ClearML Autoscaler
有时,您或您的团队所需的处理能力可能某一天非常高,而另一天又非常低。尤其是在机器学习环境中,这是一个常见问题。团队可能某一天正在训练模型,计算需求会飙升,但其他日子他们可能在进行研究,弄清楚如何解决一个具体问题,只需要一个网络浏览器和一些咖啡。

这正是 autoscaler(自动伸缩器)旨在解决的问题。通过观察对计算资源的传入需求,autoscaler 会在检测到需求很高时启动多台机器,并在没有任务需要执行时关闭它们以降低成本。一个好的 autoscaler 会让您精心配置这个过程的每个部分,这样您就可以自己决定何时、启动哪种类型的机器、持续多久等。
简单示例
要开始使用 autoscaler,请考虑这个简单的任务示例
import time
# 2 行神奇的代码
from clearml import Task
task = Task.init(
project_name='aws_autoscaler_example',
task_name='time_sleep'
)
time.sleep(60)
print("Hello World!")
我们的任务在这里所做的唯一事情就是睡一会儿然后结束一天,就像我一样!不过,我们只是将这个任务用作占位符,通常这是进行预处理或模型训练的地方。
首先,在大多数情况下,在本地运行此任务一次是有意义的。虽然您可能没有云端的计算资源,但确保代码至少运行,即使只运行 1 个 epoch,通常也比等待它远程处理要快得多。话虽如此,您当然可以立即使用 task.execute_remotely() 函数远程执行它。
一旦我们第一次运行了该任务,我们就可以前往 WebUI 并克隆它几次,开始测试我们的 autoscaler。此时,我们的实验 UI 看起来像这样
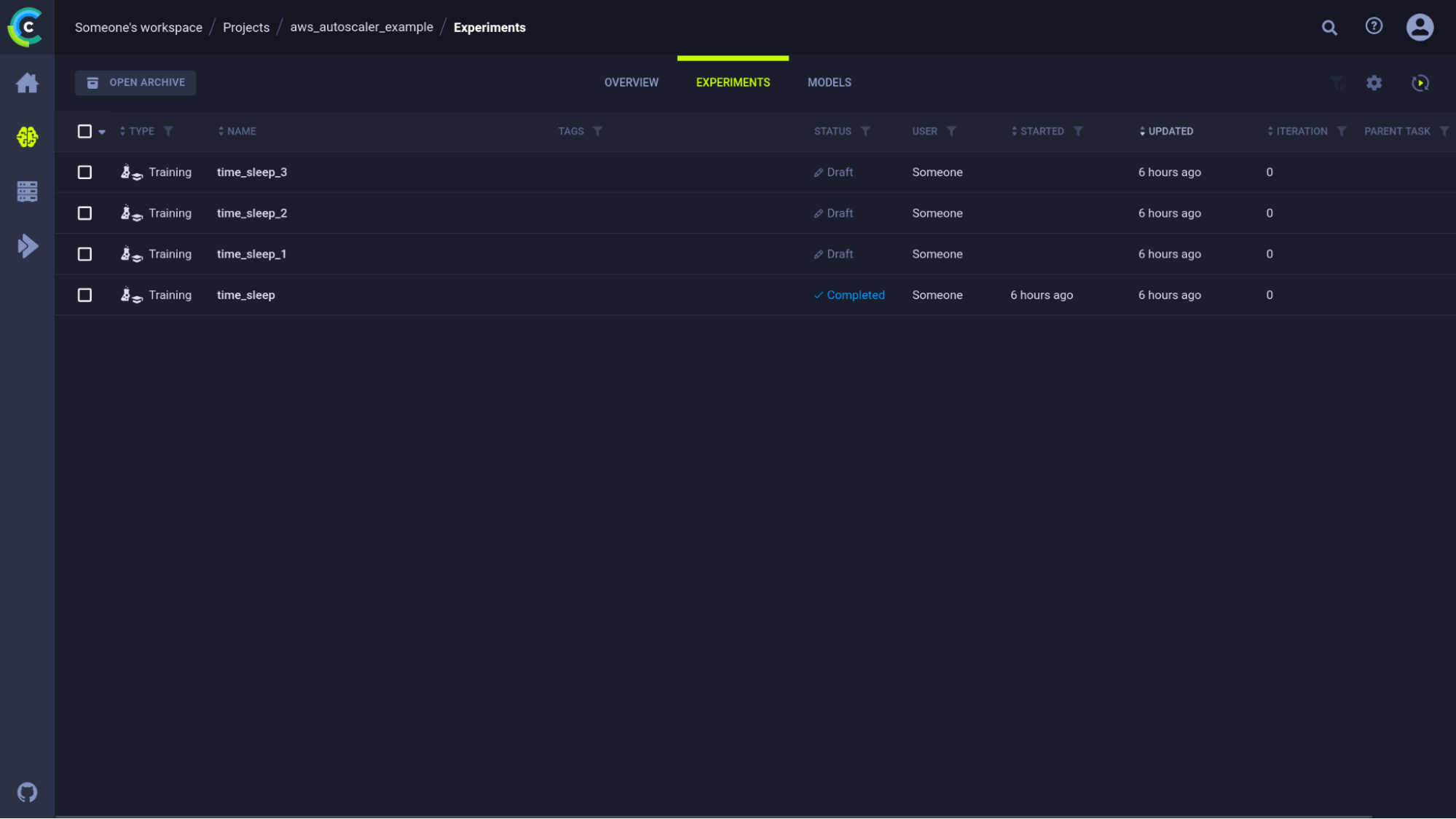
如果我们现在将这 3 个任务加入队列,它们将被添加到队列中,但目前还没有 worker。让我们来解决这个问题!
设置 autoscaler
使用 autoscaler 有 2 种方法:使用 Web 界面和使用 SDK
使用 Web 界面
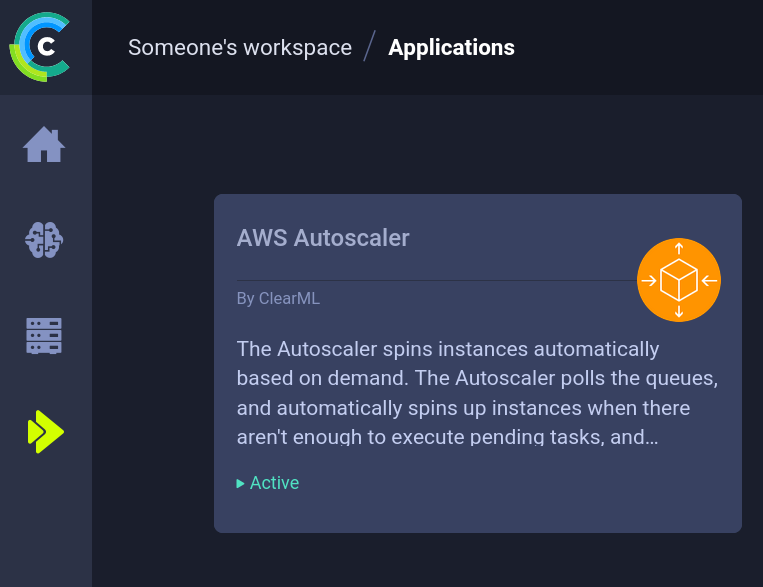
Web 界面配有专用的概览仪表板。在这里可以轻松创建和监控新的 autoscaler 部署。要设置 autoscaler,请转到 ClearML apps 选项卡并选择 AWS autoscaler 选项卡。您现在应该会看到如下所示的 AWS autoscaler 仪表板。
从这里,您可以监控空闲实例的数量(左上)、每个队列中有多少任务、当前正在处理任务的实例数量(中间)以及 autoscaler 本身的日志(底部)。

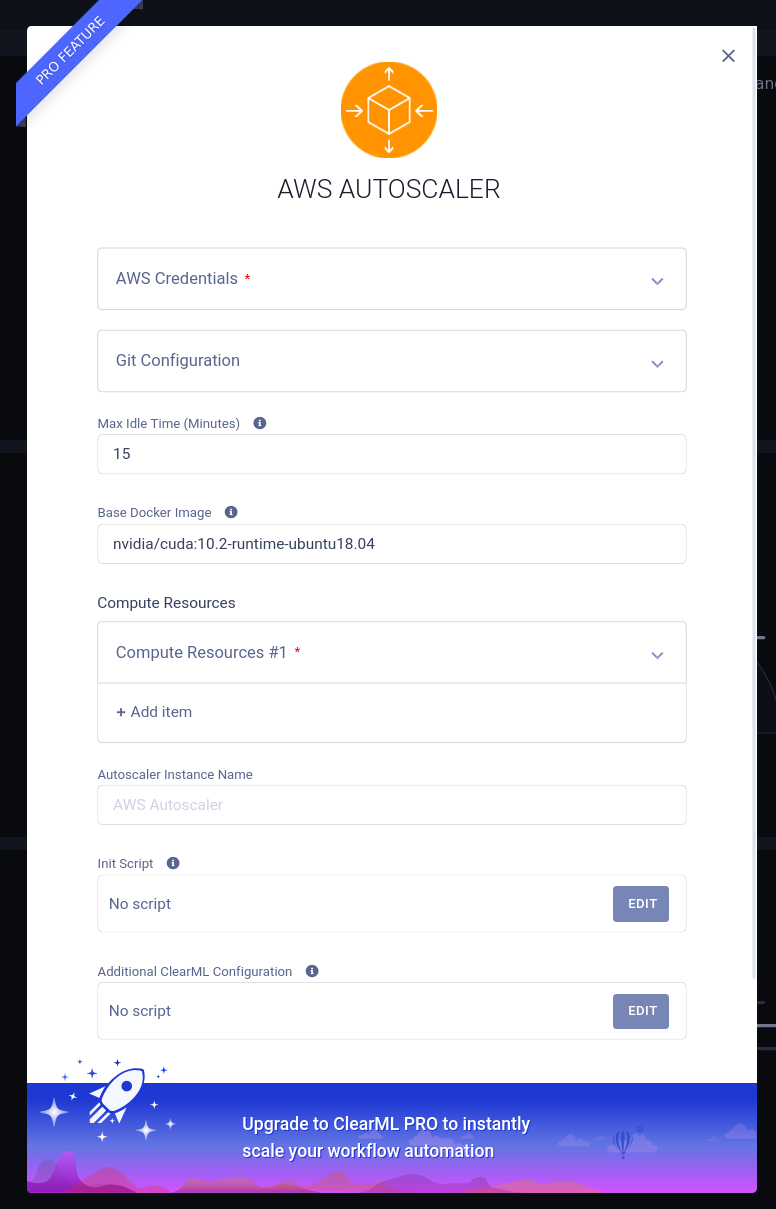
要创建新的 autoscaler 部署,只需单击加号并在弹出的表单中填写您的 AWS 和 Git 信息。如果您需要帮助理解特定字段,请将鼠标悬停在小小的“i”工具提示上。如果任何工具提示不清楚(双关语),请随时访问我们的 Slack 频道寻求帮助!
使用 SDK
如果您使用的是我们的 ClearML 服务器的免费层级或自托管版本,则需要做更多工作。具体详情请参阅 此处的文档,但要点如下:
- 使用 aws_autoscaler.py 脚本在本地或远程设置 autoscaler 本身
- 或者从 DevOps Services 项目克隆示例任务并在配置选项卡中编辑参数
- 如果远程运行,请设置一个 worker 来处理服务队列
我们的文档 此处提供了一个详细示例。
我们将在下面进一步解释为什么您仍然需要一个 worker。
Autoscaler 的提示和技巧
为多个队列设置多种 worker 类型
通常,您会希望针对不同的工作负载使用不同的 worker 类型。在大型 GPU 机器上运行数据预处理或在只有 1 个 CPU 核心的机器上训练模型都不太划算。因此,为了适应这种情况,可以设置多个队列并将相似的任务类型分配到相同的队列中。然后,我们可以设置多种类型的 EC2 实例,使其仅侦听特定的队列,并设置不同的超时时间等。这样,就可以针对异构工作负载优化成本。
请注意,如果您的 AMI 中安装了 Docker
默认情况下,autoscaler 将尝试在 EC2 实例上使用 docker 启动 ClearML agent 守护进程。如果您选择的 AMI 中默认没有安装 docker,则有 2 种选择
- 删除默认的 docker 镜像(UI)或将其设置为 None(SDK),以指示 ClearML 在没有 docker 的情况下运行 agent
- 通过添加以下 2 行使用 init 脚本安装 docker
curl -fsSL <https://get.docker.sh> -o get-docker.sh
sh get-docker.sh
强制 ClearML 不使用 GPU
如果您不需要 GPU,并且只想要一台 GPU 机器,那么您可以在与上面相同的 init 脚本中设置环境变量 CUDA_VISIBLE_DEVICES=none 来强制只使用 CPU。
Autoscaling 实际上是如何工作的?
ClearML 在其正常工作流程中已经使用了 队列和 worker。Autoscaler 本质上是一个简单的过程,它位于队列和 worker 之间,并监控队列是否有任何传入任务。如果它找到一个新任务,它会检查是否有任何订阅该队列的空闲 worker 可用。如果有,则将任务分配给该 worker;如果没有,它可以使用您的 AWS 凭据设置 EC2 实例并启动 clearml-agent 守护进程,将该实例转换为 worker!
眼尖的读者会问自己 autoscaler 本身在哪里运行,答案取决于您的部署方式。如果您是付费客户并使用我们在 app.clear.ml托管的服务器,后台会启动一个小型 worker 来处理编排,您无需自己做任何事情。
如果您运行的是自托管版本或免费层级,则需要手动启动一个 worker,该 worker 侦听特殊的 services 队列。这个队列很特殊,因为它只托管支持其他 ClearML 功能的任务,例如在本例中,autoscaler 编排器。
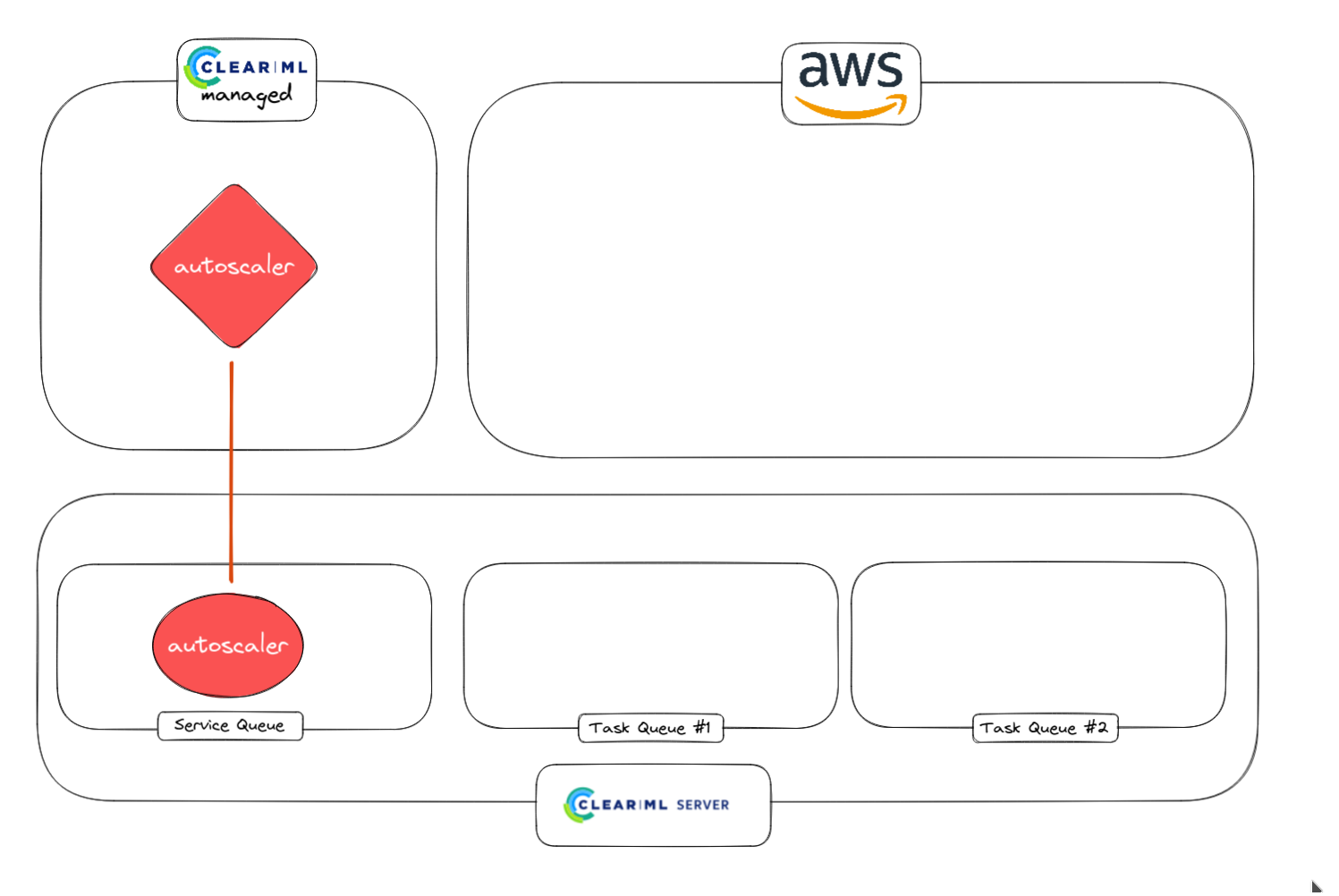
1. Autoscaler worker 从服务队列启动
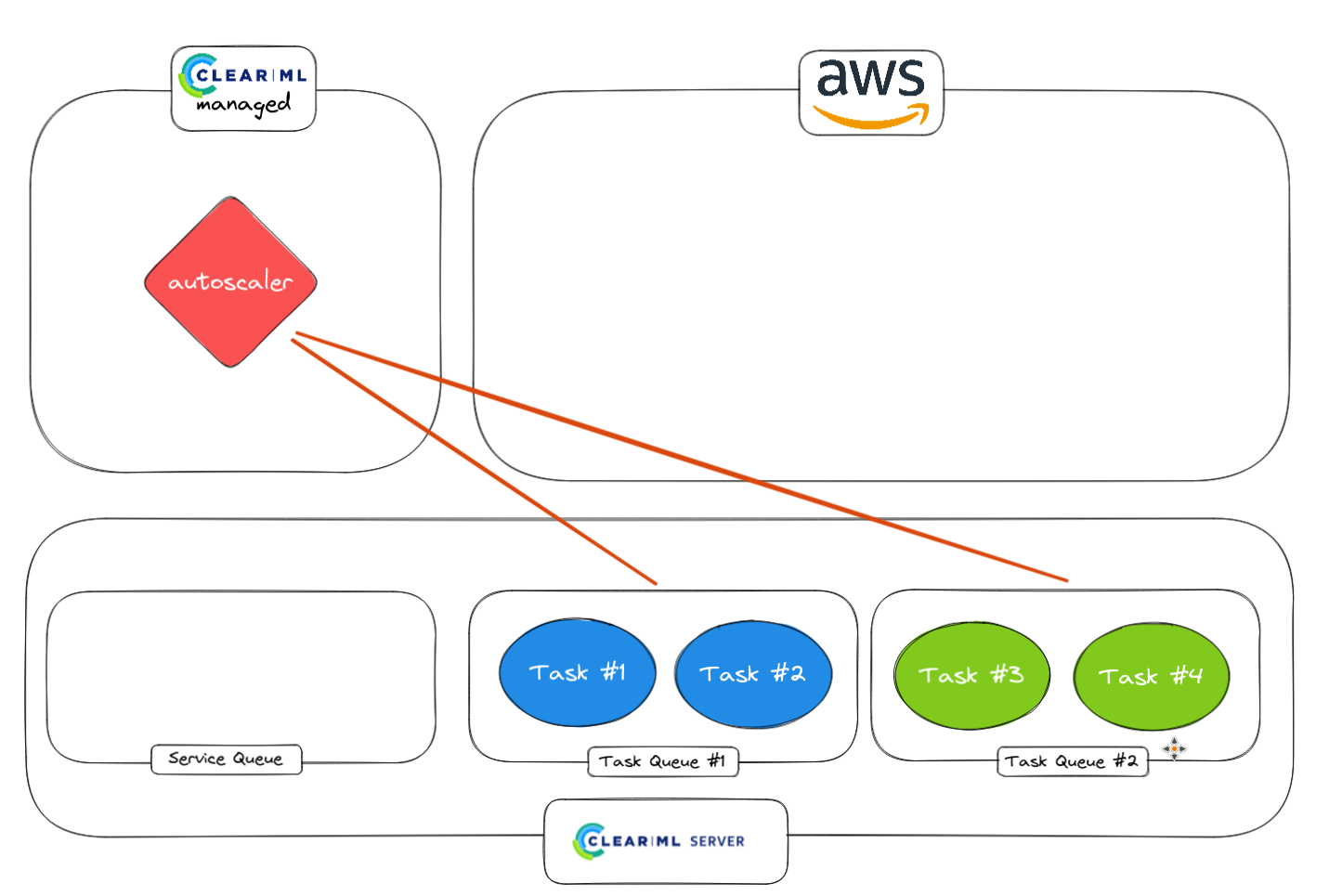
2. 使用 autoscaler worker 监控普通任务。
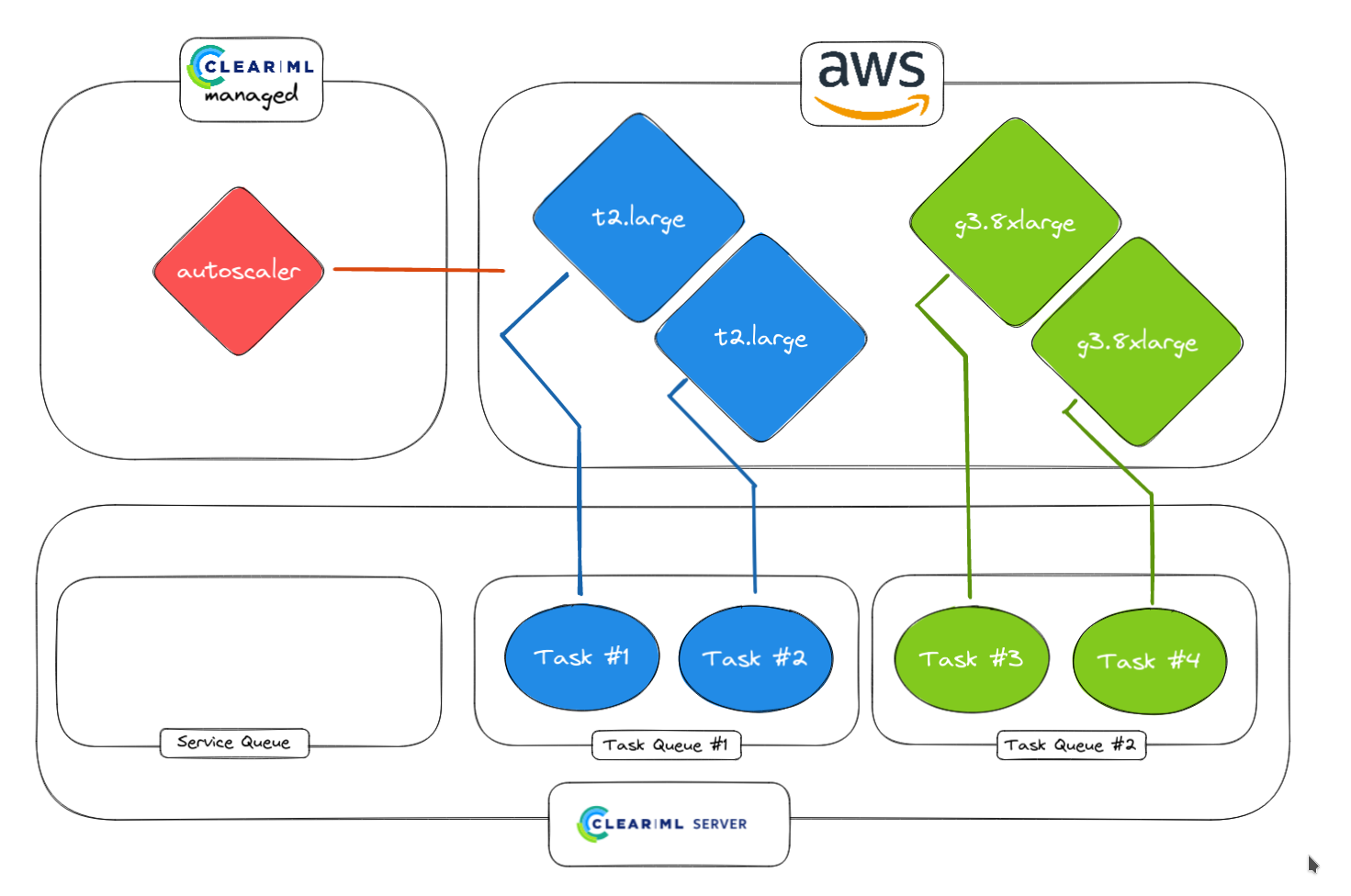
3. Autoscaler 检测到任务并在 AWS 中启动 worker。不同队列可以对应不同的实例类型(例如 CPU 队列和 GPU 队列)
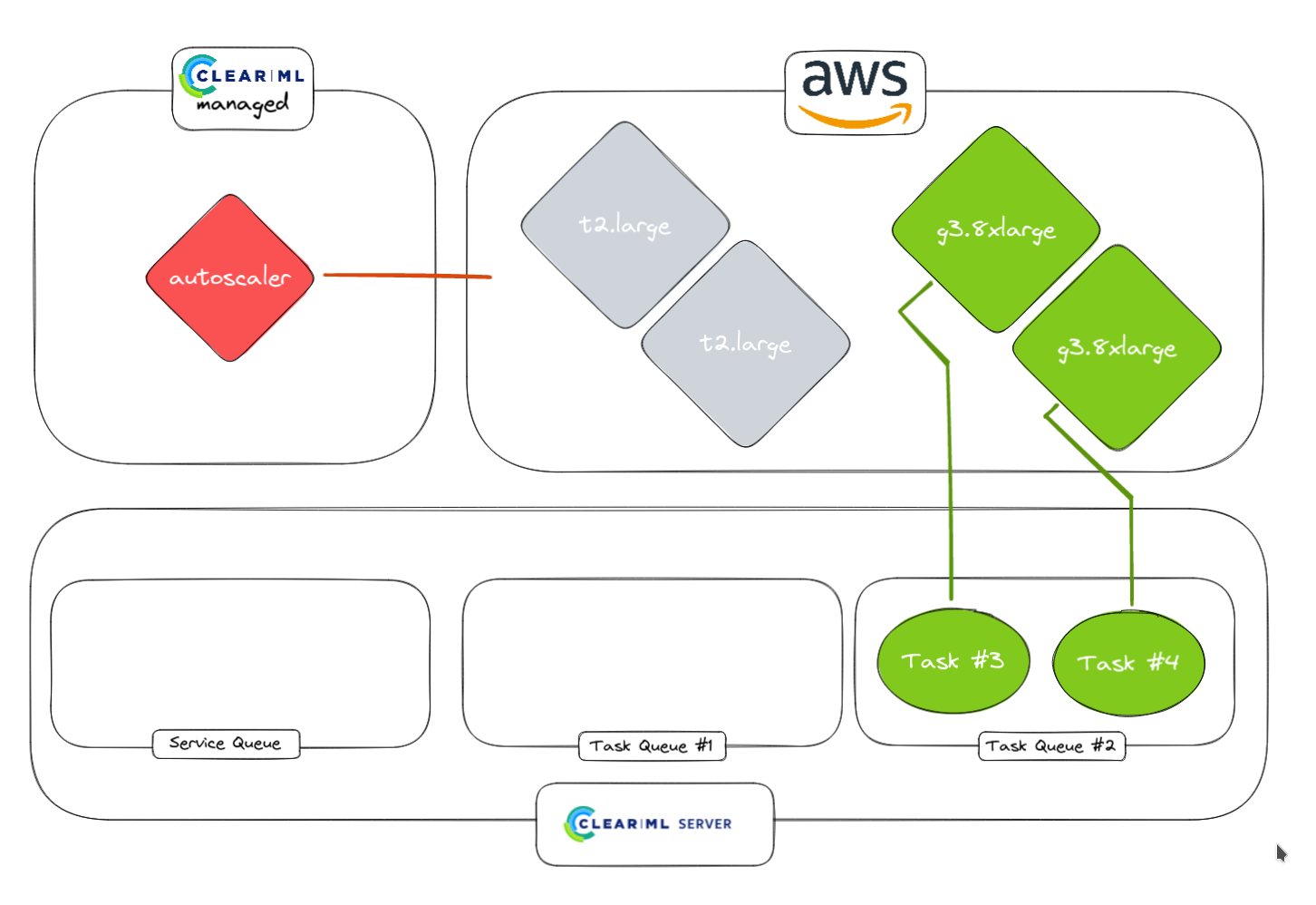
4. 较快的任务完成后,worker 将空闲一段时间,该时间由用户选择。如果 Task Queue #1 中有任何任务进来,它们将立即开始
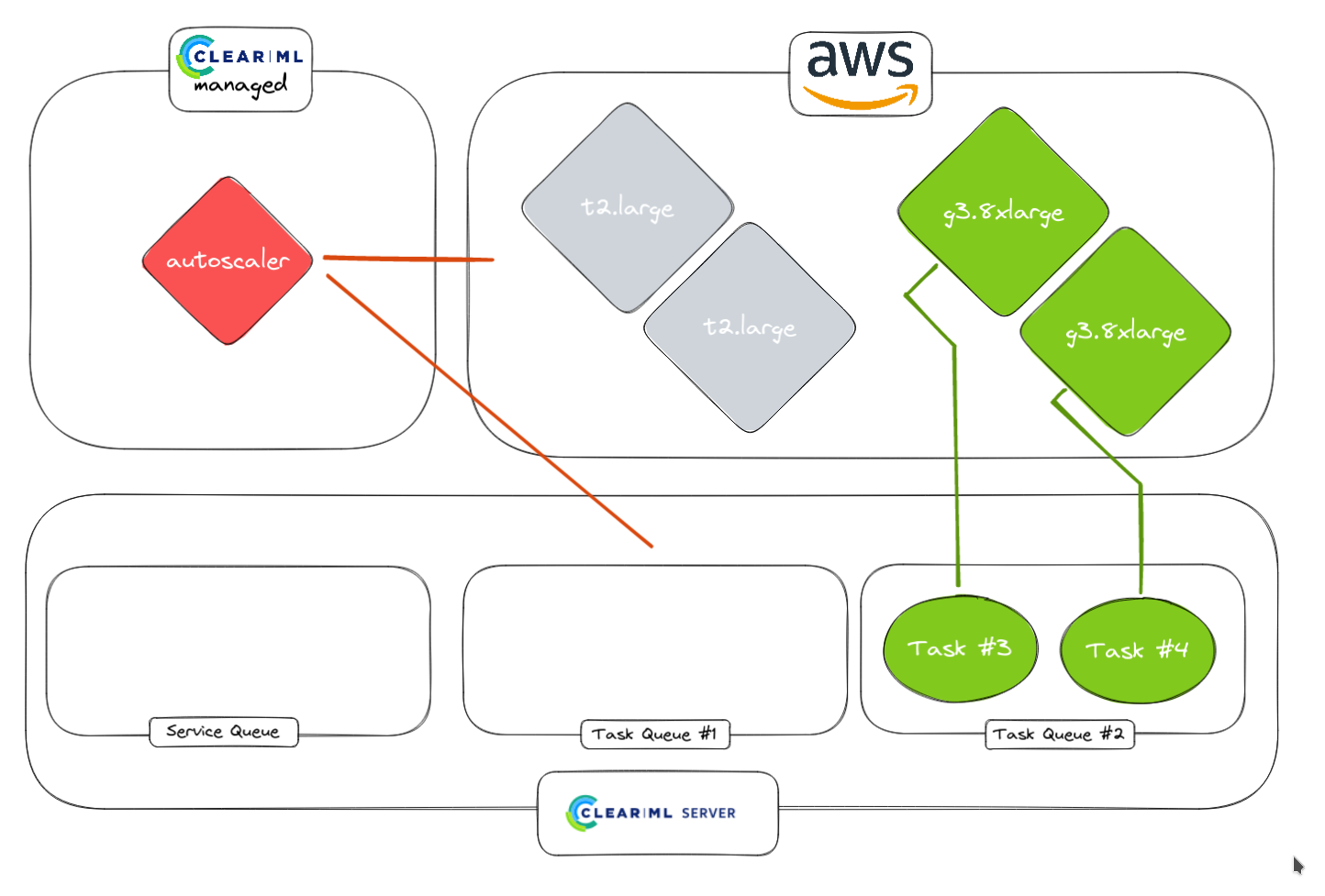
5. Autoscaler 没有检测到其他任务
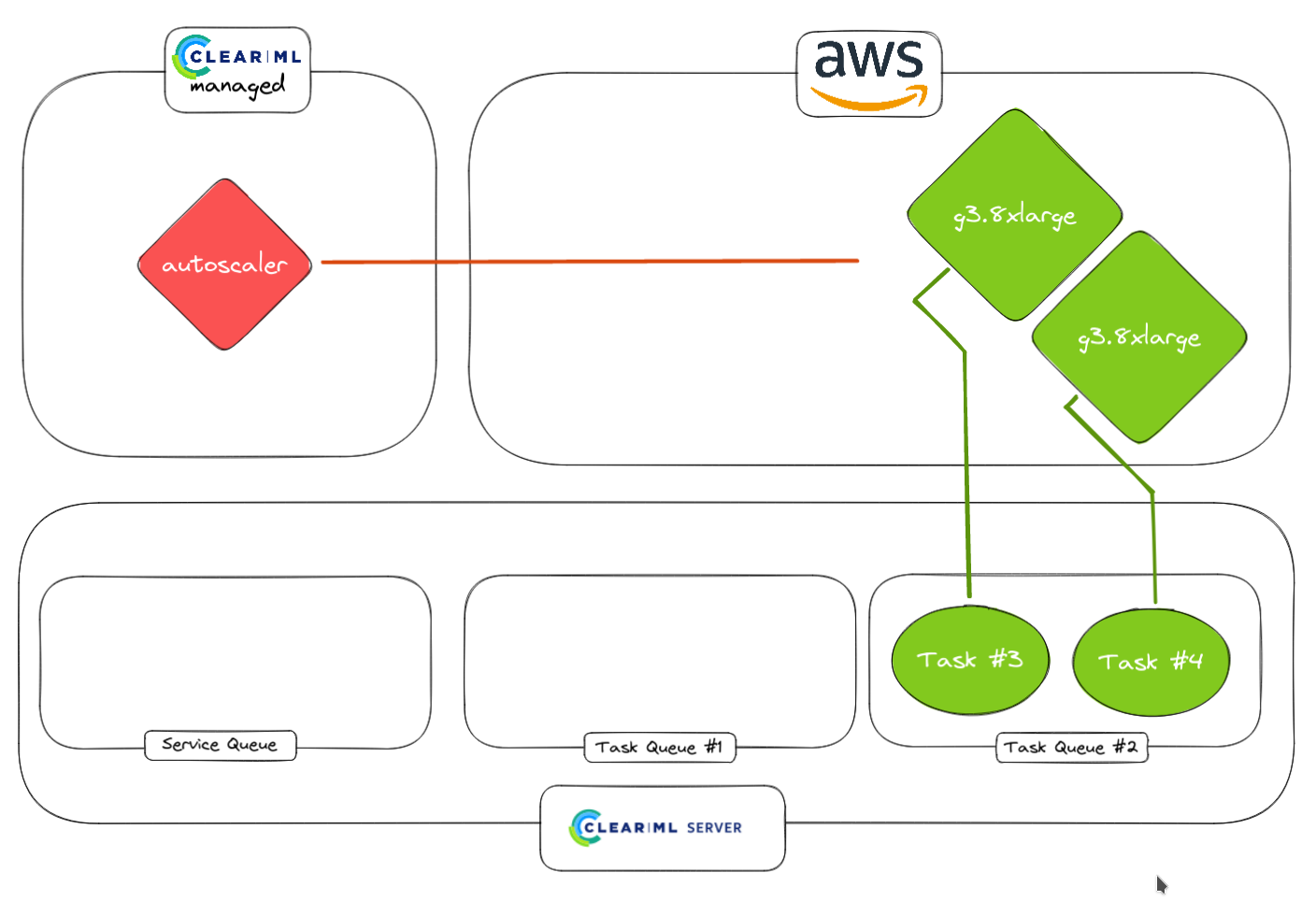
6. 如果需要,空闲 worker 会被关闭。正在运行的 worker 当然会保持运行
