图表标题中。所有基准测试都使用 Apache Benchmark 工具运行。
FastAPI 基准线
启动模型最简单的方法就是“将其包装在一个 flask API 中”。如今,整个概念有点像个笑话,因为如今真的没有任何理由这样做。不是从性能角度来看,甚至也不是从易用性角度来看!
你将无法实现无缝模型更新、性能差、没有集成,而且你必须自己编写所有需要的功能。也许对于你不需要所有这些功能,只想用 50 行 Python 代码创建一个 API 的业余项目来说是可以接受的。但即便如此,这也勉强算得上。
话虽如此,我们可以将其用作基准线。这是我们小型、临时模型 API 服务器的代码
https://gist.github.com/thepycoder/a0a3d55730744a6b0dfe0db75da2e769
Triton Ensemble
按照原始 transformers-deploy 博客文章随附的 GitHub 仓库中的说明,我们只需要执行两个 Docker 命令即可。
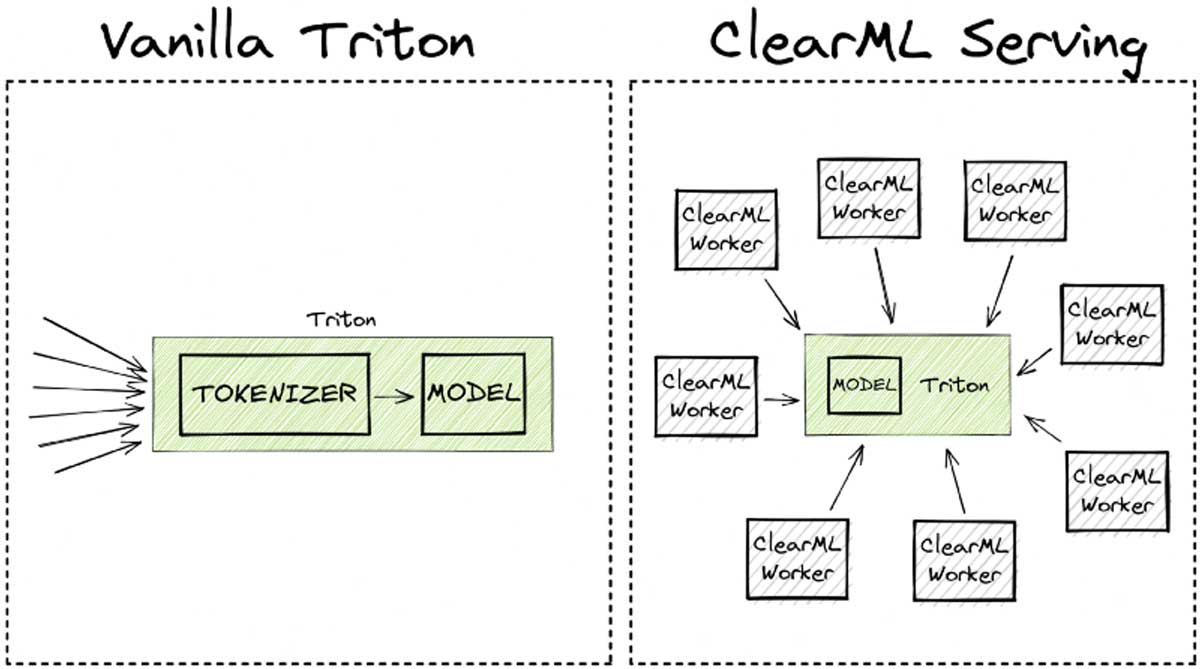
按照这些步骤操作实际上还会设置三个不同的端点。一个用于模型本身,一个用于 tokenizer,然后是第三个端点,它以 ensemble(集成)方式依次运行这两个端点。稍后您将了解更多相关信息。
https://gist.github.com/thepycoder/21561d51b5880a7d0cdf04041433acaf
ClearML Serving
您将获得上述所有“生活质量”功能,以及 Triton 的性能。两全其美!
您可以在 Kubernetes 上部署开源 ClearML Serving 堆栈用于生产环境,或者如果您想保持精简,可以使用 docker-compose。查看 GitHub 说明以设置您的堆栈,但总的来说,就是为 ClearML 服务器设置 API 密钥并运行 docker-compose up
堆栈运行后,我们可以将预训练模型上传到 ClearML 服务器的模型仓库。如果您使用实验管理器训练自己的模型,它们就已经在仓库中了。
https://gist.github.com/thepycoder/eaf34a947b8c62f8cb7f4a0072fc6d26
现在我们已经注册了模型,所有需要做的就是部署它,只需一条命令即可完成!您可以在 Triton 模型随附的 config.pbtxt 文件中找到所有输入和输出信息。
https://gist.github.com/thepycoder/8816eaf939a95ea7a1713208f9c654a5
ClearML Serving 使用前端工作线程来处理用户请求以及任何需要在请求路由到推理服务器之前发生的预处理。这方面的妙处在于这些线程是轻量级的,并且易于与推理服务器本身分开独立扩展。这就是为什么我们在性能图表中说“8 个工作线程”时所指的意思。它意味着有 8 个前端线程处理请求和预处理负载。将预处理阶段与推理服务器分开扩展可以带来显著的性能提升,我们稍后会看到。
基准测试前的优化
分词(Tokenization)呢?
原始的 transformers-deploy 博客文章向你展示了如何使用自定义 Python 模型来设置 Triton Ensemble,首先进行分词,然后再运行模型。
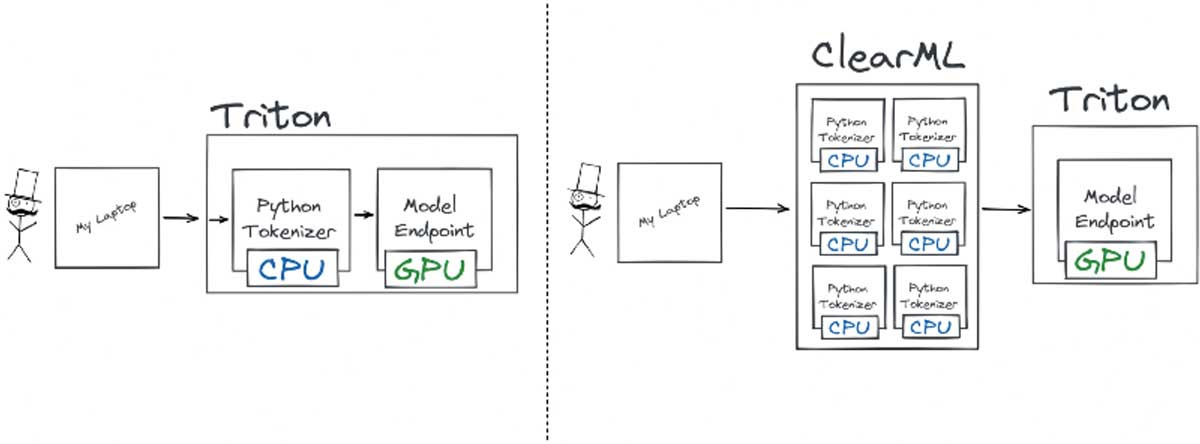
你还可以在上面的代码片段中看到,我添加了一个自定义的 preprocessing.py 文件作为 ClearML Serving 端点的预处理。这个文件的工作与原博客文章中的自定义 python 端点非常相似:它对请求进行分词。
这里的主要区别在于分词是在中间完成的,在到达 Triton 之前,这使得它可以独立于 Triton 服务器进行自动扩缩。添加自定义预处理步骤非常容易,这里是我用于基准测试的示例。
动态批处理
Triton 支持动态批处理,这是一种非常酷且直观的方式来提高吞吐量,但可能以牺牲单请求延迟为代价。
它的工作原理是在可配置的时间内 удерживает 第一个传入请求。在等待期间,它会监听其他传入请求,如果它们在等待阈值内到达,这些额外请求将添加到第一个请求中形成一个批次。如果在时间限制内填充到最大大小,批次会更早处理。通常,在 GPU 上处理批次效率更高,因此以这种方式优化硬件利用率是有意义的。
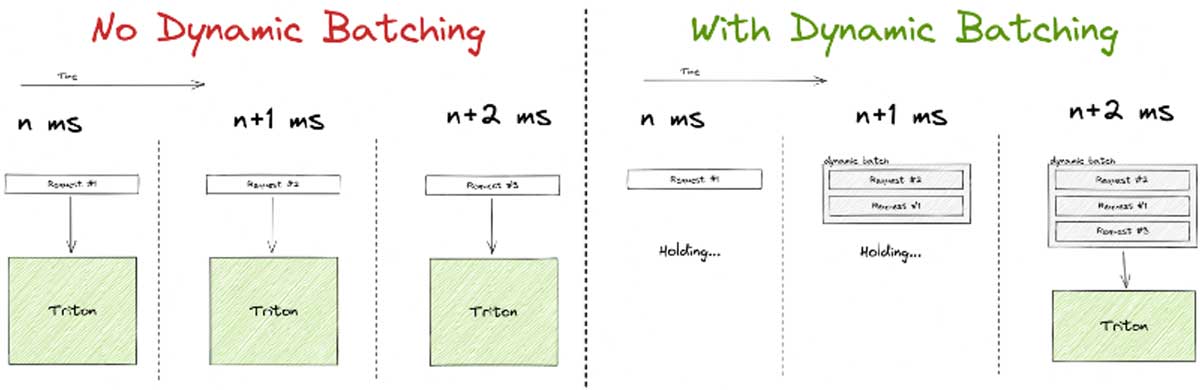
但请注意,动态批处理主要针对高负载系统,原因显而易见。如果您的系统只定期收到请求,那么大部分请求最终都会等待从未到来的额外流量。它们将单独通过 GPU 发送,导致比系统能够达到的延迟高得多,而没有任何实际好处。
结果!
我们启动 AB 并开始向竞争对手发送大量请求,测量延迟和吞吐量。
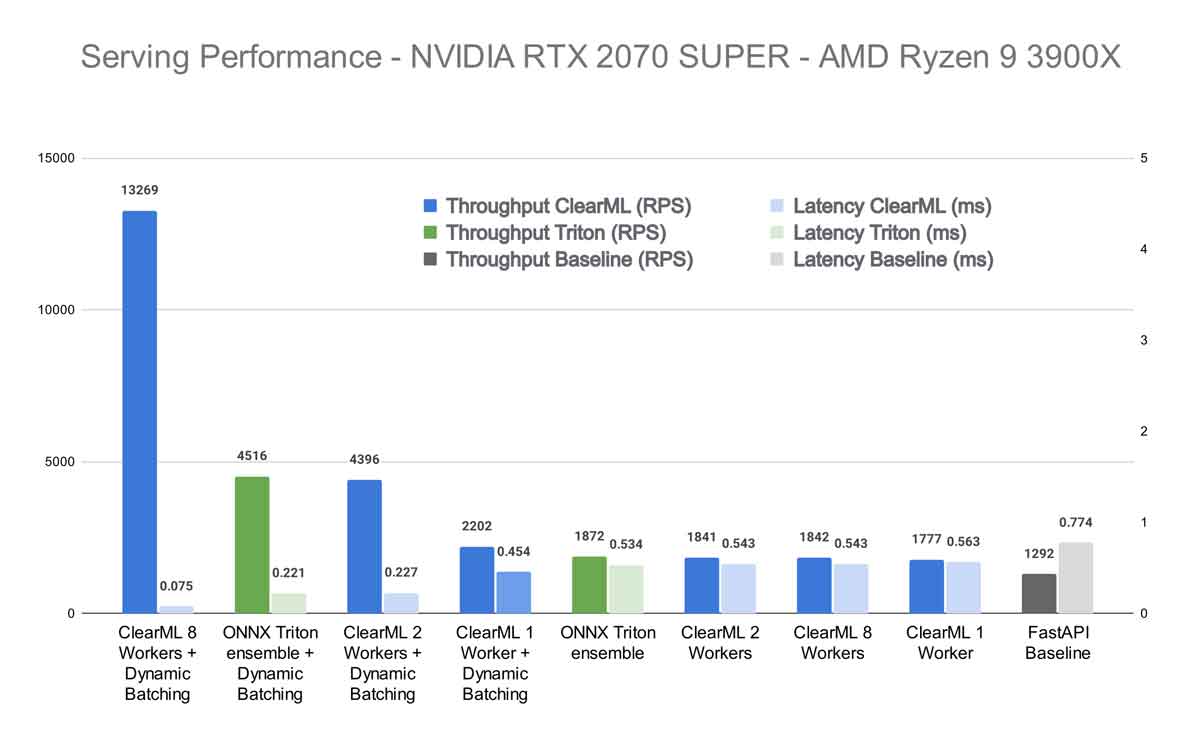
首先,我们想知道我们的竞争对手在不启用 Triton 动态批处理的情况下表现如何。正如预期的那样,FastAPI 包装器在 Hugging Face 接口后面落后,但令人惊讶的是它与其他竞争对手的表现相当。正如您将看到的,这仅适用于批处理大小为 1 的情况,但对于一个基本上只有 21 行代码的服务器来说,这仍然相当令人印象深刻。
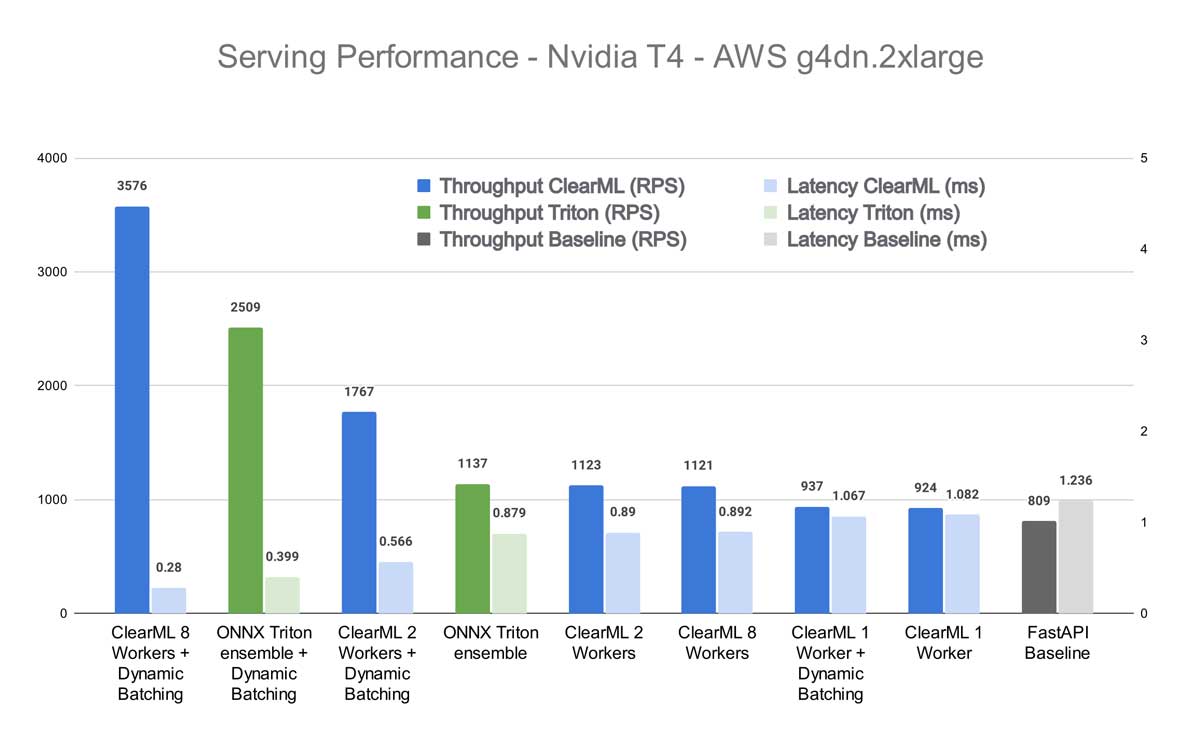
接下来,我们看到 ClearML 位居第二,其结果取决于使用的 worker 数量,但在速度方面从未完全达到 Triton。这也很合理,因为最终它在 Triton 本身之上添加了额外的功能,这会引入额外的延迟。虽然不多,但可以合理地推断它在这种情况下永远无法完全匹配 Triton 的性能。
然而,在 Triton 服务器上启用动态批处理后,情况发生了巨大的变化。请记住,我在我们的底层 Triton 实例以及 Transformers-Deploy 的实例上都启用了动态批处理。
我们看到,当使用 1 个 ClearML Worker 时,性能与不使用动态批处理时基本相同。这也很合理,因为在这种情况下,1 个 Worker 很快就成为了瓶颈。但当 Worker 数量增加时,情况开始迅速改变。当使用 8 个 ClearML Worker 时,总吞吐量甚至明显高于 Triton Ensemble!
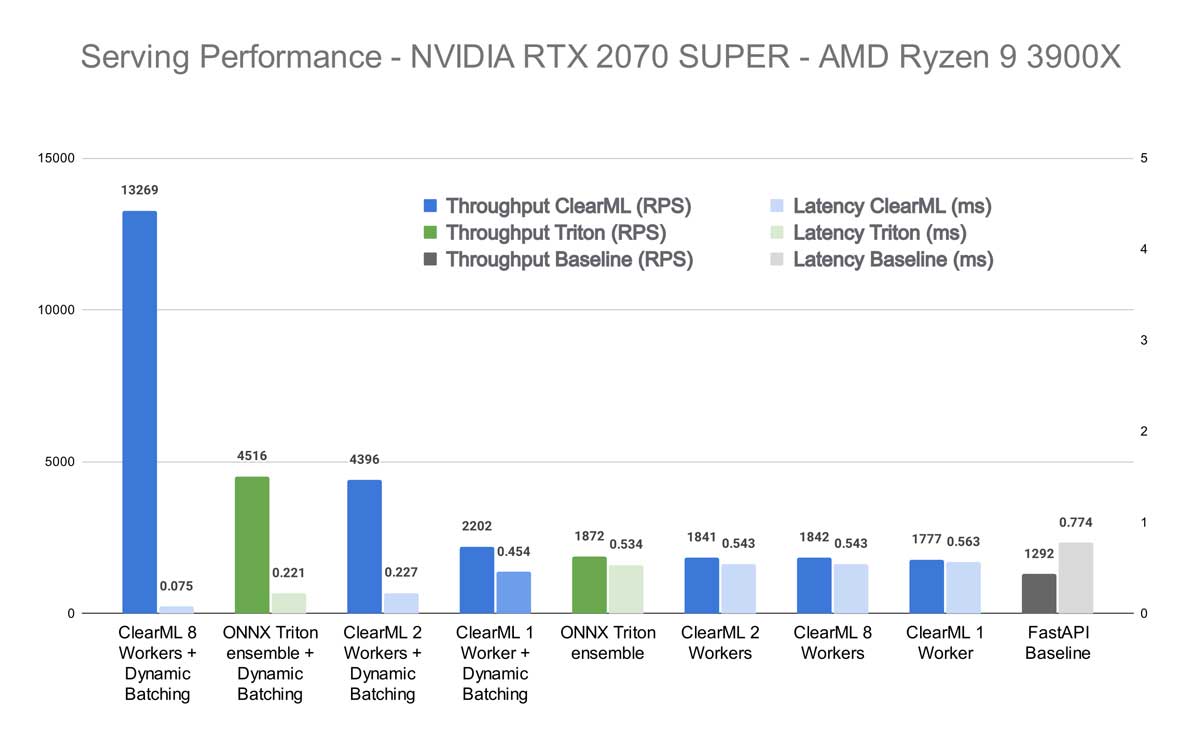
这种效果在我自己的机器上更加明显。似乎 CPU 更高的质量、速度和核心数对 ClearML Serving 的性能产生了显著影响。这并不奇怪,因为 ClearML Worker 在很大程度上依赖于基于 CPU 的扩展来正确地为 GPU 提供数据。将启用动态批处理的 8 个 Worker 的 ClearML 结果与启用动态批处理的 Triton ensemble 进行比较,您将获得标题中提到的性能提升。如果将其与开箱即用、未启用动态批处理的 Triton 进行比较,则吞吐量会大幅增加 608%。
等等,但我之前说过我们甚至无法匹敌 Triton 的性能,更不用说大幅超越了。好吧,那是在启用动态批处理之前。但在启用之后,运行分词的单个 python“模型”实例开始成为瓶颈。
本质上,这意味着在达到一定规模时,ClearML Serving 开始超越其开销,基本上免费为您提供所有额外的功能!
结论
要大规模部署,需要考虑的不仅仅是单请求延迟。 Transformer-Deploy 博客文章及其 仓库的作者在提供一个框架以优化 Hugging Face 模型用于生产方面做得非常出色。在这篇博客文章中,我们更进一步,展示了在更真实的生产场景中,您可以期望这些模型获得多少性能。
我们最终添加了必要的基础设施,例如自动部署新模型的能力、添加自定义统计信息以及跟踪模型版本,同时在大规模部署时吞吐量仍提高了 3 倍。
再次强调,重现此示例的代码可以在此处找到。
如果您有兴趣了解 ClearML 本身,请访问我们的 GitHub 仓库并试用一下!如果您需要任何帮助,请随时加入我们的 Slack 频道,我们的社区将很乐意为您提供帮助!
