得益于ChatGPT和Langchain(一个巧妙地使用ChatGPT但无需重新训练的开源工具),现在可以创建一个能够引用您自己的文档和帮助渠道的问答(QA)机器人了。但这离“开箱即用”还差得很远。一个例子就是,您必须把Prompt(提示)写得恰到好处。要让大型语言模型(LLM)完全按照您的意愿行事,您的指令必须非常明确,那么我们是否可以也将此过程自动化呢?
代码已在GitHub上提供,您可以在下方找到链接!
背景:基于您自己的文档构建一个问答聊天机器人
客户支持很难扩展。从完全开源的项目到跨国公司,它几乎是所有企业和组织的一个痛点。然而,得益于Langchain和OpenAI,现在可以制作出实际有用、定制化的聊天机器人,帮助回答以前被问过的问题或文档中已说明的问题。通过这种方式,支持团队可以更专注于帮助用户解决新颖或非常复杂的问题。
然而,像ChatGPT这样的模型并非即插即用。ChatGPT(截至撰写本博客文章时)没有外部访问权限,因此它必须“凭记忆”想出问题的答案,实际上这意味着它倾向于幻觉出看起来有道理但却是错误的答案。
为了解决这个问题,我们将结合ChatGPT API使用以下技巧:
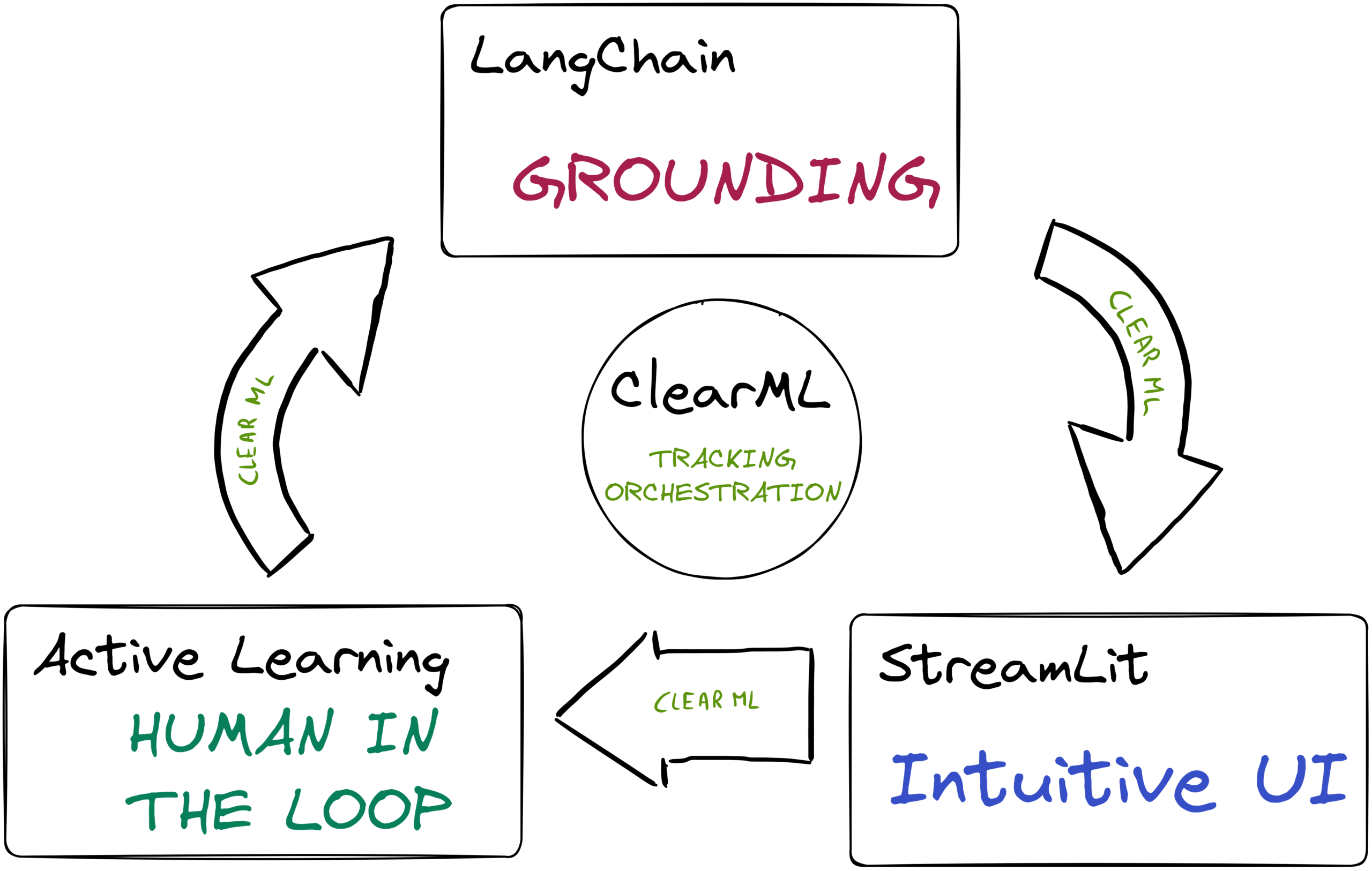
- 使用LangChain进行接地(Grounding):接地是将尽可能多的相关信息与清晰的指令甚至示例一起放入LLM的Prompt中。我们将向模型展示相关的文档片段,它可以使用这些片段基于事实来组织答案。
- 主动学习(Active Learning):我们给LLM的具体指令Prompt也可以学习!我们将使用一个主动学习循环,通过人工参与迭代改进初始指令Prompt,以获得最佳性能。ClearML将跟踪进度并协调该循环。
- 直观的用户界面(Intuitive UI):我们将构建一个Streamlit应用,以便任何用户、QA专家或标注员都可以评估和评分当前版本的机器人。这是一个非常重要的步骤,因为它允许其他人参与优化过程。
我们将展示这些组件如何在流程中发挥作用,所以让我们从第一个开始:使用LangChain进行接地。
基于您自己数据的问答:Langchain
Langchain是一个开源工具,用于“串联”对OpenAI等LLM API的智能调用,以执行比这些模型通常开箱即用更个性化和特定的任务。
本质上,它是将预先构建、经过良好测试的Prompt转化为您可以直接插入更大逻辑链中的“模块”。
Langchain入门:数学
还记得这些LLM模型不擅长数学吗?通过巧妙地使用Langchain,我们实际上可以解决这个问题。
from langchain import OpenAI, LLMMathChain
llm = OpenAI(temperature=0)
llm_math = LLMMathChain(llm=llm, verbose=True)
llm_math.run("What is 13 raised to the .3432 power?")
Entering new LLMMathChain chain... What is 13 raised to the .3432 power? ```python import math print(math.pow(13, .3432)) ``` Answer: 2.4116004626599237 > Finished Chain
显然,这里幕后发生了很多事情。查看源代码揭示了其中涉及的技巧。我将省略具体细节,但当调用llm_math.run时,大致发生的事情如下:
- 首先,“13的0.3432次方是多少”这个问题被格式化到一个更大的、预先构建的Prompt中,该Prompt包含问题的描述以及模型回答问题的方式,还有一些示例。
- 这个Prompt确保AI总是回复一个代码块,这比实际进行数学计算要好得多。
- 然后,一个后处理函数会启动一个实际的代码执行环境,提取代码块并运行它。
- 检测到LLM生成的结果,并将其替换为代码运行的实际结果,这样我们就能确定它(如果运行成功)总是正确的。
这里没有进行任何训练,只是用一种巧妙的方法让LLM输出标准化的格式,然后您可以像解析正常程序或API中的任何其他数据一样解析和使用它。
文档问答机器人
文档问答的方法也是一样的,只是涉及的步骤更多。主要部分包括:
- 使用OpenAI嵌入API来嵌入您的文档和其他可能有用的信息
- 根据用户问题,检索相关信息并要求LLM逐字提取有用的部分
- 根据问题和文档中的有用部分,要求LLM回复,并基于它收到的相关信息引用来源。
专家提示:使用ClearML-Data来跟踪您自己的文档!版本控制系统让您可以轻松跟踪新版本的文档,使用实验管理器可以跟踪将文档预处理为文本文件的任务,并且这两者将始终关联。额外的好处是,当您的文档有新版本推送时,这种设置可以非常轻松地自动化生成这些文本文件和嵌入。


这种设置可以带来一些真正令人印象深刻的结果,也会出现一些明确的自信错误案例。然而,这是我们可以尝试使用Prompt工程来解决的问题吗?毕竟,正如我们上面所见,Langchain在幕后只使用特定的Prompt模板,那么如果我们请LLM来找到最优的Prompt呢?
元学习:AI训练AI
这里的元学习思想是优化Langchain用于生成用户问题答案的Prompt模板。当然,请求GPT创建一个新的Prompt,必须通过使用…另一个Prompt来完成。但这最后一个Prompt更具普遍适用性,因为它是一个优化Prompt的Prompt。好的,Prompt有点多,我们在这里画一个图来梳理清楚一切。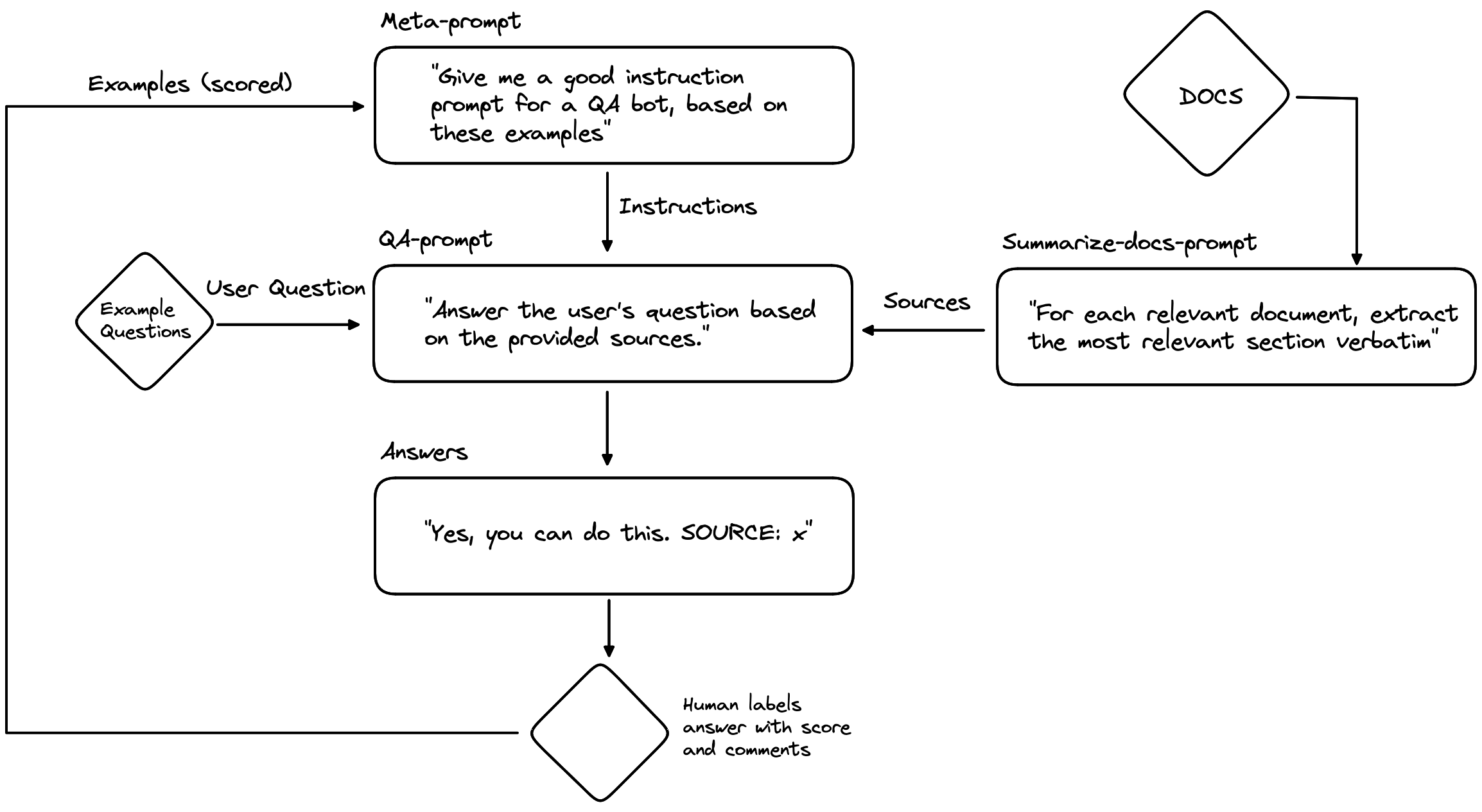
所以,一个元Prompt被用来为QA机器人生成QA Prompt(包含指令)。元Prompt包含一些示例QA Prompt,以及QA机器人在使用这些Prompt时输出被人类评分的程度以及一些自由文本评论和反馈。
基于这些示例和反馈,它会尝试创建一个新的QA Prompt,认为它会表现更好。生成的QA Prompt随后与文档来源和用户问题结合。在这种情况下,我们将使用来自给定示例集的问题供人类评分。
QA机器人回答每个示例问题,人类对其整体表现以及一些反馈评论进行评分。这些信息现在可以添加到元Prompt中,以便它可以生成一个新的、更好的QA Prompt,循环继续。
我们也可以尝试以相同的方式优化摘要文档Prompt,但在这篇博客文章中,我们先保持“简单”,只关注QA Prompt。
完善:邀请同事和质量保证团队参与
一旦我们实现了上述图表,我们就拥有了一个理论上只基于人类自由格式输入就能变得更好的闭环。为了获得这些输入,让我们把体验打磨得足够好,以便任何有电脑的人都能贡献。通过这种方式,您可以让整个团队甚至更多人参与到Prompt优化器中来。
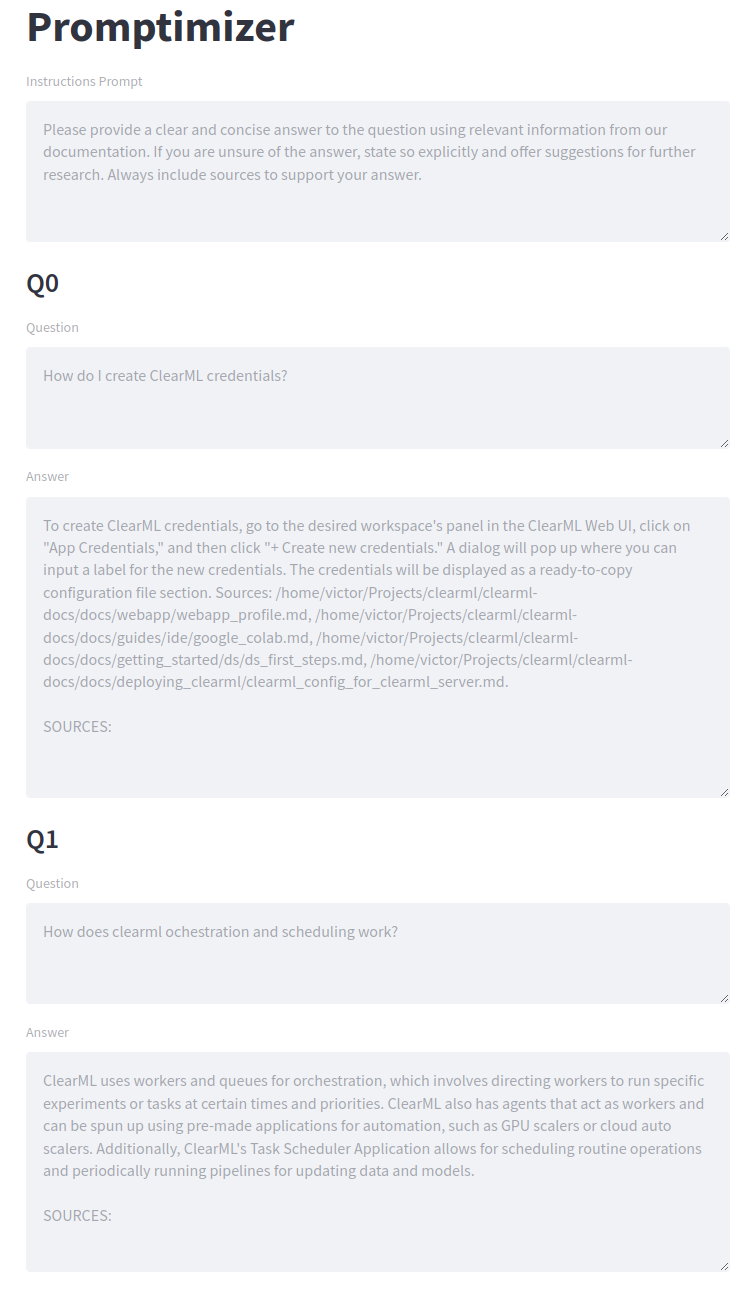
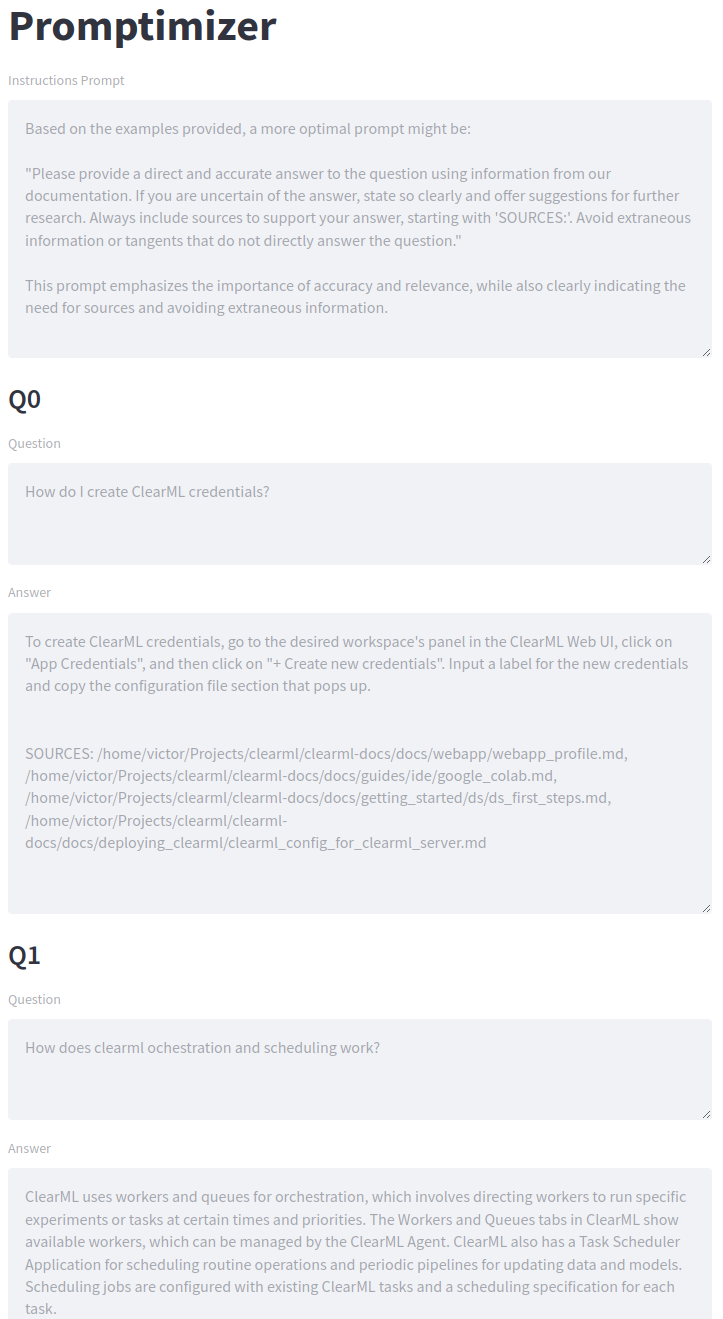
为了让一切看起来漂亮且易于部署,我们将Langchain流程封装进了一个Streamlit应用。正如您在截图中看到的,结构与我们的图表非常相似。首先是指令Prompt(用于QA机器人)。这将由LLM生成,也是我们要优化的Prompt。
接下来,我们有一系列的示例用户问题。这里就是您的质量保证团队发挥作用的地方。他们可以完全自由地提出示例问题,并可能制定标准化的评分方式。
最后,评分部分可以由任何同事用来评估回复的质量。这些反馈会通过将其作为Prompt生成器的示例添加到系统中来反馈。点击提交按钮后,新一轮的生成将开始。我们正在用纯文本进行梯度下降!
使用ClearML进行部署
文档数据版本控制
当您使用文档进行嵌入,然后用作QA机器人的参考信息时,使用ClearML-Data进行数据版本控制非常有意义。这样,您可以随时轻松回滚、查看所做的任何更改,并基于例如新版本的文档轻松自动化数据生成。
实验管理
ClearML与Langchain有原生集成,因此每次运行一个链时,ClearML都会记录对OpenAI API进行了哪些精确调用以及所有返回值为何。这有助于轻松调试,同时也是您的实验的可搜索历史记录。
Streamlit部署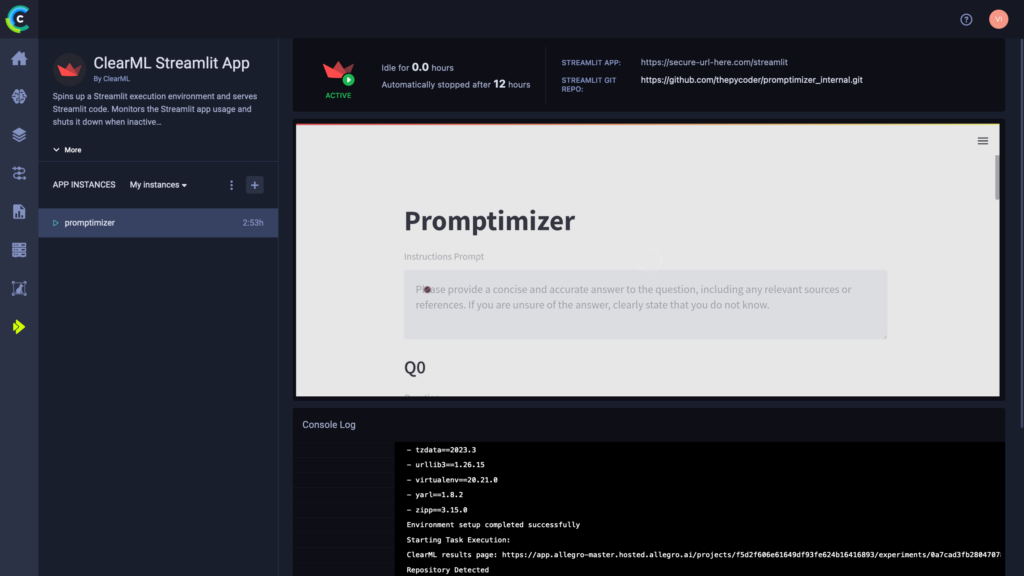
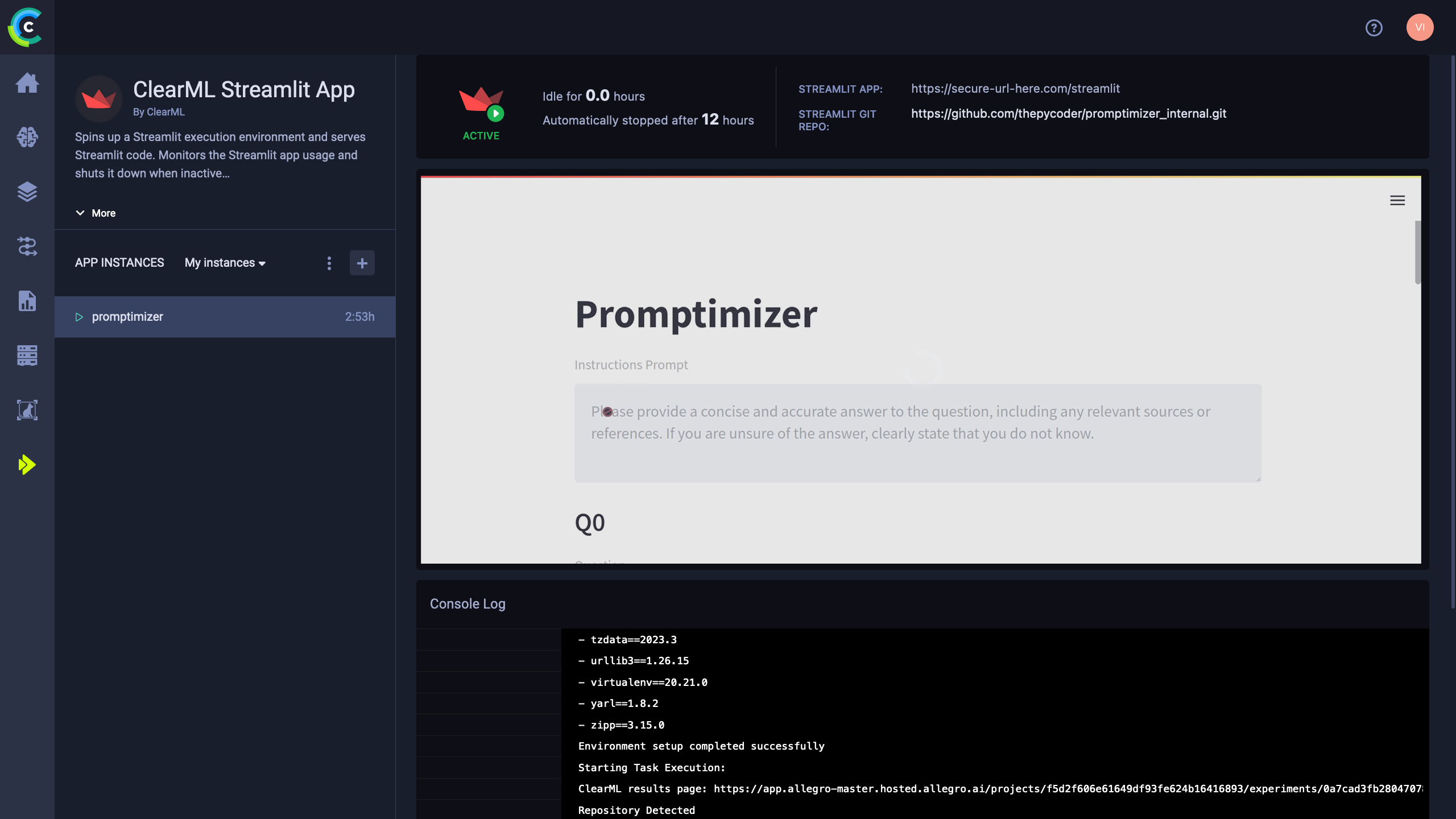
企业用户甚至可以直接在ClearML WebUI中托管他们的gradio和streamlit应用。这样,整个系统是集成的,您对整个流程有一个清晰(双关语)的概览。
结果与代码
正如您从上面的截图中可以看到的,机器人在报告来源(以正确的格式)方面做得不太好。因此,这将是对此Prompt的主要反馈。点击提交后,第二个Prompt似乎已经好多了,生成的答案也反映了这一点。
我们做了不少测试和尝试。结果很难客观量化,但从经验上看,Prompt确实有所改进,不过这个过程是否比简单地自己创建Prompt并进行测试更容易,还有待商榷。
尽管如此,这仍然是一个有趣的实验,如果您有大量可以标注Prompt的人,这种方法的可扩展性要高得多。
如果您想自己尝试一下,可以在GitHub这里找到代码。
后续步骤
这只是大型语言模型(LLM)能力的开始。LLMOps也刚刚起步。在未来的博客文章中,我们将进一步探讨LLMOps,所以请告诉我们您面临哪些挑战,以及您希望我们展示什么。
除了用例之外,当这些模型的开源、自托管版本投入使用时,也将非常有趣。届时,我们将不得不开始处理本地LLMOps,这本身将是非常有趣和具有挑战性的。
最后,当越来越多的客户开始使用ClearML进行端到端LLMOps旅程时,看到已完成的LLM基础设施架构投入生产将非常有趣。我们迫不及待!
请在我们的Slack频道中发表您的建议,我们非常乐意讨论 :)
