作者:Victor Sonck,ClearML MLOps 布道师
在这篇博客文章中,我们将深入探讨 Hyper-Datasets,它本质上是 ClearML Data 的一个增强版本。
=> 喜欢观看视频?点击下方
Hyper-Datasets 与 ClearML Data(以及其他数据版本控制工具)的对比
Hyper-Datasets 是一种为非结构化数据(如文本、音频或视觉数据)设计的数据管理系统。它是 ClearML 付费服务的一部分,这意味着它比开源的 clearml-data 提供了不少升级。
两者之间的主要概念差异在于,Hyper-Datasets 将元数据与原始数据文件解耦。这使得您能够以各种方式操作元数据,同时抽象化处理大量数据的繁琐工作。
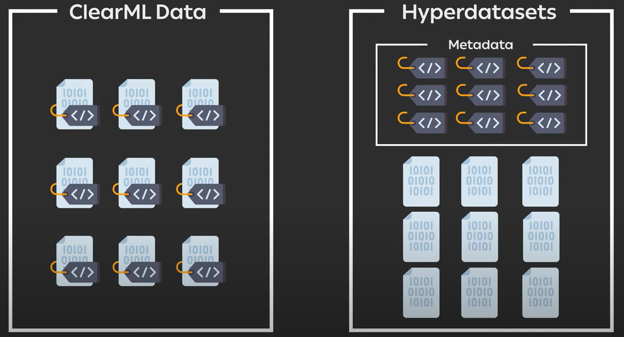
元数据的操作通过查询和参数来完成,这两者都可以使用 ClearML 实验 (ClearML Experiment) 进行跟踪。
这意味着不仅可以轻松追溯训练时使用了哪些数据,还可以克隆实验并使用不同的数据操作重新运行,而无需更改一行代码。
将此与 clearml-agent 和 autoscalers 结合起来,您就能看到其潜力。数据操作本身成为实验的一部分,我们称之为 dataview。机器学习工程师可以创建模型训练代码,然后数据工程师或质量保证 (QA) 工程师就可以无需编写任何代码来尝试不同的数据集配置。本质上,数据访问是完全抽象化的。
相比之下,在 ClearML Data 中,就像许多其他数据版本控制工具一样,数据和元数据是纠缠在一起的。以下面这个例子为例,其中图片的标签由其所在的文件夹定义,这是一种常见的数据集结构
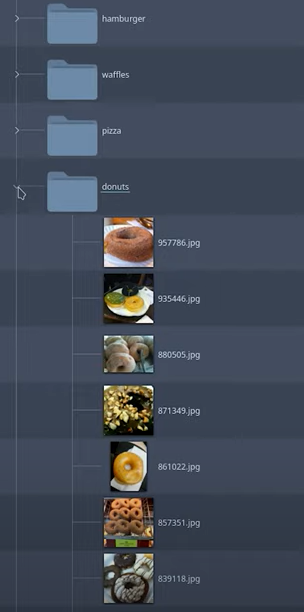
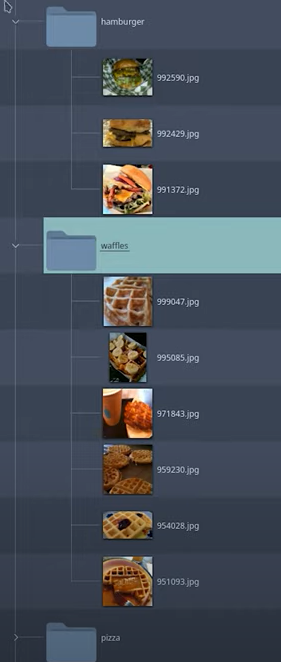 但是如果我只想用甜甜圈进行训练怎么办?或者如果我存在严重的类别不平衡怎么办?即使我可能只使用其中的一小部分,我仍然必须下载整个数据集。然后我必须修改我的代码,以便只抓取甜甜圈图片,或者通过过采样或欠采样来重新平衡我的类别。如果以后我想加入华夫饼,我又得再次修改我的代码。
但是如果我只想用甜甜圈进行训练怎么办?或者如果我存在严重的类别不平衡怎么办?即使我可能只使用其中的一小部分,我仍然必须下载整个数据集。然后我必须修改我的代码,以便只抓取甜甜圈图片,或者通过过采样或欠采样来重新平衡我的类别。如果以后我想加入华夫饼,我又得再次修改我的代码。
数据探索
让我们来看一个示例,展示如何使用 Hyper-Datasets 来调试性能不佳的模型。但首先,我们要从所有优秀数据科学项目开始的地方入手:数据探索。
当您打开 Hyper-Datasets 探索数据集时,您可以在此处找到该数据集的版本历史记录(下方截图,红色框出)。数据集可以有多个版本,每个版本又可以有多个子版本。每个子版本都将继承其父版本的内容。
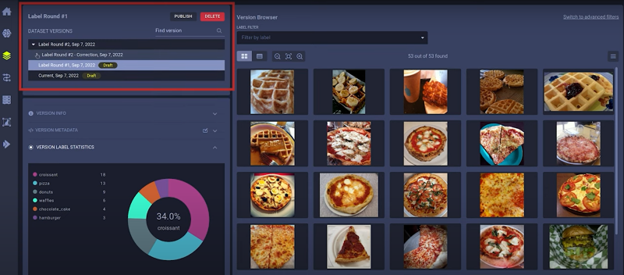
默认情况下,数据集版本处于草稿模式 (draft mode),这意味着它仍然可以被修改。您可以按下发布按钮 (publish button)(位于上方红色框出部分的右上角),本质上锁定它,以确保它不再更改。如果您想对已发布的数据集版本进行更改,请基于它创建一个新版本。
您会在上方截图的左下方找到自动生成的标签统计信息 (label statistics),它能快速概览您数据集中的标签分布情况,以及一些版本元数据和其他版本信息。
在截图的右侧,您可以实际看到数据集本身的内容。在这个例子中,我们存储的是图像,但它也可以是视频、音频、文本,甚至是存储在其他地方(如 S3 存储桶中)的文件的引用。
当您点击其中一个样本时,您可以看到图像本身以及可能对该图像进行标注的任何边界框 (bounding boxes)、关键点 (keypoints) 或掩码 (masks)。
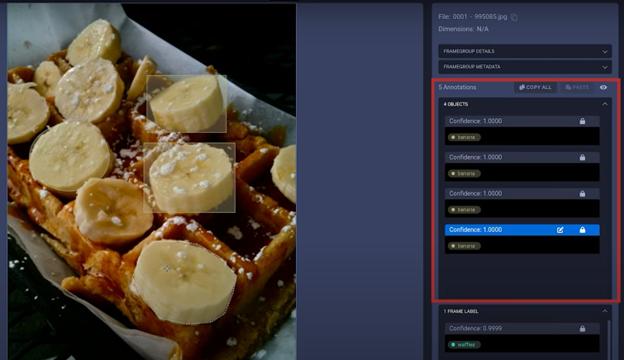
在上方截图红色框出的右侧,您可以看到图像中所有标注 (annotations) 的列表,包括图像本身的分类标签 (classification labels)。
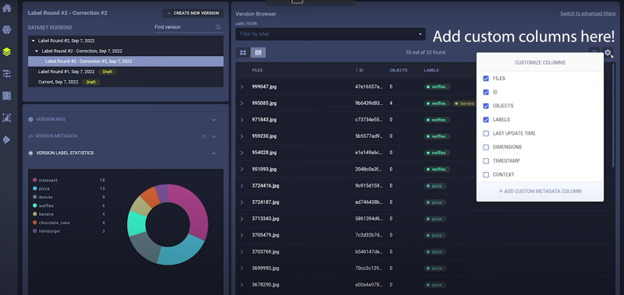
回到主屏幕后,您还可以将样本视图切换为表格形式 (table),而不是预览网格 (preview grid),这对于音频或文本等数据类型非常方便。
查询与 Dataviews
在表格上方,您可以通过切换到高级过滤器 (advanced filters) 来尝试查询功能 (querying functionality)。例如,您可以创建一个查询,只包含确定性至少为 75% 的甜甜圈。您基本上可以查询任何元数据或标注,所以尽管去尝试吧!
这些查询的目标不仅是作为数据探索的便捷过滤器,我们还希望将这些查询作为机器学习实验的一部分!
本文前面介绍的 dataviews 就登场了。Dataviews 可以使用复杂的查询,将来自一个或多个数据集的特定数据连接到实验管理器 (Experiment Manager) 中的实验。本质上,它创建和管理远程数据集的本地视图 (local views)。
举个例子,假设您创建了一个实验,尝试使用 Hyper-Datasets 基于特定数据集子集训练模型。要获取用于训练的数据,您可以轻松地从代码创建 dataview,如下所示。然后您可以添加各种约束条件 (constraints),如类别过滤器 (class filters)、元数据过滤器 (metadata filters) 和类别权重 (class weights),这些将根据需要对数据进行过采样 (over-sample) 或欠采样 (under-sample)。
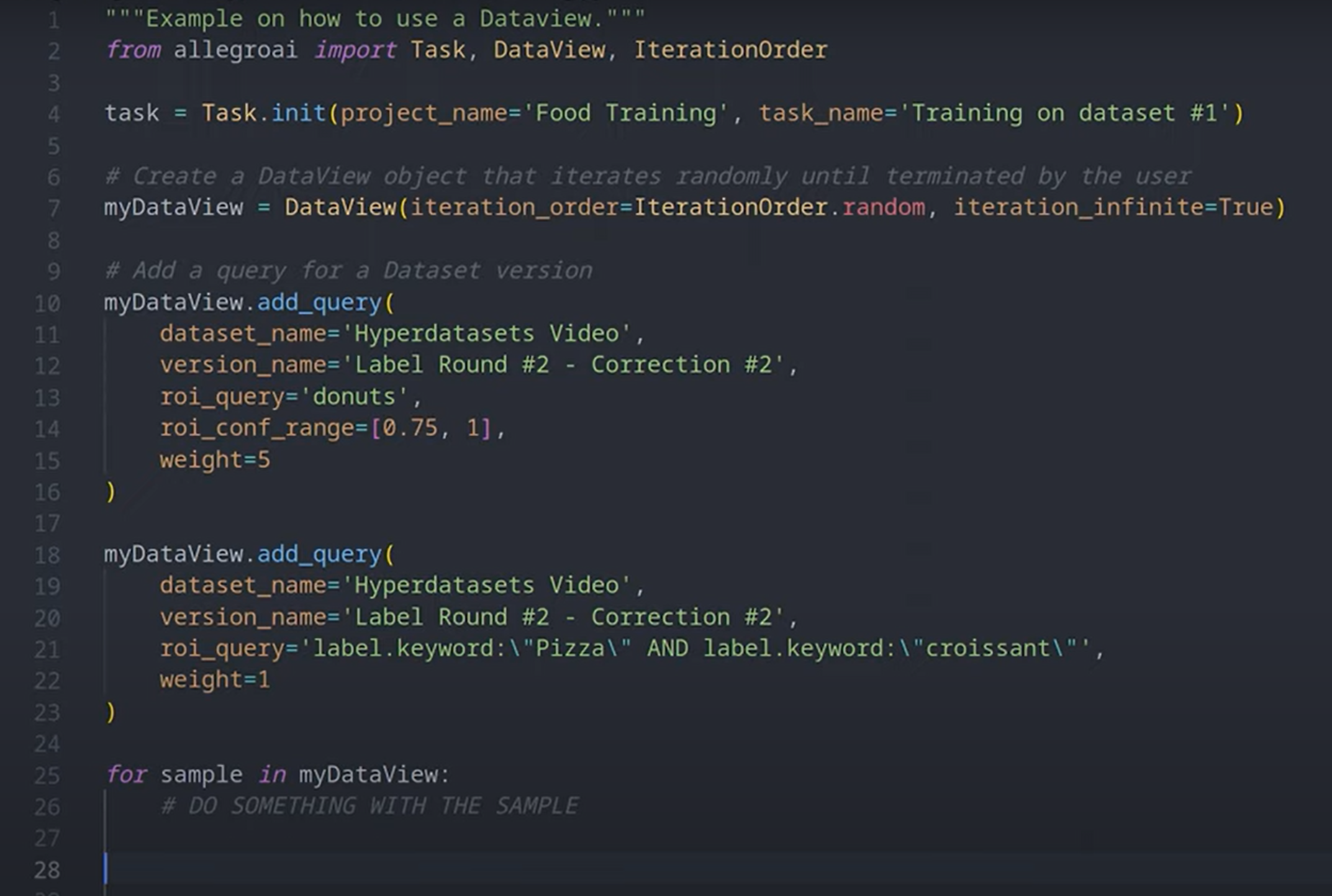
运行任务后,我们可以在实验管理器 (Experiment Manager) 中看到它。模型正在报告标量 (scalars) 并按预期进行训练。使用 Hyper-Datasets 时,还有一个 dataviews 标签页 (tab),其中包含您可使用的所有功能。您可以看到使用了哪些输入数据集和版本,并可以看到用于对它们进行子集划分的查询系统 (querying system)。
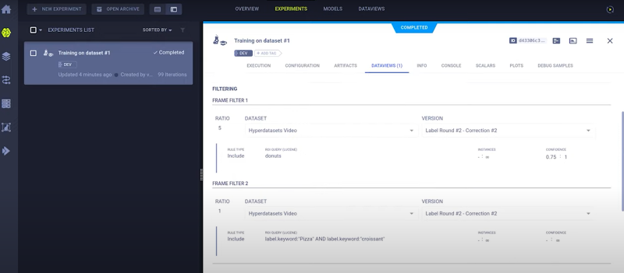
这已经为您提供了一种简洁明了的方式,可以在非常特定的数据集子集上训练您的模型,但还有更多功能!
如果您想重新映射标签 (remap labels),或者即时将其枚举为整数 (enumerate them to integers on the fly),ClearML 将跟踪所有已完成的转换 (transformations),并确保它们可复现 (reproducible)。当然,还有更多功能 – 如果您感兴趣,请查看我们关于 Hyper-Datasets 的文档。
克隆 Dataview
ClearML 的资深用户已经知道接下来会发生什么:克隆。想象一下这样的场景:机器学习工程师已经创建了我们之前看到的模型训练代码:一个集成的 dataview 作为数据源。
现在,质量保证 (QA) 工程师或数据分析师发现数据分布不太平衡,这影响了模型的性能。
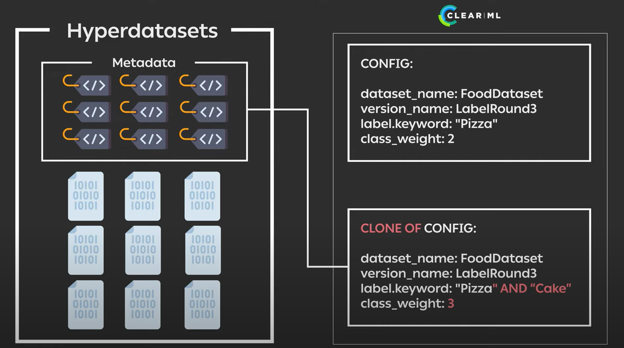
在不改变任何底层代码的情况下,任何人都可以克隆现有的实验。这使得他们能够更改 dataview 本身中的任何查询或参数。在这个例子中,我们将类别权重 (class weight) 更改为其他值,从而修改数据分布。
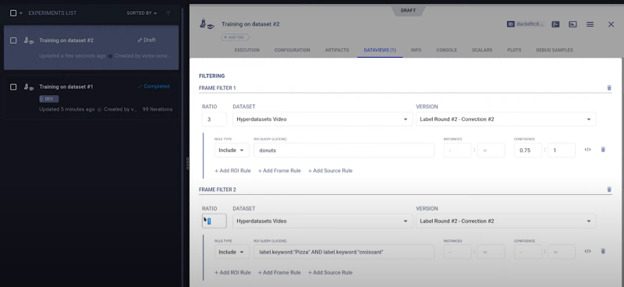
然后您可以将此实验加入队列 (enqueue),以便远程ClearML agent (ClearML 代理)开始处理。只需点击几下,同一个模型就会在远程机器上基于不同的数据分布进行重新训练,无需更改代码。
远程机器在新的 dataview 上执行实验后,我们可以轻松比较这两个实验,以进一步帮助我们进行分析。
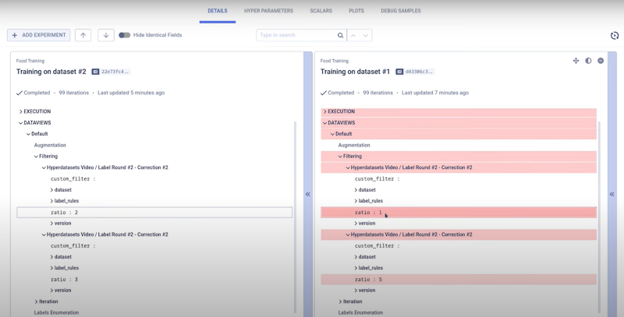
这是一种非常快速高效的迭代方法,可以省去大量不必要的工作。
结论
如果您一直在关注我们在YouTube 频道上的入门视频,您应该已经开始看到这种方法的潜力。例如,我们现在可以在数据本身上运行超参数优化 (hyperparameter optimization),因为之前显示的所有过滤器和设置都只是任务的参数。整个过程可以例如在云自动扩缩器 (cloud autoscaler) 上并行运行。想象一下,找到每个类别的最佳训练数据置信度阈值 (confidence threshold),仅仅是为了优化模型性能。
如果您有兴趣为您的团队使用 Hyper-Datasets,请 联系我们,我们将立即为您提供帮助。同时,您可以在app.clear.ml上享受开源组件的强大功能,如果需要任何帮助,请不要忘记加入我们的Slack 频道。
