如何使用持续学习流水线来保持生产中 AI 模型的高性能
原文发布于 由 Elie Zemmour,算法开发人员,WSC Sports。经作者授权转载。
WSC Sports 的算法团队面临一个挑战:我们的计算机视觉模型在动态环境中运行时,如何保持高质量的结果?尤其是在我们的案例中,新数据可能每天都会出现,并且在视觉上与已经训练过的数据不同。有点让人挠头,对吧?嗯,我们已经开发了一个系统,恰好能做到这一点,并且显示出了卓越的结果!
但是在介绍我们的模型或解释我们面临的极端数据变化的原因之前,让我们首先了解我们的使命。在 WSC Sports,我们使用人工智能技术,通过动作检测和事件识别算法,从体育赛事直播中自动生成视频集锦。我们的主要任务之一是检测重播并确保它们与相应的事件关联。
重播识别可能看起来是一项简单的任务,然而,在观看事件时,尤其是在体育赛事直播中,我们的大脑会利用多年的经验形成的先验知识。例如,在电视上观看体育赛事直播时,我们能够区分在不同时间发生的两个不同事件,以及从不同角度或以不同速度呈现两次的同一事件。此外,我们还能识别特殊的视频编辑模式。对于重播事件,它们通常被图形叠加层环绕(图1)。

图1 – 慢动作重播后跟随图形叠加层的示例
构建解决方案模型
这类识别任务需要理解广播惯例。作为人类,我们能够理解广播模式,而无需明确学习它们。然而,即使对于最先进的机器学习任务,这也可能非常具有挑战性。为了帮助我们解决这个问题,我们开发了一个重播检测模型,它 学习体育赛事的广播模式以确定重播事件。
正如我们之前提到的,重播是一个已经发生过的事件,并从不同的视角(角度、速度、缩放、解说员评论等)再次呈现给观众。重播检测模型旨在学习体育赛事中的所有这些广播模式,以确定视频中的重播事件。
该解决方案包括一个旨在确定每张图像中最佳空间特征的卷积神经网络 (CNN) 主干,以及一个学习视频广播时间特性的长短期记忆 (LSTM) 模型(图2)。利用模型的输出,我们能够确定重播动作及其精确的开始和结束时间,从而得到非常准确的重播片段(图3)。
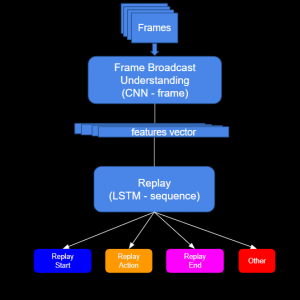
图2 – 模型架构

图3 – 足球重播视频片段的结果
在投入生产后,该模型运行得非常出色,性能很高。
然而,WSC Sports 正在快速发展,我们经常签约新客户,因此我们的模型需要处理频繁的变化。每个新客户都带来新的运动数据,或现有运动的扩展,包括新的联赛和需要考虑的新变量。广播惯例在不同运动之间变化很快,而且在不同联赛、锦标赛和国家之间显然也不同。在某些情况下,附加数据与我们模型过去处理的数据(新动作、背景、广播模式等)差异巨大。
数据变化的另一个原因来自现有联赛,它们可能会在赛季之间改变其广播模式。例如,一些广播公司可能开始为重播边界使用不寻常的图形(图4)或根本不使用图形。另一个例子是专家和解说员直接在重播视频上进行绘制,例如在球员身上绘制箭头或圆圈(图5)。所有这些极端数据变化会导致性能下降。
突然间,我们最初备受赞誉的模型变得不够好了。我们不得不迅速响应并重新训练模型,以支持所有新的运动和联赛。随着我们不断发展,重新训练模型的需求变得更加频繁,并且需要耗费大量时间:监控生产中的性能,标记误检测,重新训练模型,以及在所有运动和联赛上测试其性能。


图4 – 重播边界的不寻常图形


图5 – 解说员在视频上绘制
为了应对所有新变化,并保持客户期望的高水平支持和性能,我们必须找到一种自动化解决方案 ,使我们能够快速有效地应对数据漂移。
流水线平台
既然我们已经了解了模型架构和输出,我们就可以介绍我们用于自动开发和改进模型的自动化流水线解决方案。
我们选择了ClearML 平台来开发流水线,因为它能够轻松创建独立的在远程容器上运行的任务。对于每个任务,我们定义其在流程中的层次结构 以及任务所需的精确环境。因此,我们可以为每个任务选择不同的机器,减少昂贵资源(例如 GPU)的使用。此外,我们将耗时的任务转换为多个并行任务,从而呈指数级加速了流程。
该平台保存了每个任务的输入和输出记录。它还跟踪代码版本、数据和 docker 环境。所有这些能力使得自动化过程快速可行。
流水线架构
该流水线包括几个主要流程:数据创建、模型训练、评估、部署和监控。当层次结构中所有前置步骤完成后,每个流程都会自动触发(图6)。

图6 – 流水线 流程
数据创建
此步骤包括获取在生产中被错误分类的视频,通过半自动化流程对这些视频进行标记,然后将其剪切成样本。最后,将它们上传到准备好用于训练(训练集、测试集、验证集)的数据集。(图7)。

图7 – 数据创建步骤
我们使用负责从数据库中检索新视频以改进现有运动的查询。数据库中包含已按运动和联赛分类的视频。此外,我们还记录了模型在生产中的错误预测(经过手动审查)。
然后我们使用一个基础的图形检测模型,它能够标记大多数样本的图形边界。该模型在检测视频中的图形边界方面具有非常高的召回率,但它没有上下文;它无法判断重播是否开始/结束,也无法识别之前提到的任何其他时间模式。然而,我们将这个简单的模型作为在手动概览上下文中的辅助工具。它有助于将视频剪切成代表重播内容、开始、结束以及显然还有负样本的片段。
自动标记阶段结束后,会得到一组准备好被剪切并上传到数据集的视频。我们通常也会剩下少量在自动标记过程中置信度较低的视频,我们会将它们发送进行手动审查。大多数情况下,流水线会继续进行后续步骤(训练、评估等),而无需这些样本。
模型训练
此过程包括使用不同的超参数进行训练,以在测试集上实现最佳性能。使用此流水线帮助我们探索各种实验,更重要的是帮助跟踪所有结果和数据版本。通过并行执行任务,我们能够进行更多实验,探索多个超参数并选择最佳模型。
起初,训练模型可能需要几天时间。然而,在用一个非常大的数据集训练模型后,我们发现不再需要训练主干网络。我们看到,时间特征是频繁变化的特征,并且在大多数情况下,使用相同的空间模型来训练时间模型可以获得非常高的性能。仅将训练好的 CNN 模型用作特征提取器(图8)已经足够好,并且允许我们将其用作可以并行执行的预处理阶段。这使得训练过程快得多(从几天缩短到不到一个小时)。此外,仅在 CNN 上进行推理不需要带有 GPU 的机器,从而节省了大量费用。

图8 – 流水线 带有特征提取的流程
为了强调分离特征提取步骤的影响,在包含 20,000 个片段的新运动上训练模型,在之前的流水线中需要 20 小时,而现在只需要 3 小时。此外,GPU 机器的使用量显著减少。
| 流水线解决方案 | 使用的机器 | 总流水线时间 |
| 同时训练 CNN+LSTM
(图6) |
15 小时 GPU,1 台机器 (p2.xlarge)
100 小时 CPU,20 台机器 (m6i.xlarge) |
20h |
| 特征提取
与训练分离 (图8) |
1 小时 GPU,1 台机器 (p2.xlarge)
200 小时 CPU,100 台机器 (m6i.xlarge) |
3h |
评估
评估阶段在与生产相同的环境条件下执行,使用最优模型。在此阶段,我们使用我们的验证集(或我们称之为“黄金集”),这是一个代表我们关注的所有运动的联赛和广播公司的大型视频集。
在此阶段结束时,会生成一份详细报告,指出每个运动和广播信号(重播开始、重播结束、重播动作信号以及由所有信号创建的片段)的联赛弱点。例如,(图9)我们可以看到自动化过程后,篮球联赛的评估结果。
各信号召回率 – 按运动
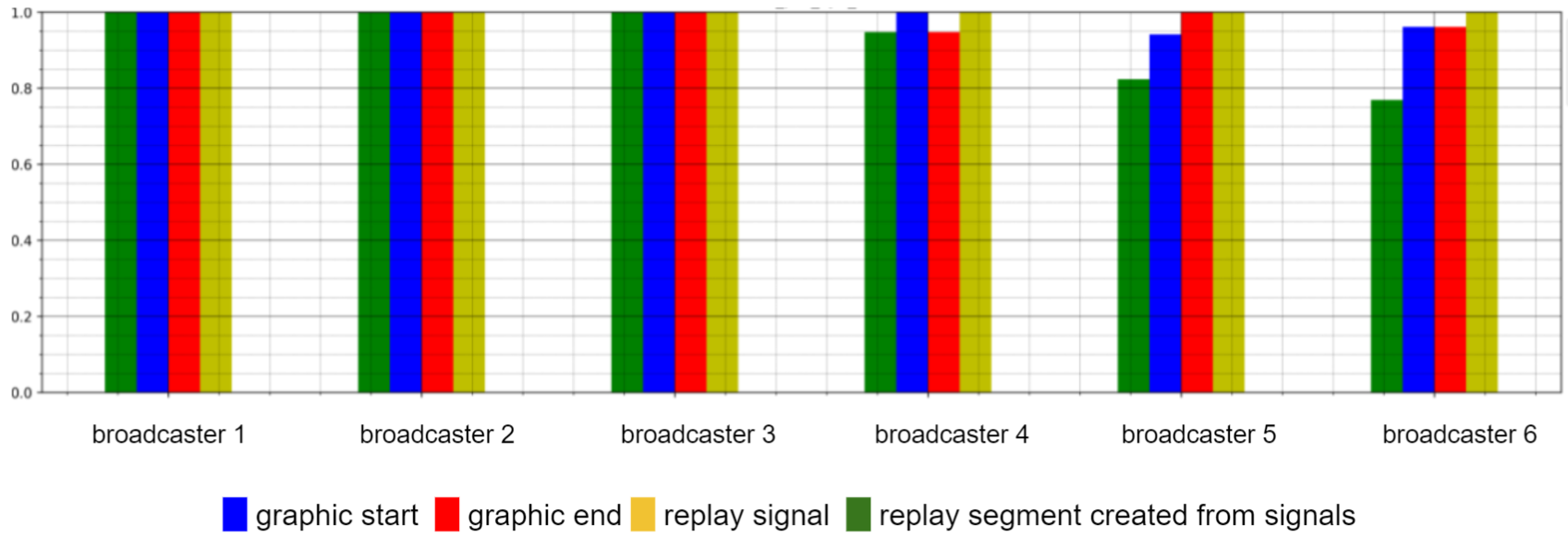
图9 – 模型结果
在此阶段,我们定义了几项测试,以确保我们能够提高有问题联赛的召回率和精度,并保持其他联赛的质量。
部署&监控
在成功评估结果后,我们将新模型部署回生产环境。我们使用传统的 BI 平台监控模型性能。此步骤与 ClearML 自动化流水线分离,但在未来需要时触发持续学习过程是必要的。
总之,在开发了我们的持续学习流水线后,我们能够支持生产中快速的数据变化。我们取消了不必要的手动步骤,并并行化了所有可能的任务(视频标记、视频剪切、后期逻辑)(图10)。结果是,我们可以自动化一个以前需要几天才能完成的过程,将时间缩短到只需几个小时!
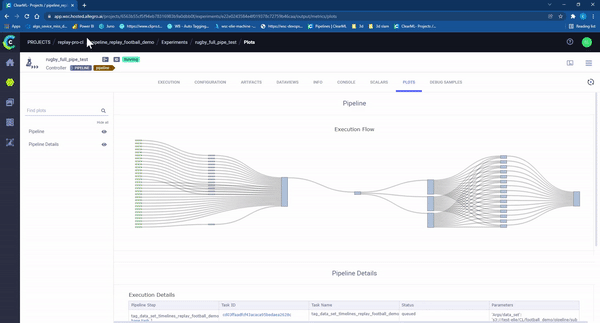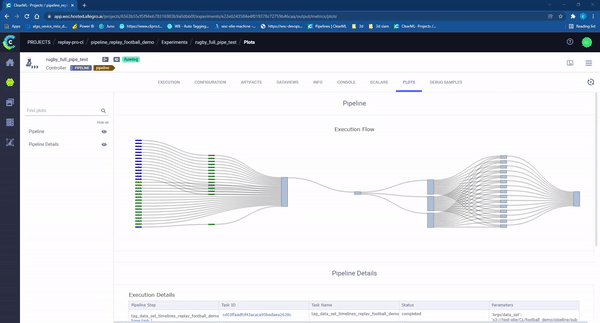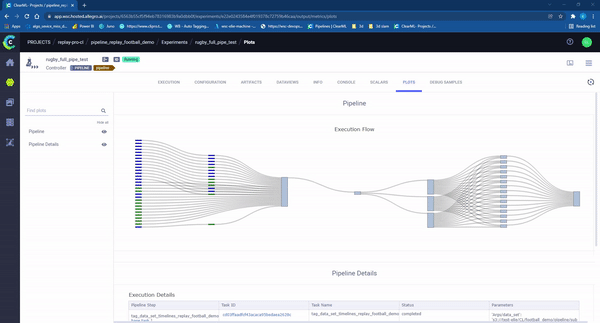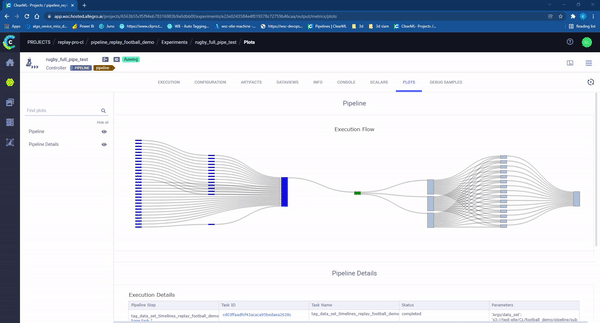
图10 – ClearML 流水线“运行中”。每个矩形代表在机器上运行的一个独立任务。颜色代表任务的状态:浅蓝色:等待开始,绿色:正在进行,蓝色成功完成,红色:失败。
那么,使用这条流水线我们取得了哪些成就?
- 显著缩短了开发周期
- 分割成子任务并并行运行,无需担心手动错误
- 易于执行实验和搜索超参数
- 每个实验都有文档记录且易于访问
