作者:Kim Ann King,ClearML 内容策略主管。

最近,我们有机会采访了 Daupler 的高级数据科学家 Heather Grebe。Daupler 提供 Daupler RMS,这是一个 311 响应管理系统,被北美和国际上 200 多个城市和服务组织使用。该平台帮助公用事业、公共工程和其他服务组织协调和记录响应工作,同时减少工作量并收集对响应操作的洞察。借助 Daupler 的技术,组织可以提高其响应能力并增强客户的信心。公司的目标是让客户更轻松地专注于其核心使命:为客户和社区提供关键服务。
Heather 解释说,该平台处理“标准和运营关键的 311 服务请求,这些请求需要城市或公用事业部门响应,例如自来水主管道破裂、下水道堵塞、交通信号灯故障或一般基础设施损坏。”
Daupler RMS 的基础是 Daupler AI,它可以根据为请求获得的最后一条数据,按顺序收集和分析各种相关数据模式,应用客户级别配置的定义规则,并启动和监控正确的响应协议及由此产生的数据。为此,Daupler AI 接收来自多个来源的输入,例如客户电话、短信、地理标签、照片、电子邮件、网络表单、社交帖子以及急救人员报告和基础设施警报。该系统使用 Daupler 的专有算法分析数据,该算法已在许多公用事业和其他服务组织的数百万条请求记录数据池上进行训练。然后,它将数据分类为单个事件或更大规模的事件,并将信息路由到适当的部门。
所有这些数据收集都由机器学习系统处理,这是 Heather 工作的一部分。她与数据工程师 Carly Matson 一起组织数百万个数据样本,有效地标记最有优势的请求子集,管理 15 个(还在增加)ML 模型,并整合来自人机协作系统组件的反馈。在如此广泛的职责范围和精简的人员配置下,她如何管理巨大的工作量?简单的答案是使用 ClearML 进行自动化。Heather 解释说:“将我们有限的时间手动花费在重复性任务或编写样板代码上,既不高效也无效。这就是为什么我非常热衷于自动化任何可以自动化的事情,并进行适当的监控。”
为了实现这一点,Heather 使用 ClearML Data 创建、管理和版本控制数据集,使用 ClearML Pipelines 简化和连接多个流程,使用 ClearML Orchestrate 处理我们所有的 worker、队列和作业调度,并使用 ClearML AutoScaler 在需求高时启动机器(然后在没有任务需要执行时关闭它们以降低成本)。
“ClearML 使我们能够快速搜索最佳数据以提高模型的鲁棒性,对其进行标注,使其通过训练流水线,与我们的生产状态进行详细分析和比较,然后进行部署准备——所有这些都可以在一两天内完成。”
– Heather Grebe
在 Daupler 实现 ML 流程自动化
Heather 工作系统的一部分是一个分层文本分类系统,它包含许多有条件地协同工作的不同组件。以下是她关于自动化 ML 流程工作方式的看法:
“比方说,我们确定了一个需要捕获的新概念,以便满足客户的多样化需求,并且我们想构建一个新的模型来尝试从公民提供的自由文本中提取它。我将从进行一些初步抽样和标注开始,以建立一个粗略的 MVP 概念训练数据集。然后,一旦数据进入数据库,只需一个简单的 CLI 命令就可以触发 ClearML 流水线,该流水线处理新数据的自动摄取、分析和处理,最终更新我们的版本化 ClearML 数据集,该数据集随后可供任何其他消费进程使用。
更新完成后,它可以自动使用当前或默认的超参数触发训练,或者我们也可以通过配置文件手动将其取出并修改不同的参数——这一切都通过 GitLab CI/CD 和 ClearML UI 连接起来。因此,我们修改配置文件并将其通过合并请求推送,然后整个训练流水线将一直运行到评估阶段,我们会在 GitLab 提交历史记录中收到一条消息,其中包含“嘿,这是你的最新模型链接,进去看看吧”的信息。如果我们决定采用它,我们可以发布它,在部署配置中更新 UUID 引用,然后通过审查后的合并请求将其推送,通过 GitLab 运行部署。
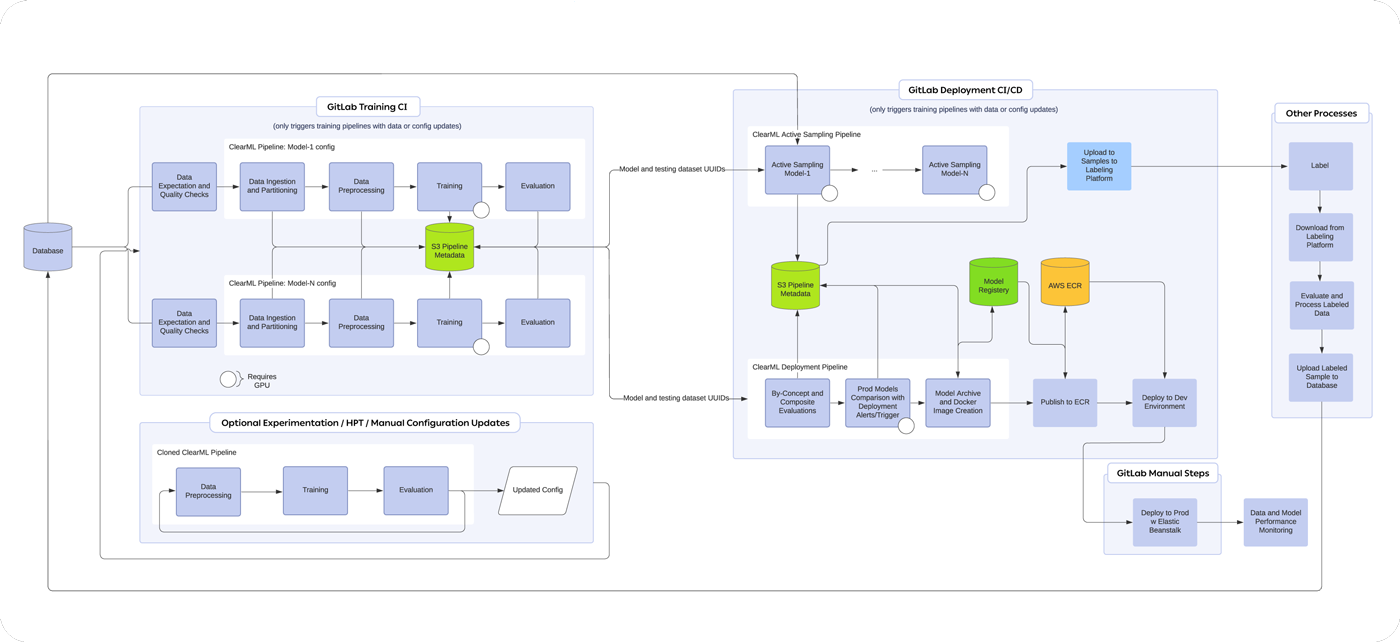
我们有一个强大的测试套件,在部署流水线中运行,以确保一切都能达到我们预期的效果,无论是从代码层面还是从推理层面。
我们大量使用的另一个 ClearML 功能是超参数优化 (Hyperparameter Optimization) 应用,它的用户界面极其简单。为此,我们只需使用一个简单的 UUID 引用,从我们的流水线中取出训练步骤,然后指定方法、参数范围、运行时间/迭代次数范围以及运行队列,即可启动。我可以直接完全地将其从流水线中取出,我喜欢这样做,并使用专门用于 HPT 的队列运行该训练步骤。这不会妨碍我们的其他任何工作,因为如果出现需要在 HPT 完成之前优先处理的事情,我总是可以在队列中手动点击并拖动任务。换句话说,ClearML 的队列系统使我能够重新调整任务优先级,并将一些手动工作放在自动工作之前,以更快地获得结果。这对于平衡运营关键工作与实验和 HPT 来说非常方便。
训练编排通过 ClearML Autoscaler 完成,因此只在需要时启动训练实例,在没有任务时则缩小规模。流程的第二部分,即部署到生产环境,大部分是自动化的,通常无需手动干预,除非触发警报。只要测试表明模型稳定且正在改进,并且我们的监控保持静默,在最终推送到生产环境之前,一切都是全自动的。
在监控方面,我们在训练阶段使用 ClearML 系统监控,推理系统的主要洞察则使用 Grafana。至于部署的触发器,它被编写用于与不同指标进行大量的条件比较。你可以将其视为一个多点决策系统,它在相同的测试数据集上评估当前生产中的模型和新模型,以确定我们是否看到了我们正在寻求的改进,同时没有损失其他领域的性能。”
时间表
“如果我们正在构建一个新的概念模型,我想说从初始数据收集、本体开发、标注,然后通过数据/训练/评估流水线推出一个 MVP 需要大约两周时间。至于更新当前在生产中的模型,大约需要一天;这只是加载或标注活跃样本,然后将其推送上去的问题,就差不多了,”她说。
总结
“使用 ClearML 为我提供了 99% 我所需的功能,易于管理,一旦设置好,我们就一切就绪了,”Heather 总结道。
如果您想开始使用 ClearML 统一的、端到端的、无摩擦的 MLOps 平台,请在 GitHub 上获取开源版本。如果您需要扩展您的 ML 流水线和数据抽象,或者需要无与伦比的性能和控制,请申请演示。
