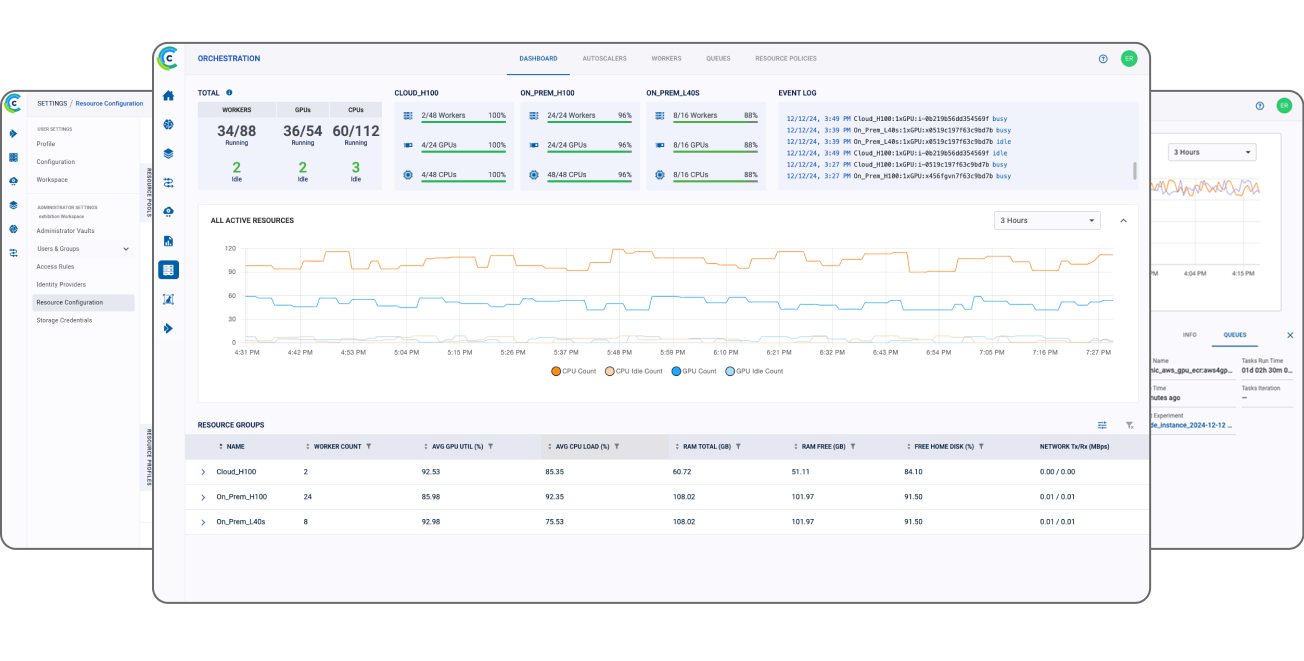
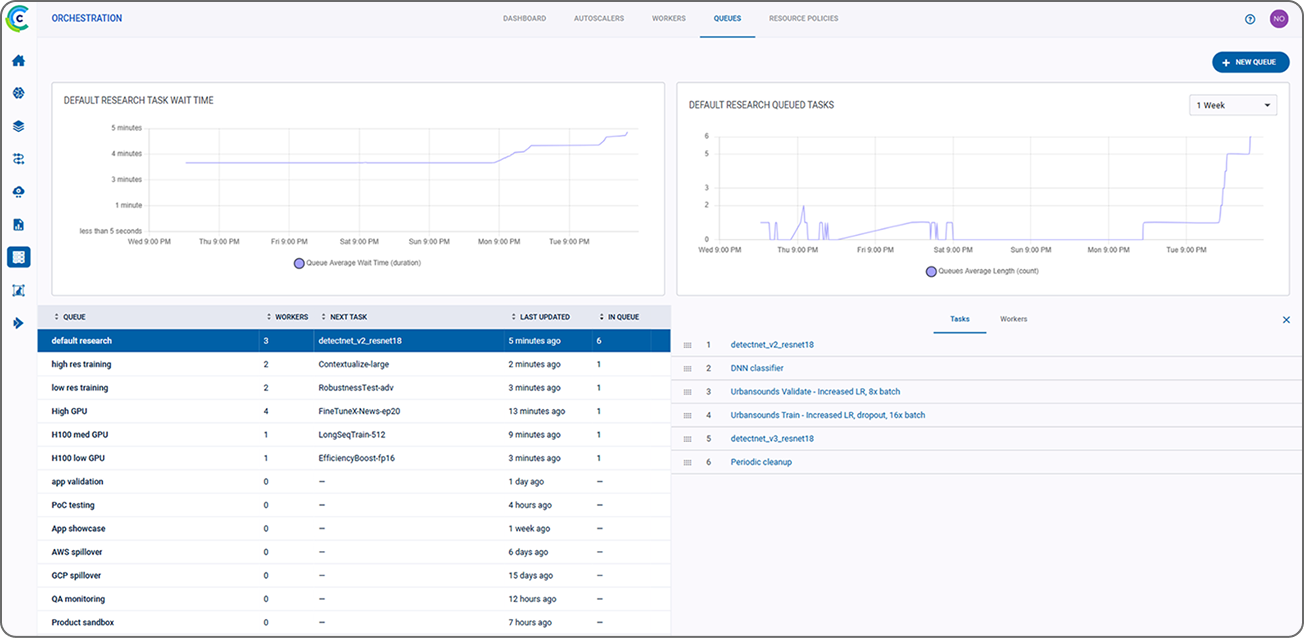
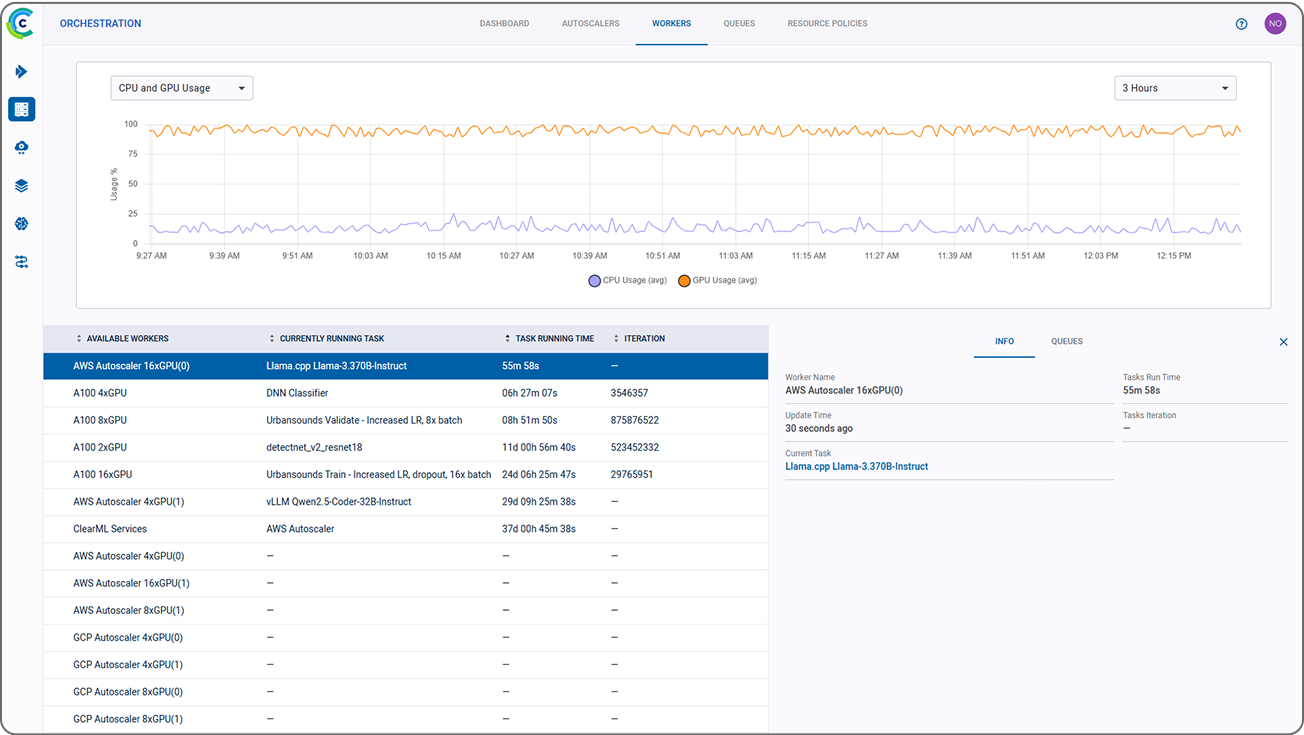
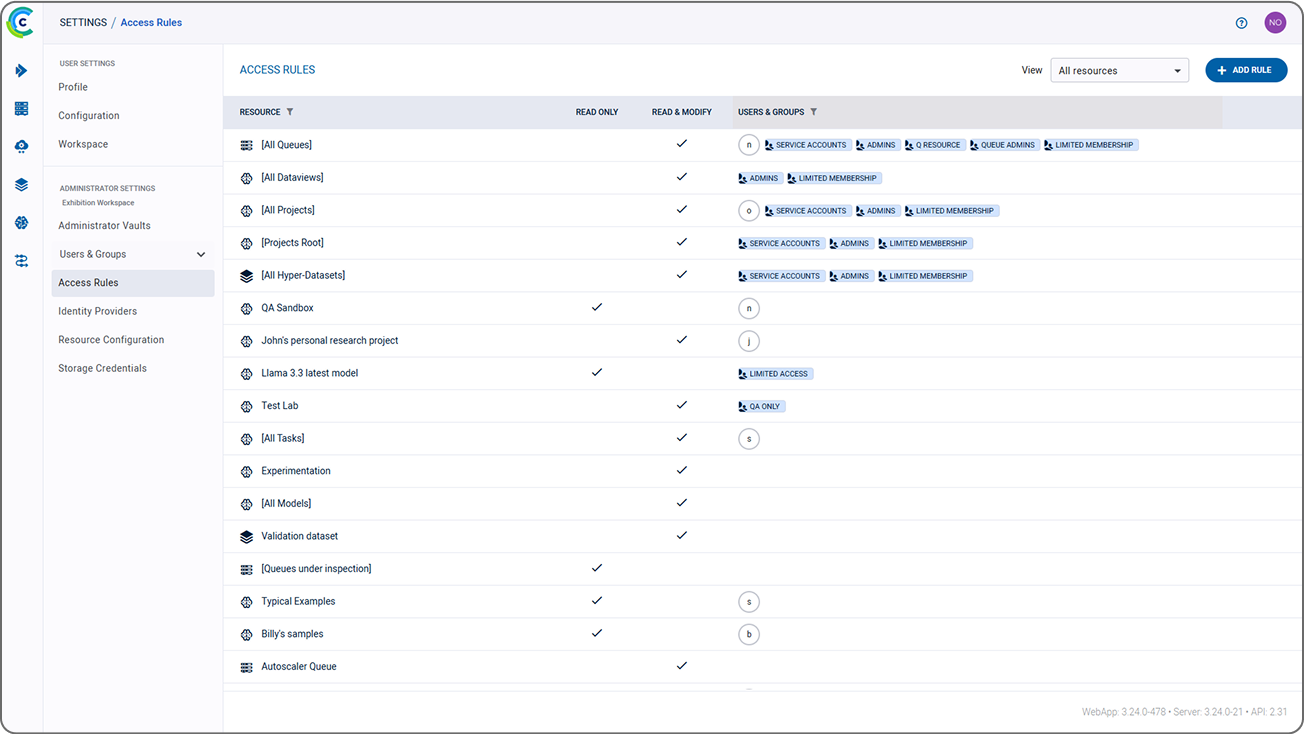
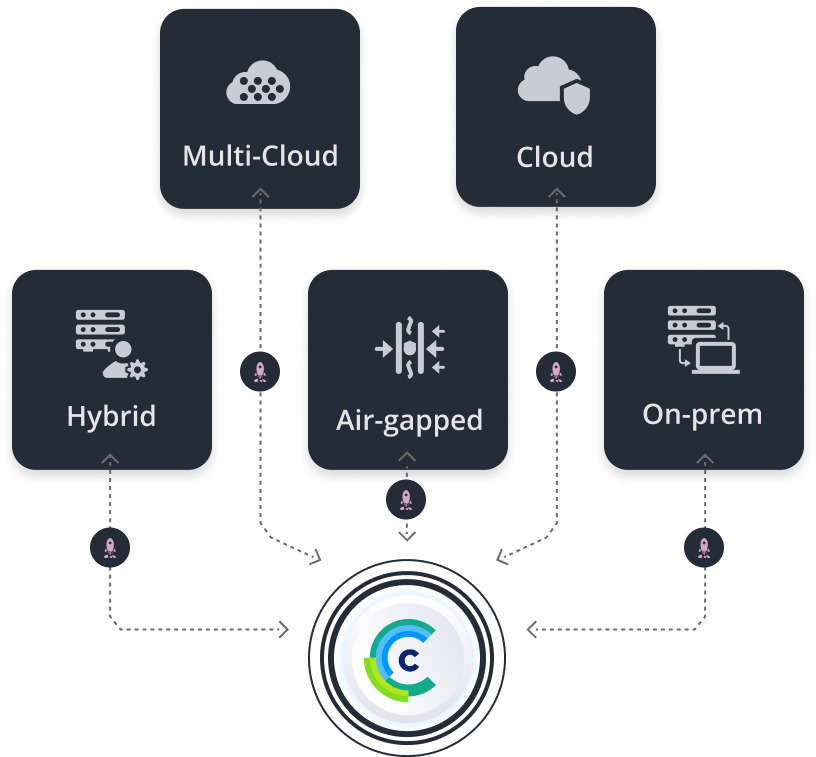
集中式界面使得管理多个部署环境变得简单,提供完全优化的计算基础设施(细粒度可达 GPU 的一小部分),连接所有 AI 工作负载。在多个 AI 项目和 AI 构建者之间轻松共享资源,并负载均衡计算消耗以最大限度地提高计算利用率。IT 团队可以使用任何 GPU 或 CPU 加速器配置集群,无论是在本地、跨多云还是在安全的隔离网络中。
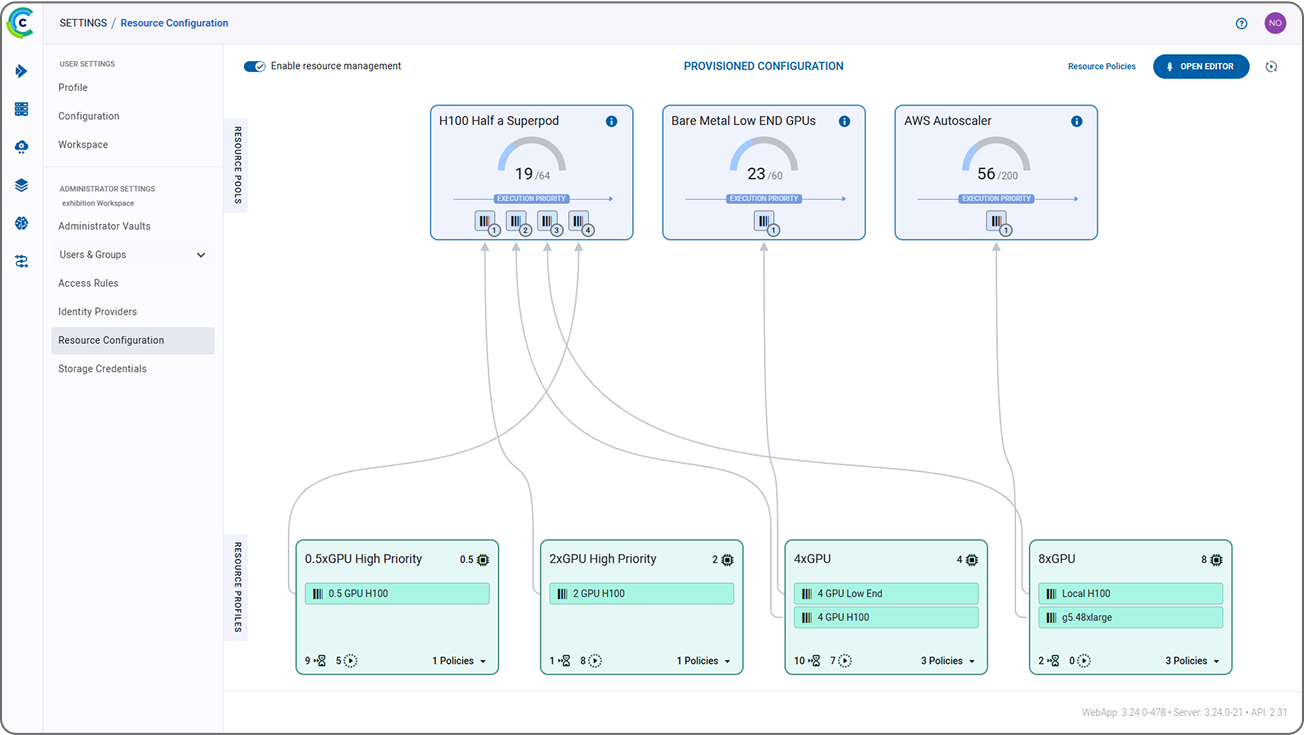
为您的 AI 构建者简化 AI 模型和代理的开发和部署。IT 团队创建支持层级和逻辑的资源分配策略,使他们的 AI 构建者能够通过 IDE 一键启动远程会话。内置的 ClearML 作业调度程序无缝地使 AI 构建者能够自助获取计算资源,并将 AI 工作负载直接调度到批准的资源上。借助我们灵活、硬件无关的架构,您可以在几乎任何类型的集群(Kubernetes、Slurm、PBS 和裸金属)上训练、微调和部署模型,该架构兼容 NVIDIA™、AMD™、Arm™ 和 Intel™。