让我们使用 Sklearn 和 ClearML 在一个真实用例中进行超参数优化。
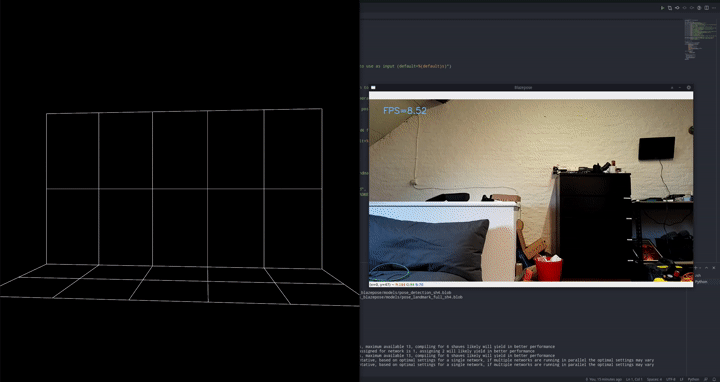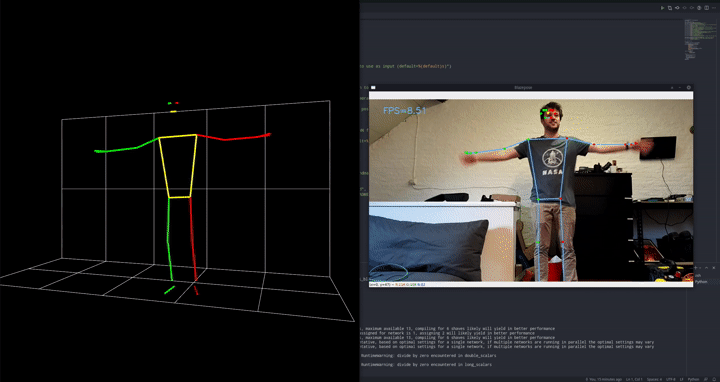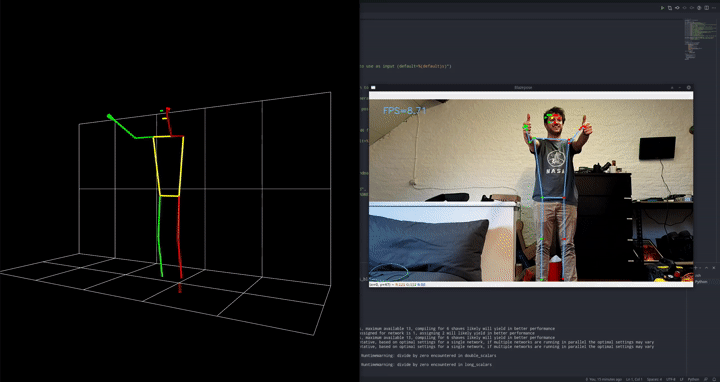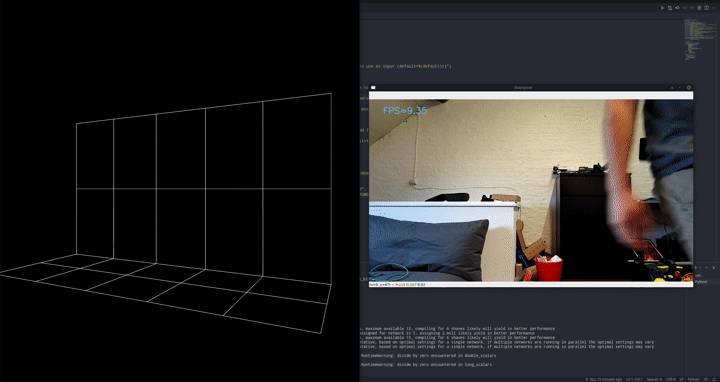
这是我们超参数优化(HPO)三部曲的第三部分,如果您还没有阅读前面解释 ClearML 如何进行 HPO 的两部分,您可以在此处和此处找到它们。
在这篇博客文章中,我们将重点关注如何将我们学到的知识应用于一个“真实世界”的用例。
用例
对于我们的示例用例,让我们选择我们作为大型项目的一部分正在进行的工作(即将上线我们的YouTube 频道!)
目标是使用摄像头检测俯卧撑。

我们采用两阶段方法,首先使用现成的姿态估计模型对图像进行预处理。在本例中,我们选择了 Google 的 blazepose,它是其 mediapipe 框架的一部分。我们使用 DepthAI OAK-1 摄像头和加速器在设备上运行此姿态估计模型。由于我们将该模型作为预处理步骤直接使用,这是一个完美的设置!

该模型将输出关键点,就像一个数字骨架,指示它认为人的肢体在空间中的位置。反过来,我们可以使用这些关键点作为输入,输入到一个更简单的分类器中,该分类器将告诉我们当前是处于俯卧撑的向上还是向下姿势。
训练过程
由于我们使用预训练模型进行姿态估计,所以我们只需训练我们的姿态分类器。训练过程如下:
- 获取俯卧撑向上和向下姿势的图像
- 对这些图像运行姿态估计器以获取关键点
- 只选择我们感兴趣的关键点
- 分割成训练集和测试集
- 对关键点进行数据增强以获取更多样本
- 训练一个 Sklearn 分类器,将关键点分类为向上或向下姿势
这些步骤大致对应于控制主要流程的以下代码片段:
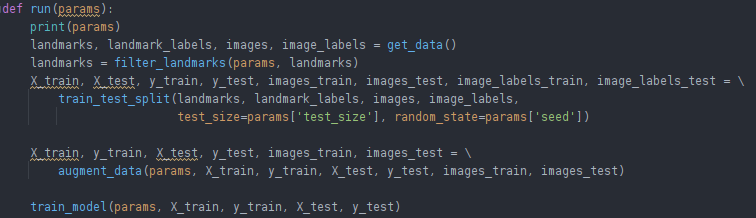
为了让我们的训练过程由 ClearML 实验管理器跟踪,我们已经做了三件事。
1. 添加两行魔术代码
要启用 ClearML 实验跟踪,我们只需添加这两行代码。
![]()
就这样!
2. 连接超参数
为了在实验过程中保持组织性,将尽可能多的参数保存在一个集中的地方是个好主意。大多数人通过使用 `config.py` 文件、(全局)字典/对象或使用命令行参数并解析它们来实现。
在我们的例子中,我们通过将超参数(可以是任何东西,如训练集与测试集大小、要选择的随机种子或特定的模型参数)放入字典中来跟踪它们。这种集中管理在实验时是最佳实践,即使不使用实验管理器也是如此。
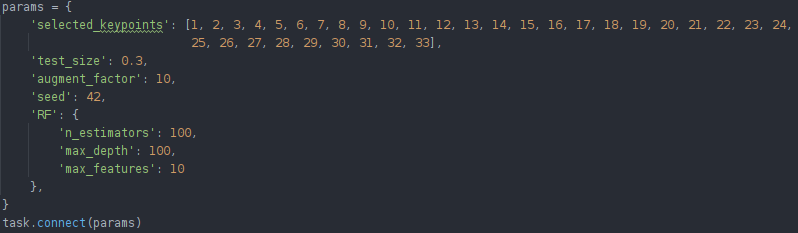
要让 ClearML 知道我们正在使用这些参数,我们只需调用task.connect(dictionary)。现在这些参数已被记录,并且可以稍后更改,我们将在下文看到。
3. 连接标量
超参数是输入,而我们的标量是输出。标量可以是任何我们期望的有意义的数字或指标。这些在 ClearML 生态系统中占有特殊地位。
大多数情况下,我们期望的标量是显示模型性能的指标。准确率、F1 分数、AUC 分数、损失等。
在本例中,我们正在训练一个已使用内置的 sklearn 函数 roc_auc_score 进行评估的 sklearn 分类器。要让 ClearML 知道这是一个标量,我们只需将其报告给当前活动任务的日志记录器。

注意:sklearn 分类器不使用迭代,因此您可以将迭代值设置为 0。
实现超参数优化
既然我们已经将训练任务的输入和输出记录到实验管理器中,我们就可以开始尝试这些参数的不同值了!
ClearML 可以更改之前任务的超参数并重新运行该任务,这次是在 task.connect 行将新的参数值注入到原始代码中!从那时起,原始参数值就被更改了。
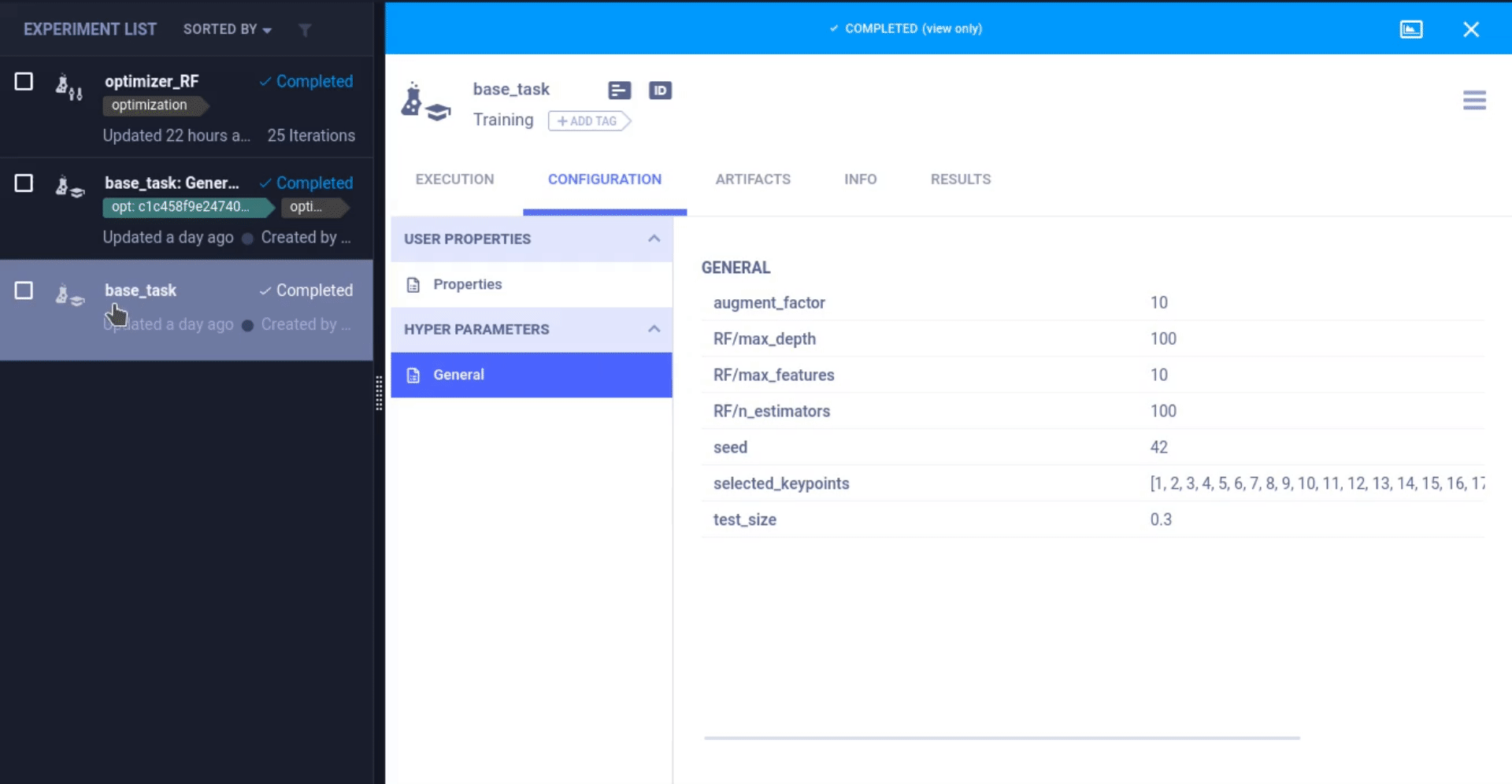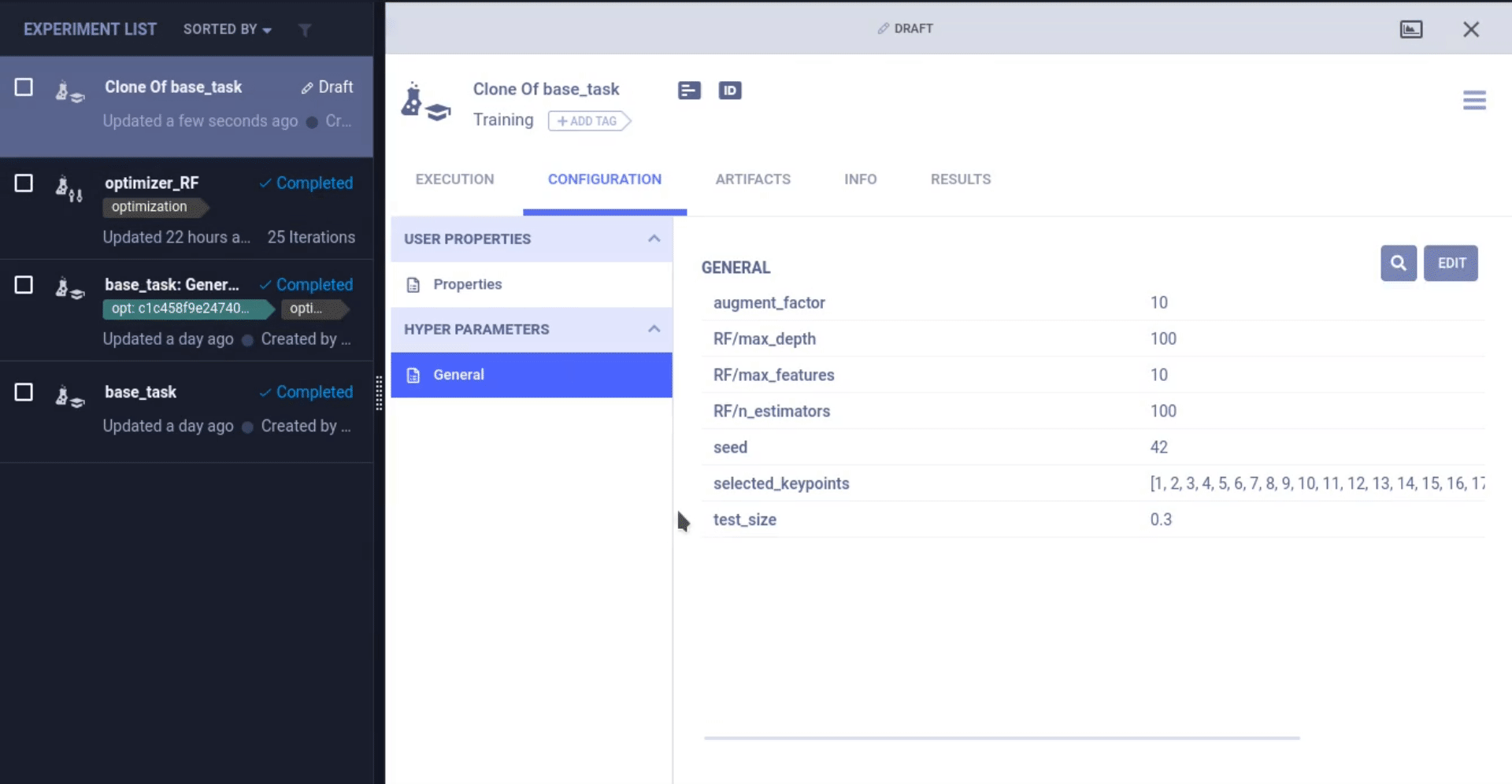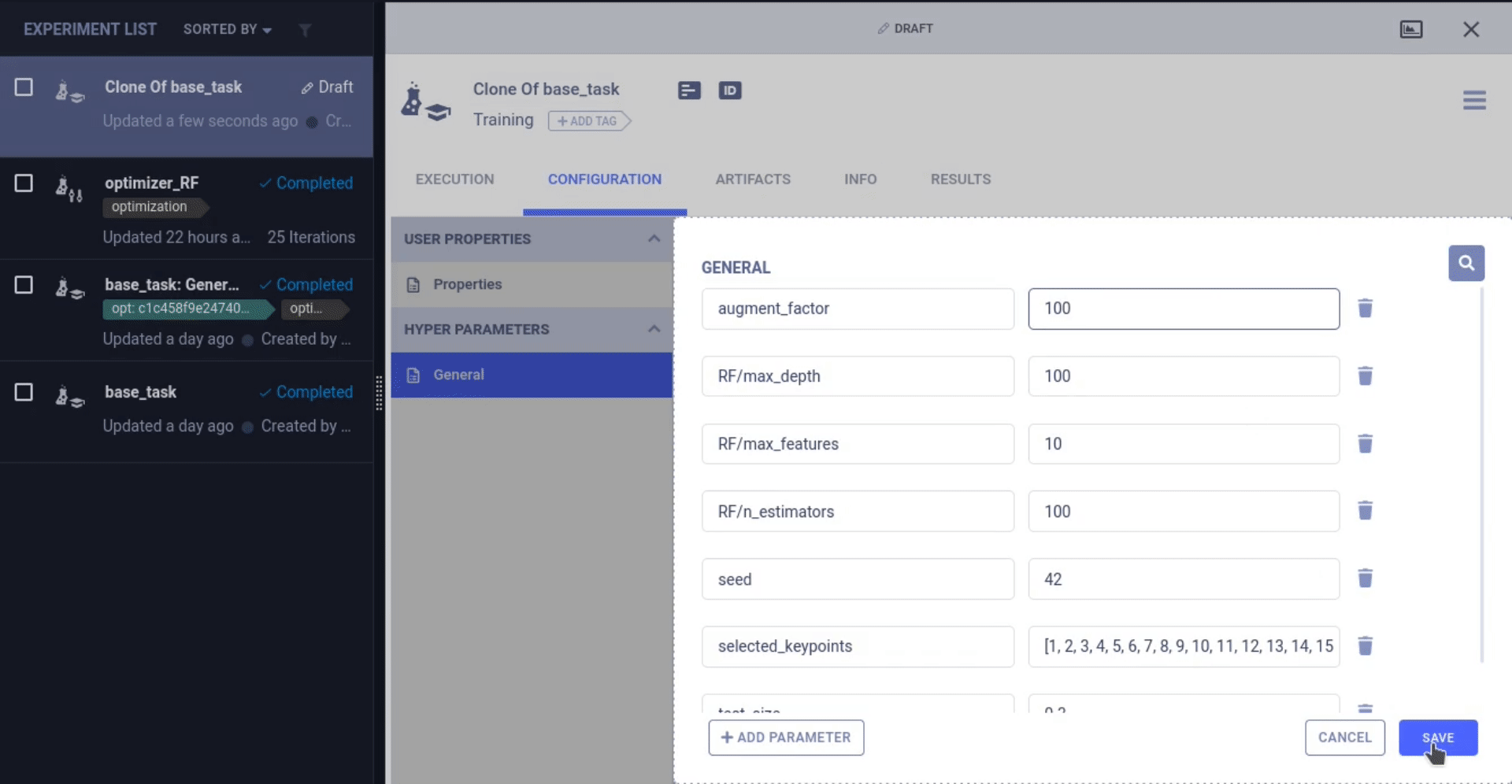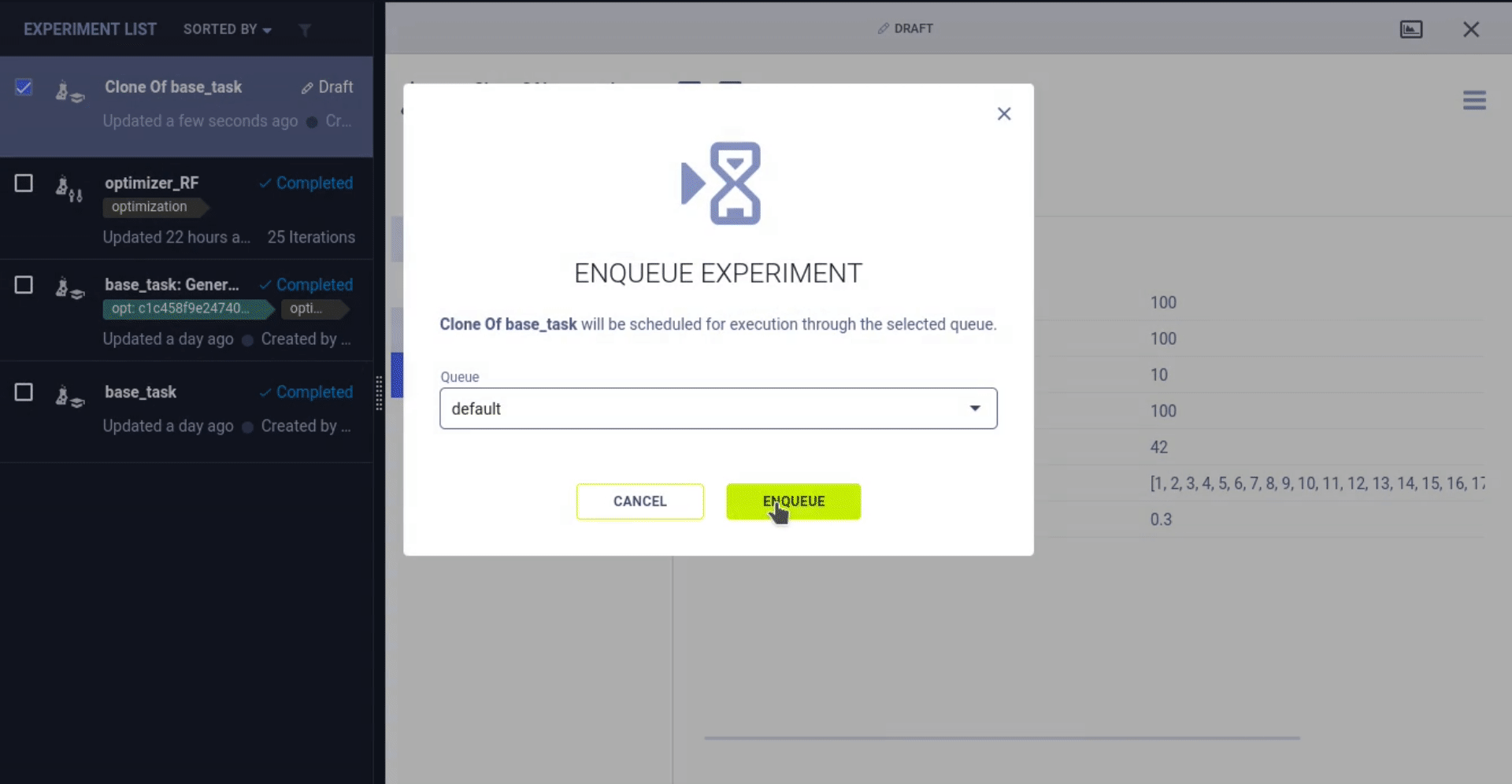
这就是参数与代码分离的强大之处,我们可以将像 optuna 或 BOHB 这样的 HPO 优化器应用到我们的训练脚本之上,甚至无需更改任何代码!
我们只需要编写一个(单独的)优化器任务:
- 初始化 clearml 优化器任务
- 为我们要优化的参数定义参数范围
- 创建优化器
- 本地或远程运行并等待其完成
如果您使用的是任何付费层级,您还可以直接从 UI 启动此过程,并通过美观的仪表板进行监控!
有关使用哪些设置的更详细解释,请参阅我们的上一篇博文!在这里,我们可以选择 RandomSearch,因为训练随机森林花费的时间不长,或者选择贝叶斯优化以更有确定性地达到最佳组合。
在这种情况下,使用 Sklearn,将迭代次数作为我们的贝叶斯优化预算是不合理的,而且由于 Sklearn 分类器是单次训练模型,早停是无法进行的。所以我们通过设置 total_max_jobs 限制任务数量,并将其余设置为 None。
制作一个 sklearn 样板
最后,我们可以扩展这个训练脚本和优化器,使其更通用一些,作为一个任何人都可以使用的好样板。
我们修改了训练脚本本身,以支持许多不同的 Sklearn 分类器
并将这些参数添加到我们的参数字典中
现在,使用哪种分类器本身就是一个参数。
对于优化器脚本,我们可以为每个 sklearn 分类器单独运行一个优化器(以便不优化当前分类器未使用的参数),稍后使用 WebUI 的比较功能比较它们的最佳分数。
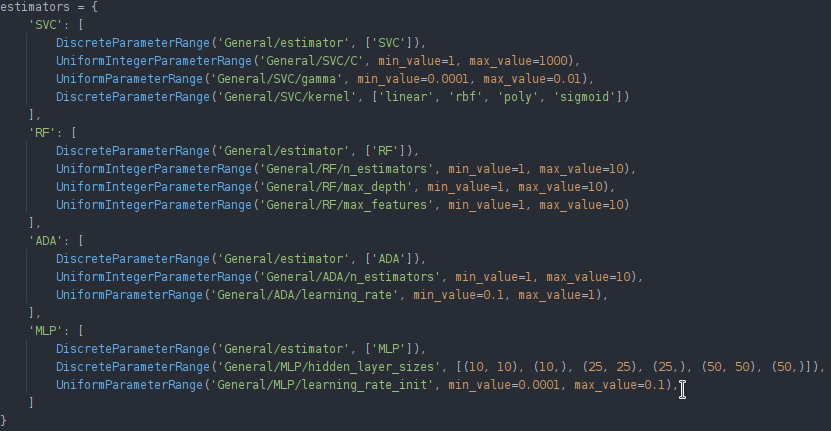
我们可以通过为不同的分类器设置多个不同的参数网格并遍历它们来启动单独的优化器来修改我们的优化器脚本。您可以在此处找到这些示例的代码。
查看结果
回到 Web UI 中,我们现在可以分析我们的结果并比较模型了。对于每个优化器,我们都会得到两张图表和一个表格。
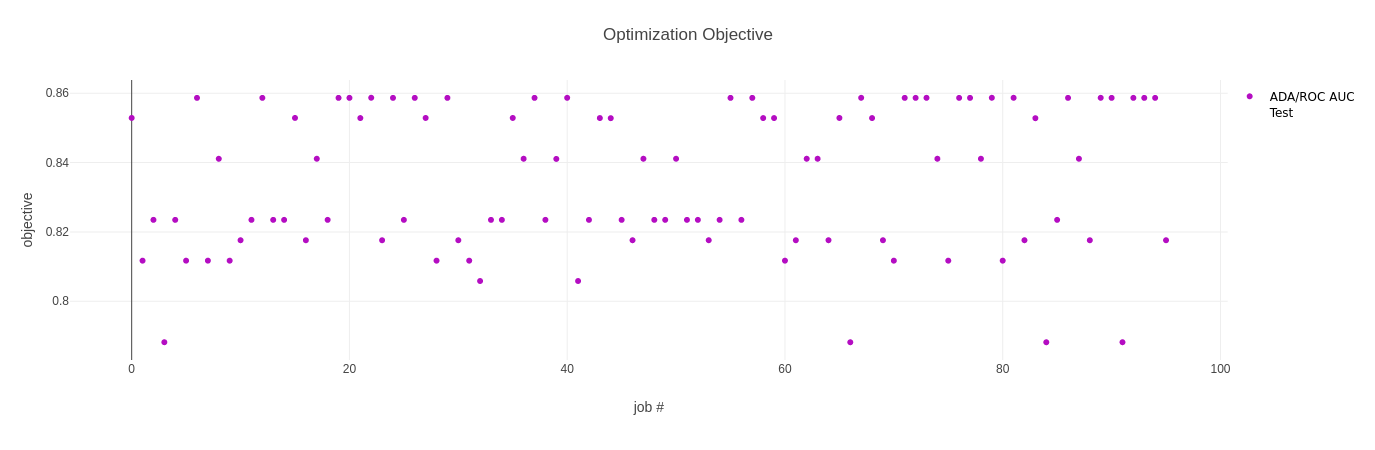
第一张图表显示了所有试验的目标指标,在我们的例子中是 ROC AUC 分数。
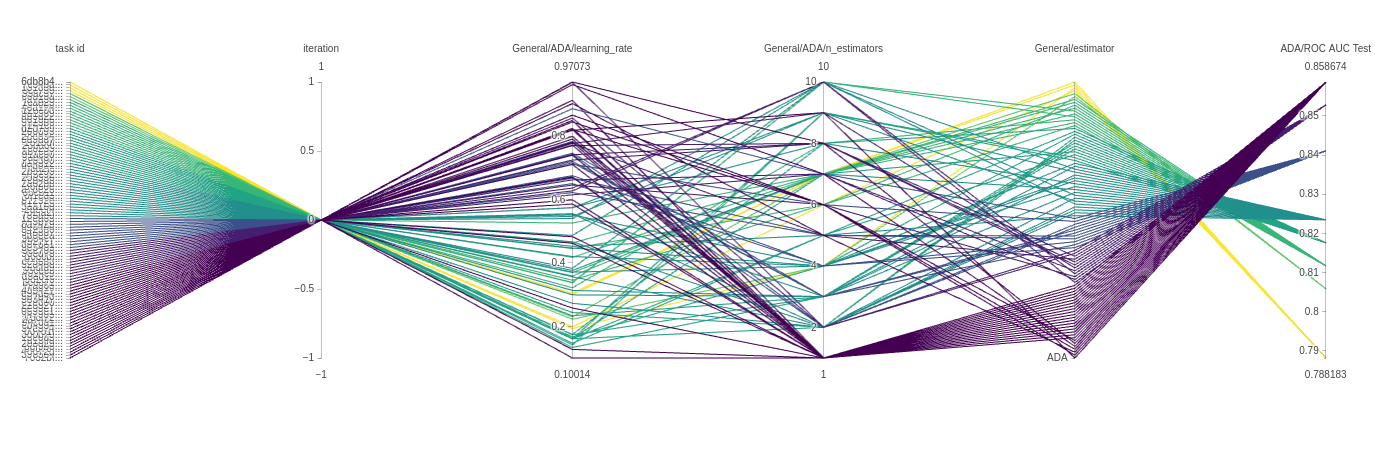
下一张图表是平行坐标图。这可以告诉我们很多关于模型的信息,并为我们将来如何设置参数提供直觉。下面的图表来自 ADAbooster 分类器。
每条线代表一次具有特定参数组合的实验运行。每条线都有颜色,可以从左到右读取。每个垂直轴代表该实验运行的一个参数。
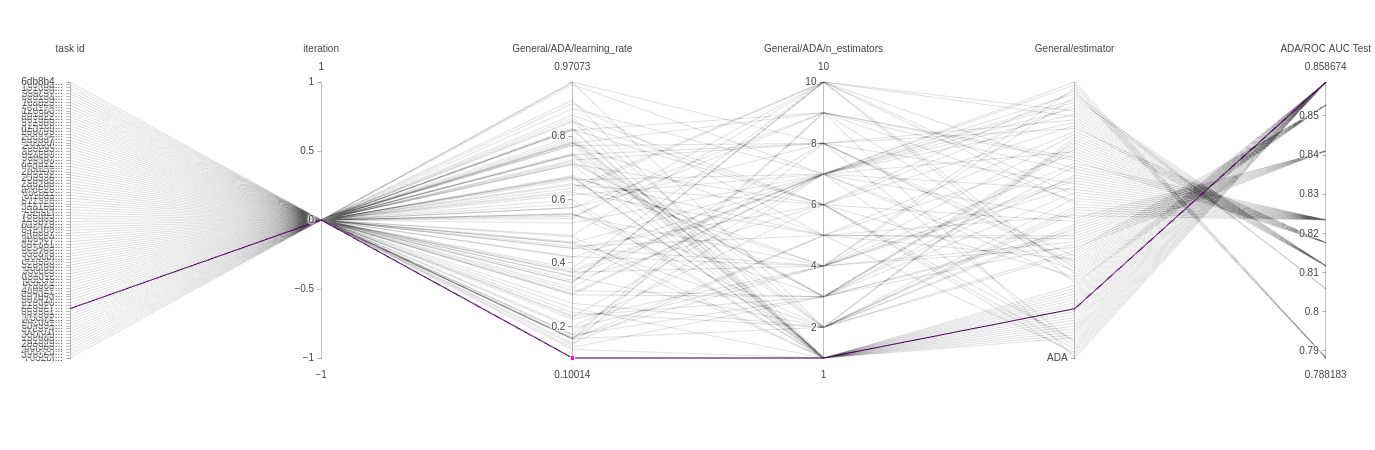
在我们的例子中,迭代次数总是 0,所以所有实验都经过那个点。但接下来的两个垂直轴更有趣。正如我们从颜色中看到的那样,大多数表现良好的试验使用了较高的学习率和单一估计器,但也有使用低得多的学习率达到同样结果的模型,非常有趣!最后,因为我们也将分类器类型本身作为一个参数使用,所以我们得到了另一个只有一个值的轴,因此所有试验都按顺序经过那里。
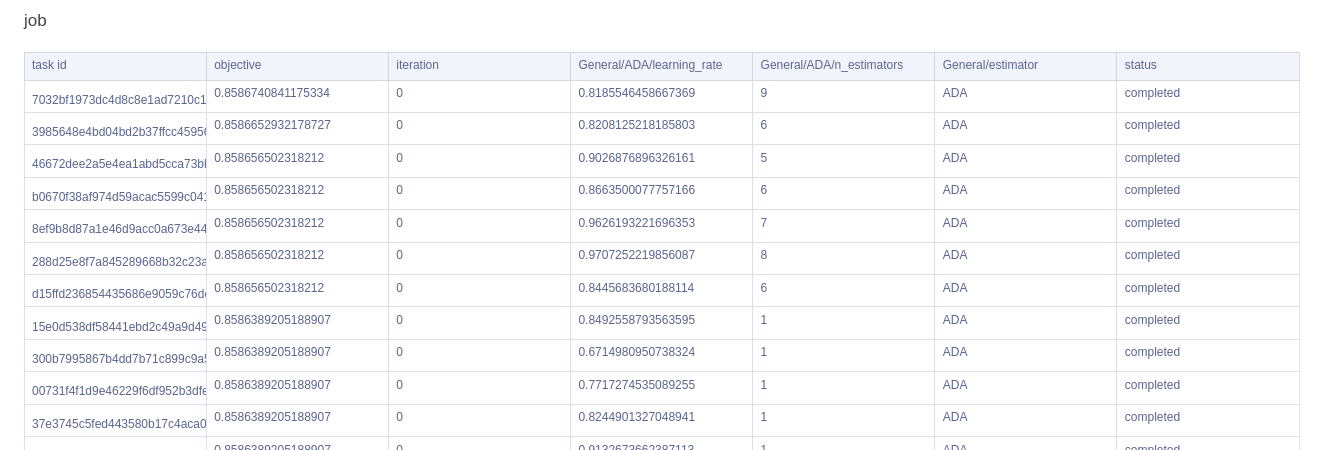
最后,我们有一个方便的表格,它提供了我们所有试验的快速概览,按最高目标指标排序。
我们希望您能看到在实验跟踪的基础上使用 ClearML HPO 功能的强大之处。如果你已经在使用 ClearML 跟踪实验,它使得快速启动 HPO 运行变得非常容易。请参阅我们的其他HPO 博文,了解关于 HPO 本身以及何时使用哪些设置的更多信息。
