并免费获得一个功能齐全的 MLOps 堆栈

部署模型变得越来越容易,这尤其要归功于诸如 Transformers-Deploy 这样的优秀教程。它讲述了如何转换和优化 Huggingface 模型,并将其部署到 Nvidia Triton 推理引擎上。Nvidia Triton 是一款非常快速且稳定的工具,在寻找模型部署方法时应将其列在非常靠前的位置。我们的开发人员当然知道这一点,因此如果模型需要 GPU 加速,ClearML Serving 会在后端使用 Nvidia Triton。如果你还没读过那篇博文,请先去读一下,我们在本文中会多次引用它。
注意:对已提供服务的模型进行基准测试既非常有趣也非常困难。这很大程度上取决于如何设置以及你在微调每个选项的性能上花费了多少时间,因此从一开始,这篇博文(以及任何其他基准测试博文)中的数据都应持保留态度。理想情况下,你可以将该方法作为自己的起点。
使用 ClearML Serving 设置此示例的代码可在此处找到。试用一下,并告诉我们你的想法!
“原生” Triton 缺少什么以及 ClearML Serving 增加什么
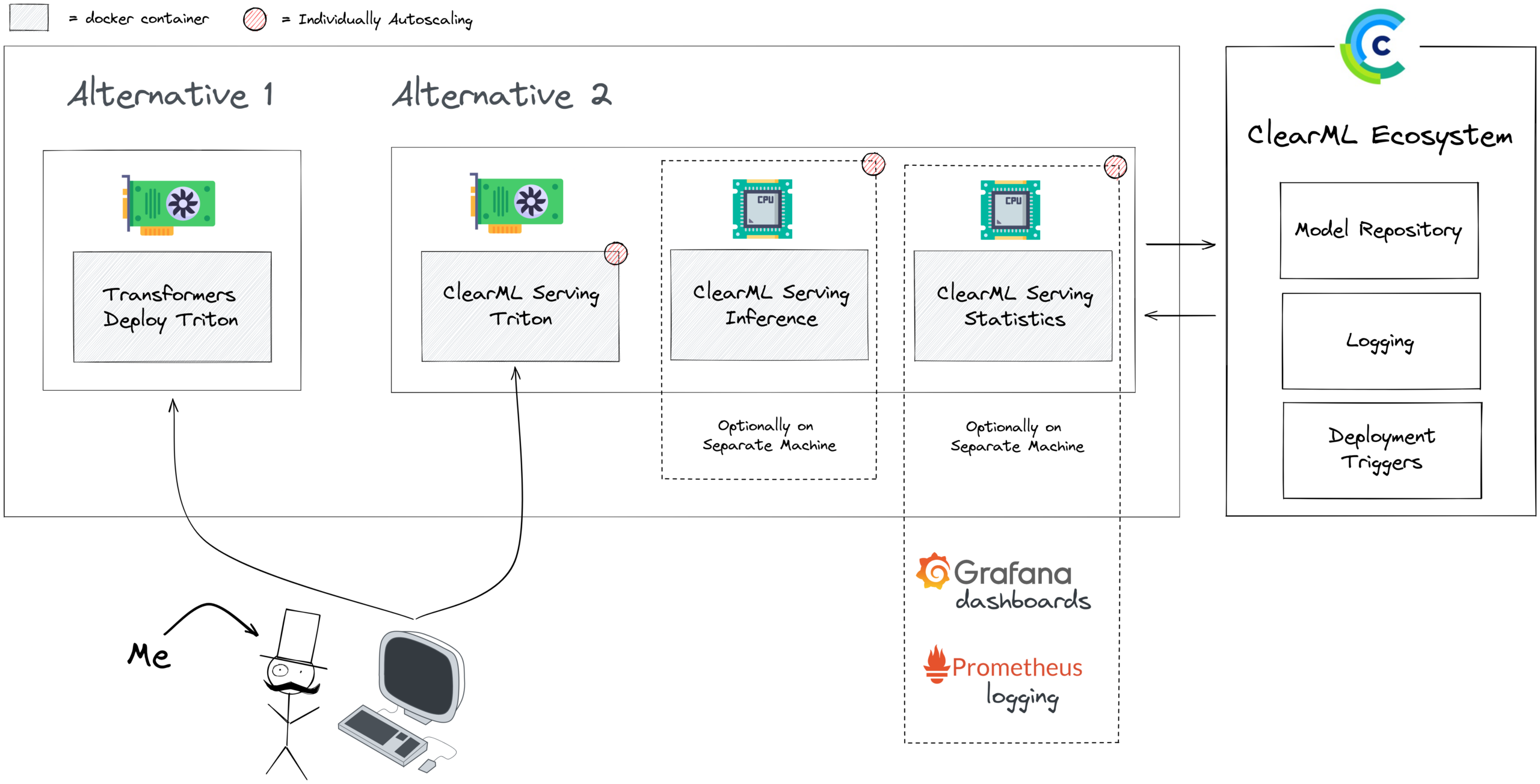
除了性能之外,Triton 缺乏一些 ClearML Serving 正试图解决的“生活质量”功能。ClearML 是一个开源且免费的 MLOps 工具箱,而 ClearML Serving 是其中的最新工具 🔨。
Triton 完全独立,并且开箱即用时未集成到任何工作流程中,这意味着你必须花费大量时间来确保它与你现有的技术栈良好配合。这很好,因为它让 Triton 可以专注于其所长并做到极致,但在实际生产环境中你仍然需要不少额外功能。
模型库
首先,它应该连接到你的模型库,这样你就可以轻松部署新版本的模型,并在需要时自动化此过程。同时,如果能对新模型进行金丝雀部署(Canary Deployment),将流量从旧模型逐步转移到新模型,那就更好了。当然,所有这些都可以实现,但这需要宝贵的工程时间和对 Triton 工作原理的深入了解。
自定义统计数据
自定义统计数据是另一个领域,Triton 开箱即用的体验相当有限。理想情况下,人们可以轻松定义自定义用户指标,不仅包括延迟和吞吐量,还可以分析进出数据的分布,以便稍后检测漂移。这在 Triton 中是可能的,但你必须在 C 语言中定义它们,而唯一的文件就是(我引用一下)
Further documentation can be found in the TRITONSERVER_MetricFamily* and TRITONSERVER_Metric* API annotations in tritonserver.h
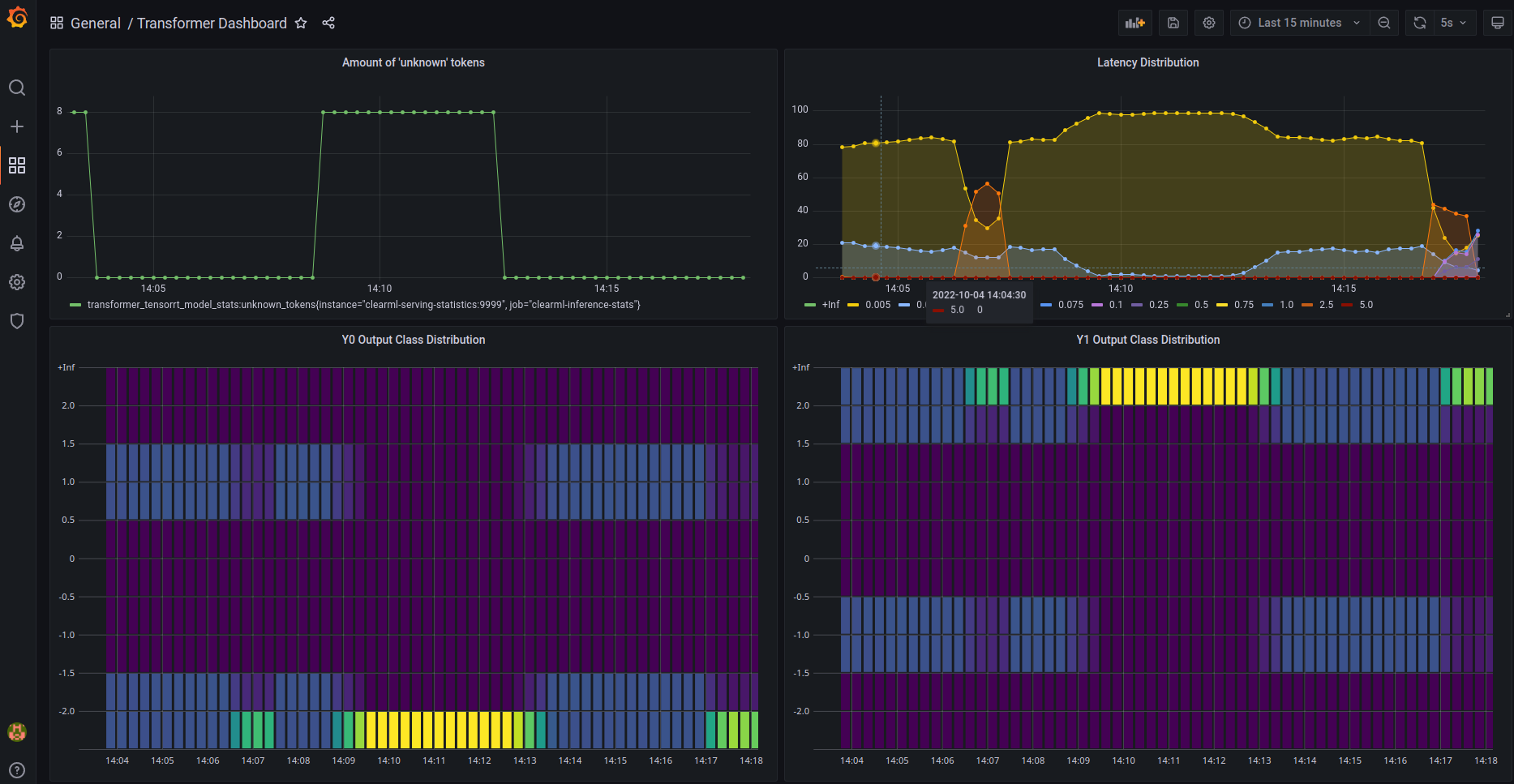
利用这些自定义统计数据,你可以设置一个监控面板,摄取自己的自定义指标。然后,你可以为这些指标添加自动化警报,确保在情况开始恶化时你不会错过。我们将在后续博文中更深入地探讨自定义指标。
端到端可追溯性
最后,Triton 开箱即用时未集成的结果是可追溯性有限。你想确保当监控系统发现问题或错误时,可以轻松地从已部署的模型,“点击穿透”查看用于训练该模型的管线,再到该管线中的每个步骤,甚至追溯到训练模型使用了哪个数据集版本 ID。
需要明确的是(双关语),添加所有这些功能并非 Triton 的责任。他们构建了一个出色的、高度专注的、高性能的模型服务引擎。你可以自行决定要添加多少额外的花哨功能。ClearML Serving 增加了无缝模型更新、与完全开源的 ClearML 平台集成、自定义指标和监控,同时不损失性能。我们投入了工程时间来完成这些,这样你就无需再费心了!
基准测试设置
延迟 vs 吞吐量
延迟是指从你向 API 发送负载到接收到结果之间经过的时间。这通常是人们非常关注的指标,也是最“炫”的指标。数字越低越好。

但现实世界并非总是如此。仅将单次请求延迟作为指标存在一些问题
- 延迟受服务器当前负载的严重影响。 你在隔离环境下可能获得低于 1 毫秒的延迟,但当服务器同时处理数百个其他请求时,延迟会迅速增长到 100 毫秒以上。
- 延迟无法说明关于扩展性和硬件利用率的任何信息。 你想知道你的 CPU 和 GPU 有多少被用于处理负载,这样如果硬件仍然可用,你可以扩展以使用更多硬件。
- 使用实际提高吞吐量的方法时,延迟可能会变差。 动态批处理等很酷的功能可以提高整个过程的效率,但会牺牲单个请求的延迟。动态批处理将单独的传入请求汇集到临时批次中,从而更充分地利用 GPU 的潜力。代价是每个批次的第一个请求必须稍微等待其他请求的到来,从而增加了延迟。
另一方面,吞吐量计算的是服务器每秒可以处理的总请求量 (RPS)。在这篇博文中,我们将更关注这个数字,因为对于大多数大规模部署的机器学习模型来说,这是一个关键的关注点。与单次请求延迟相比,它更能代表实际情况。需要明确的是:延迟仍然是一个非常重要的测试指标,只是不应该孤立地看待它。我们将同时报告这两个指标。
选择的云服务器
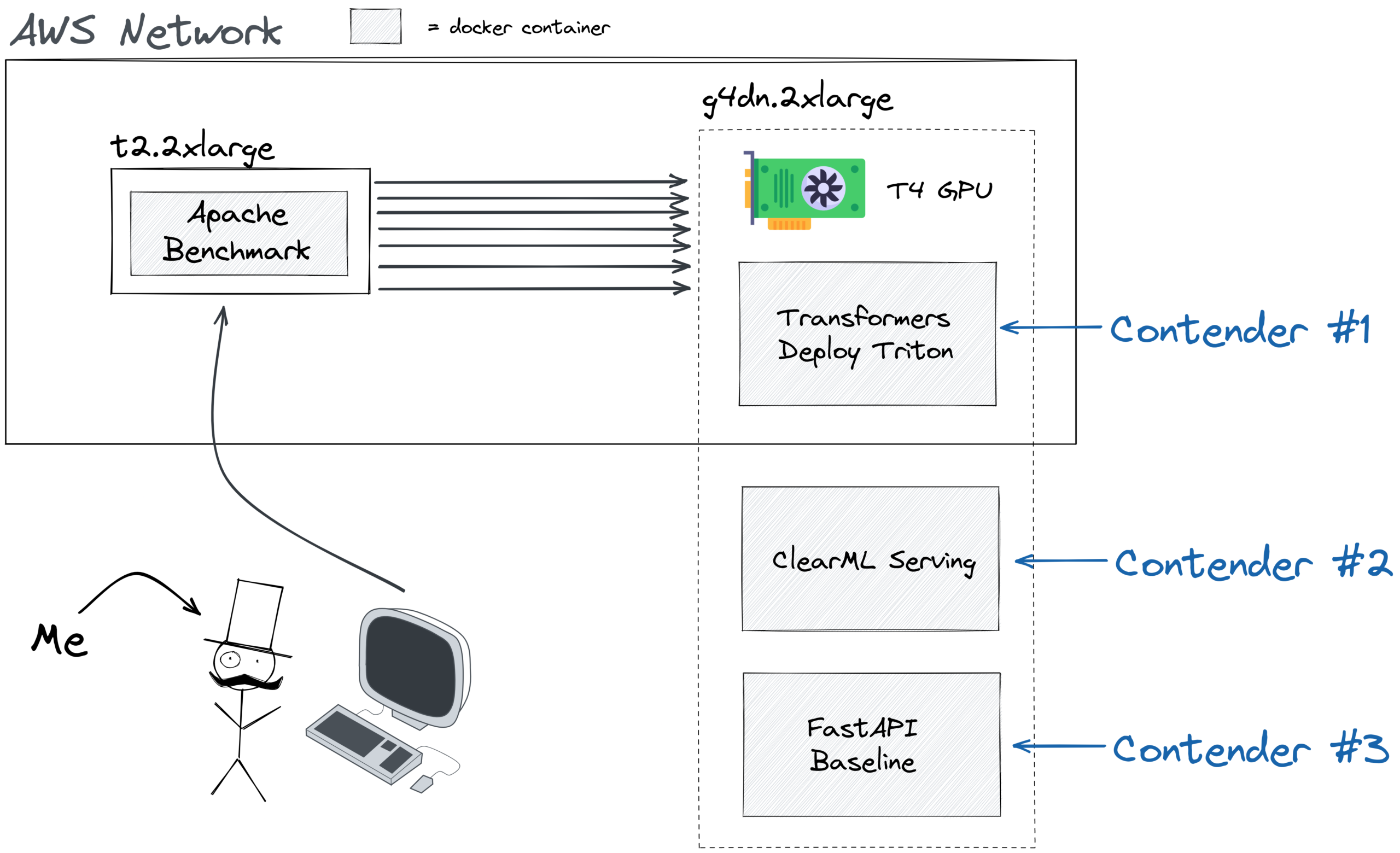
为了运行我们的设置,我们选择了 AWS g4dn.2xlarge 机器,它包含 8 个 vCPU、32 GB 内存,最重要的是,1 个 NVIDIA T4 GPU。这个 GPU 相当酷,它只消耗 70W,这使得它作为云 GPU 使用相对便宜。另一方面,它针对深度学习推理进行了优化。它不像 A100 那样拥有巨大的显存,但它旨在以每美元的推理性能进行竞争,并且表现出色。
另一方面,我们使用了一台独立的 t2.2xlarge 机器来运行基准测试。生成请求不需要太多 CPU 功率,但运行深度学习推理服务器以及大量工作进程来处理 HTTP 开销则需要。因此,为了避免实际测试干扰结果,我们将其隔离了。当然,现在我们只是用潜在的网络干扰替换了潜在的 CPU 干扰,这是真的!但 AWS 内部网络非常快速且稳定,所以在波动性方面一点也不差。由于增加了网络延迟,数字本身可能会略低一些,但竞争者之间的相对性能应该保持不变,至少它将反映一个更真实的用例。
选择的本地机器
由于我已经在进行基准测试,我想到也在我的个人游戏电脑上运行同样的测试套件。这台特定机器最有趣的地方在于,与 GPU 相比,它有一个质量相当高的 CPU,这在大多数云机器中是找不到的。正如你稍后将看到的,这个细节对 ClearML Serving 堆栈的性能产生了令人印象深刻的影响。这台机器的具体配置如下:
| CPU | AMD Ryzen 9 3900X 12核处理器 |
|---|---|
| GPU | NVIDIA GeForce RTX 2070 SUPER |
| 内存 | 双通道 32GB 2133 DDR4 |
| 操作系统 | Manjaro Linux |
使用 ONNX 而非 TensorRT
传统观点认为 TensorRT 会比 ONNX 更快,即使后者经过优化。然而,这假定一切都能“顺利工作”。首先,在原始博文中,作者展示了优化后的 ONNX 二进制文件实际上比 TensorRT 稍微快一点!
这也就是为什么他们实现的创纪录的低于 1 毫秒的推理延迟实际上是来自部署在 Triton 上的 ONNX 模型。
我们确实让 TensorRT 模型在 Triton 上工作了,但它与动态批处理配合得不好。我们正在研究这个问题,并希望将来能为你提供一些 TensorRT 的额外基准测试。话虽如此,这篇博文主要关注 ClearML Serving 和 Triton 之间的差异,这个差异应该也能延续到 TensorRT Triton,因为两者最终都使用相同的后端。
关于 Python Locust 的说明,以及为什么我们使用 Apache Benchmark 进行测试
Locust 是一个流行的 Python 负载测试框架。但它是用 Python 编写的,所以速度慢是无可避免的。不过它易于使用,并且能生成漂亮的图表。尽管如此,为了确保向你展示你能期望的最大吞吐量,我们最终使用了 Apache benchmark 工具。它是用 C 语言编写的,与 Locust 相比(即使使用 FastHTTPClient 分布式部署,Locust 给出的指标也非常不稳定),它产生了非常快速和稳定的结果。
竞争者:部署时有哪些选择?
FastAPI
让模型运行起来最简单的方法就是“将其封装在一个 Flask API 中”。如今,这个概念有点像个笑话了,因为实在没有什么好的理由现在还要这样做。不是从性能角度来看,甚至也不是从易用性角度来看!你将无法获得无缝的模型更新、速度慢、没有集成,所有你想要的东西都得自己写。也许对于一个不需要所有这些功能、只想要一个包含 50 行 Python 代码的 API 的业余项目来说,这还行。但即使那样也很勉强。
话虽如此,我们可以将其作为基准。这是我们这个小型、临时的模型 API 服务器的代码
如果有任何 FastAPI 爱好者读到这里,我们喜欢 FastAPI!它只是不是为处理深度学习模型服务而设计的。除此之外,得益于出色的 Huggingface 库,它非常易于设置,并且只需要极少的代码行数。但尽管如此,请不要在家里这样做。
Triton Ensemble
按照原始 transformers deploy 博文附带的 GitHub 仓库中的说明,我们基本上只需要执行 2 个 docker 命令。
Triton 无疑是当今市场上最快的模型服务引擎。而且我们只用一个命令就让它跑起来了!但现在呢?我们需要监控新部署的模型。将来需要更新它,而且不能停机。也许甚至还想做 A/B 测试!Triton 提供纯粹的性能,简单明了,但它缺少一些 ClearML 试图解决的基本“生活质量”功能。
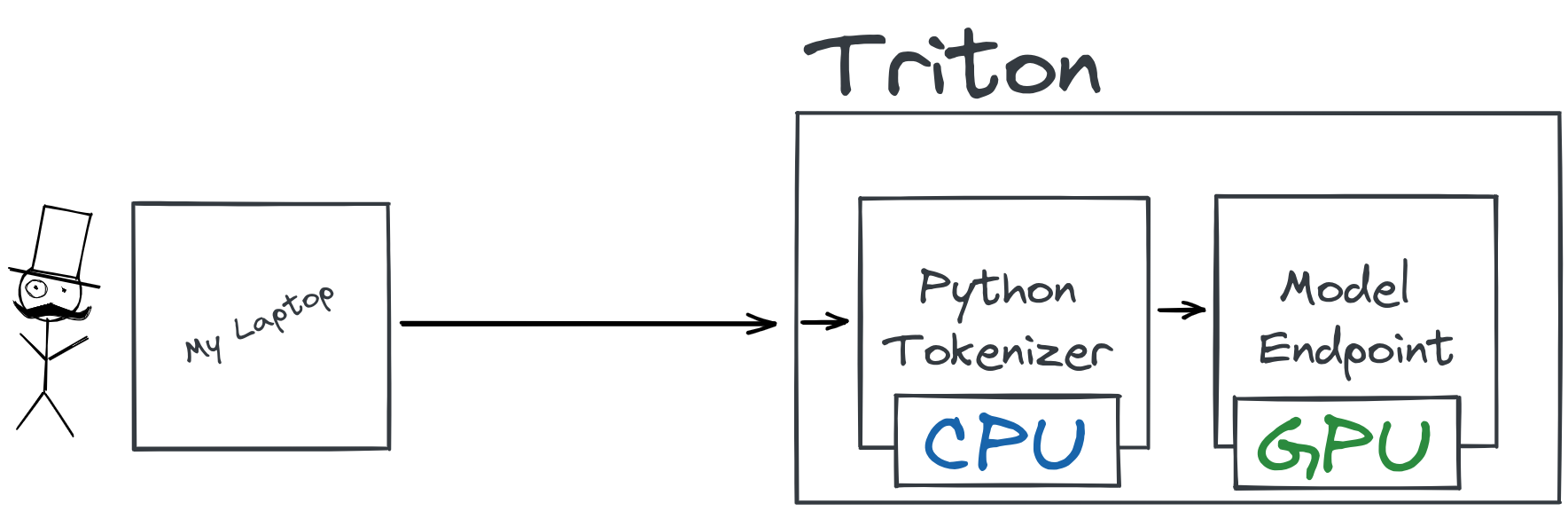
按照这些步骤,实际上还将设置 3 个不同的端点。1 个用于模型本身,1 个用于 tokenizer,然后是第 3 个端点,它将这两个端点按顺序在 ensemble 中运行。你稍后会详细了解这一点。
ClearML Serving
ClearML Serving 作为你和 Nvidia Triton(或者如果你想使用 CPU 进行推理,则是 Intel OneAPI)之间的中间层。这使我们能够提取进出数据的自定义日志。自然,这会增加一定的开销,但如果你想要更多功能,总会引入更多开销,你想走多远取决于你自己!
话虽如此:我们稍后会看到,从一定规模开始,这种开销就不再明显,而扩展带来的好处将开始占据主导地位。这使得最终的总吞吐量要高得多。
对于那些在想:“等等,把 FastAPI 放在中间,你们不就是‘把它封装在一个 flask API 中’吗?”的人来说,我们并没有在 Python 代码中运行我们的模型,也没有期望 FastAPI 来处理动态批处理之类的事情。正如我们之前所说,FastAPI 非常棒,你只需在这里取两者的精华即可。将 Triton 的 C 级性能、动态批处理和 GPU 分配与轻量级、易于使用且高度可伸缩的 FastAPI 结合起来。一个 Flask API 原则上不是一个坏主意,它很大程度上取决于你用它做什么。在这种情况下,它是用来路由流量、自动扩展以及允许自定义用户 Python 代码执行,这正是它设计用来做的事情。
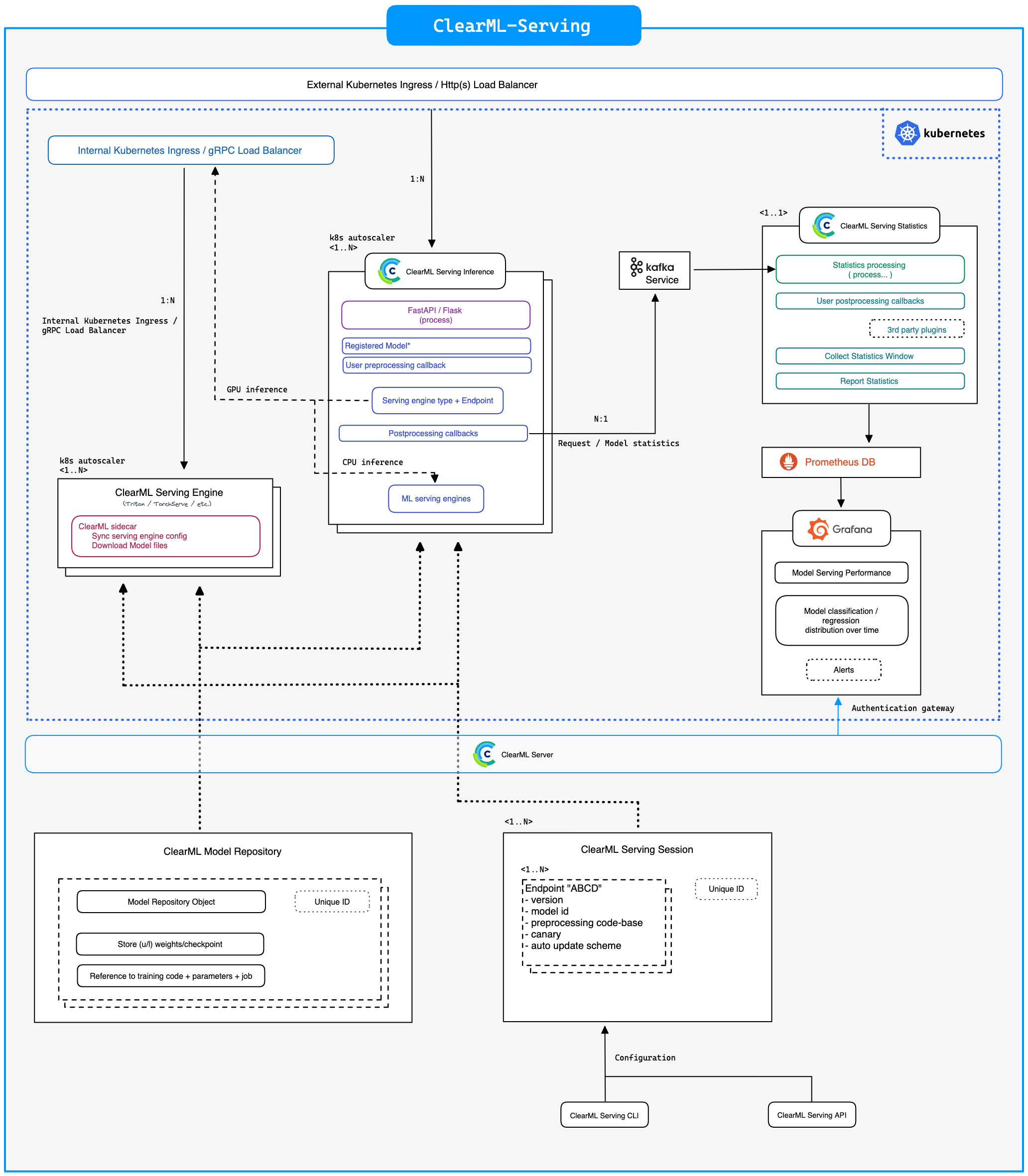
ClearML serving 当然是围绕开源的 ClearML 生态系统设计的。例如,你可以受益于系统中所有日志都集中在ClearML webUI 中。这也意味着部署系统中已经存在的任何模型都非常容易。这样做的好处是,你在使用实验管理器时,就能有机地构建你的模型库。话虽如此,如果你不想这样做,也没有关系。我们也可以简单地上传一个我们已经制作好的模型,就像这里的情况一样。
现在我们有了模型,剩下的就是部署它了,只需一个命令就可以完成!你可以在 Triton 模型附带的 config.pbtxt 文件中找到所有输入和输出信息。
设置竞争者
模型详情
我们使用“philschmid/MiniLM-L6-H384-uncased-sst2”作为我们的测试模型,这与原始 Transformer-Deploy 博文使用的模型完全相同。我们测试输入的序列长度是 16 个 token,而模型的最大长度是 128。这意味着它能产生你能期望的最快数字,因此你在自己尝试时请记住这一点。
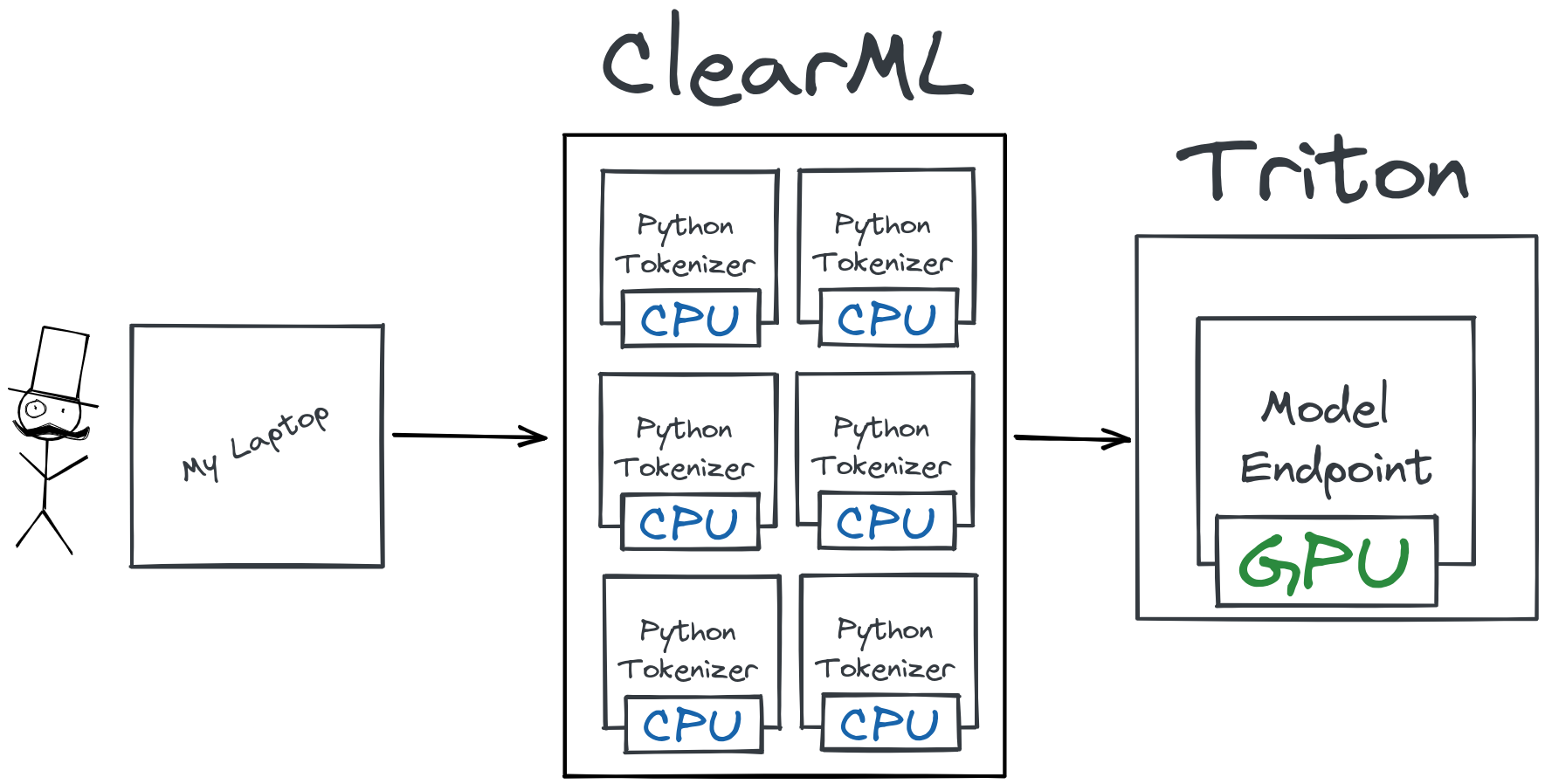
自动扩展 Tokenizer
你也可以在上面的代码片段中看到,我们添加了一个自定义的 preprocessing.py 文件作为 ClearML Serving 端点的前处理。这个文件的工作与原始博文中的自定义 Python 端点非常相似:它对请求进行 tokenization。主要区别在于这里的 tokenization 是在中间完成的,在到达 Triton 之前,这使得它能够独立于 Triton 引擎进行自动扩展!添加自定义前处理步骤非常容易,例如,这是我们用于基准测试的文件:
在 Triton 中,这个过程是通过创建一个自定义的 Python“模型”来完成的,然后该模型运行 tokenizer。这种方法的主要缺点是缺乏自动扩展,Triton 设计时并没有很好地处理这种设置。它虽然有效且快速,但将 CPU 密集型的前处理从 Triton 中剥离并独立扩展会更有意义。这正是 FastAPI 和 Gunicorn 等服务器的优势所在:处理大量较小的请求并相应地进行扩展。
动态批处理
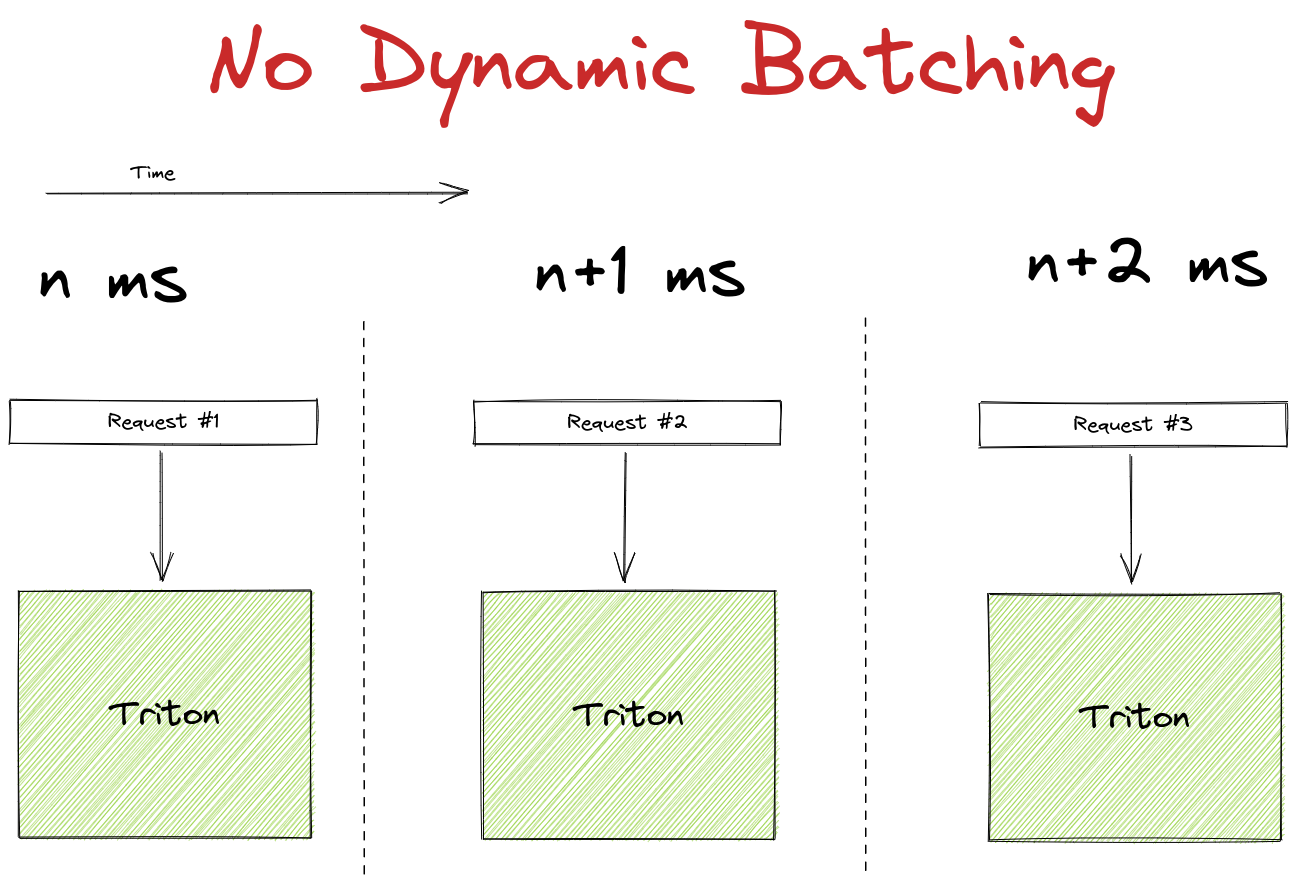
Triton 支持动态批处理,这是一种非常酷且直观的方式,可以在可能牺牲单个请求延迟的情况下提高吞吐量。
它的工作原理是 holding 第一个传入请求一定时间(可配置)。在等待期间,它会监听其他传入请求,如果这些请求在等待阈值内到达,它们就会被添加到第一个请求中以形成一个批次。如果批次在时间限制内达到最大大小,它会更早被处理。通常在 GPU 上处理一个批次效率要高得多,因此以这种方式优化硬件利用率是有意义的。
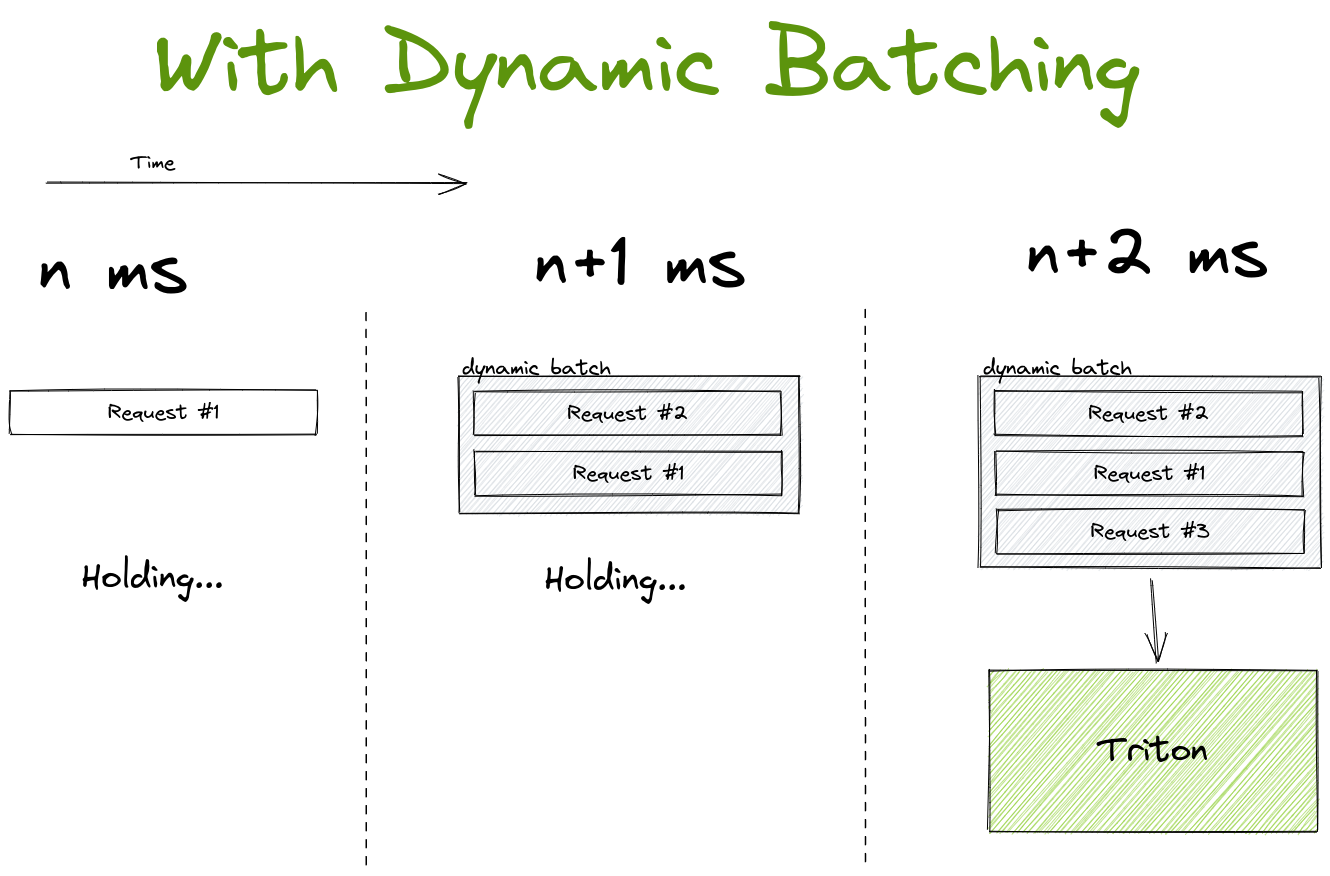
不过请注意,动态批处理主要针对高负载系统,原因显而易见。如果你的系统只定期接收请求,则很大一部分请求最终会等待从未出现的额外流量。它们将单独通过 GPU 处理,最终产生的延迟远高于系统实际能力,而没有任何实际好处。
结果!
现在,我们可以使用 Apache Benchmark 在较小的 AWS VM 终端中运行以下命令
我们最终使用了 -c 128,因为在这种负载下它基本上会使 GPU 饱和,并且超过这个点后我们没有看到更明显的性能提升。
首先,我们想知道我们的竞争者在不启用 Triton 动态批处理时的表现如何。正如预期的那样,封装 Huggingface 接口的 FastAPI 表现落后,尽管它与其他竞争者相比表现得令人惊讶地好。不过,正如你将看到的,这仅适用于批量大小为 1 的情况,但对于一个代码量只有 21 行的服务器来说,这仍然相当令人印象深刻。
接下来,我们看到 ClearML 位居第二,其结果取决于使用的工作进程数量,但在速度方面从未完全达到 Triton 的水平。这有道理,因为最终我们在 Triton 本身之上添加了额外功能,这会引入额外的延迟。虽然不多,因为我们投入了大量精力进行优化,但在这种情况下,我们无法完全匹配 Triton 的性能也是合理的。

| 平均延迟 | 每进程延迟 | RPS | Triton 动态批处理 | 变体 | |
|---|---|---|---|---|---|
| ClearML 8 个工作进程 + 动态批处理 | 35.794 | 0.28 | 3575.97 | 是 | ClearML gunicorn |
| ONNX Triton ensemble + 动态批处理 | 51.015 | 0.399 | 2509.09 | 是 | Triton Ensemble |
| ClearML 2 个工作进程 + 动态批处理 | 72.425 | 0.566 | 1767.34 | 是 | ClearML gunicorn |
| ONNX Triton ensemble | 112.551 | 0.879 | 1137.26 | 否 | Triton Ensemble |
| ClearML 2 个工作进程 | 113.958 | 0.89 | 1123.22 | 否 | ClearML gunicorn |
| ClearML 8 个工作进程 | 114.224 | 0.892 | 1120.61 | 否 | ClearML gunicorn |
| ClearML 1 个工作进程 + 动态批处理 | 136.58 | 1.067 | 937.18 | 是 | ClearML gunicorn |
| ClearML 1 个工作进程 | 138.541 | 1.082 | 923.91 | 否 | ClearML gunicorn |
| FastAPI 基准 | 158.177 | 1.236 | 809.22 | 否 | 纯 FastAPI |
然而,在 Triton 引擎上启用动态批处理后,情况发生了相当大的变化。请记住,我们在底层的 Triton 实例和 Transformers-Deploy 的实例上都启用了动态批处理。
我们看到,当使用 1 个 ClearML 工作进程时,性能基本上与不使用动态批处理时相同。这同样合理,因为在这种情况下,1 个工作进程很快就成了瓶颈。但当增加工作进程数量时,情况开始迅速变化。当使用 8 个 ClearML 工作进程时,总吞吐量甚至显著高于 Triton Ensemble!
在我自己的机器上,这种效果更加明显。似乎 CPU 更高的质量、速度和核心数对 ClearML Serving 的性能产生了显著影响。这并不奇怪,因为 ClearML 工作进程高度依赖基于 CPU 的扩展来正确地向 GPU 喂数据。将启用动态批处理的 8 个工作进程的 ClearML 结果与启用动态批处理的 Triton ensemble 进行比较,你会得到标题中提到的性能提升。如果将其与开箱即用、未启用动态批处理的 Triton 进行比较,那将是惊人的 608% 的增长。
| 平均延迟 | 每进程延迟 | RPS | Triton 动态批处理 | 变体 | |
|---|---|---|---|---|---|
| ClearML 8 个工作进程 + 动态批处理 | 9.647 | 0.075 | 13269 | 是 | ClearML gunicorn |
| ONNX Triton ensemble + 动态批处理 | 28.341 | 0.221 | 4516 | 是 | Triton Ensemble |
| ClearML 2 个工作进程 + 动态批处理 | 29.12 | 0.227 | 4396 | 是 | ClearML gunicorn |
| ClearML 1 个工作进程 + 动态批处理 | 58.126 | 0.454 | 2202 | 是 | ClearML gunicorn |
| ONNX Triton ensemble | 68.364 | 0.534 | 1872 | 否 | Triton Ensemble |
| ClearML 2 个工作进程 | 69.513 | 0.543 | 1841 | 否 | ClearML gunicorn |
| ClearML 8 个工作进程 | 69.477 | 0.543 | 1842 | 否 | ClearML gunicorn |
| ClearML 1 个工作进程 | 72.014 | 0.563 | 1777 | 否 | ClearML gunicorn |
| FastAPI 基准 | 99.089 | 0.774 | 1292 | 否 | 纯 FastAPI |
等等,但我们之前说过,我们甚至无法指望匹配 Triton 的性能,更不用说超过它这么多。嗯,那在启用动态批处理之前是事实。但在启用它之后,运行 tokenization 的那个 Python“模型”的单个实例开始成为瓶颈。
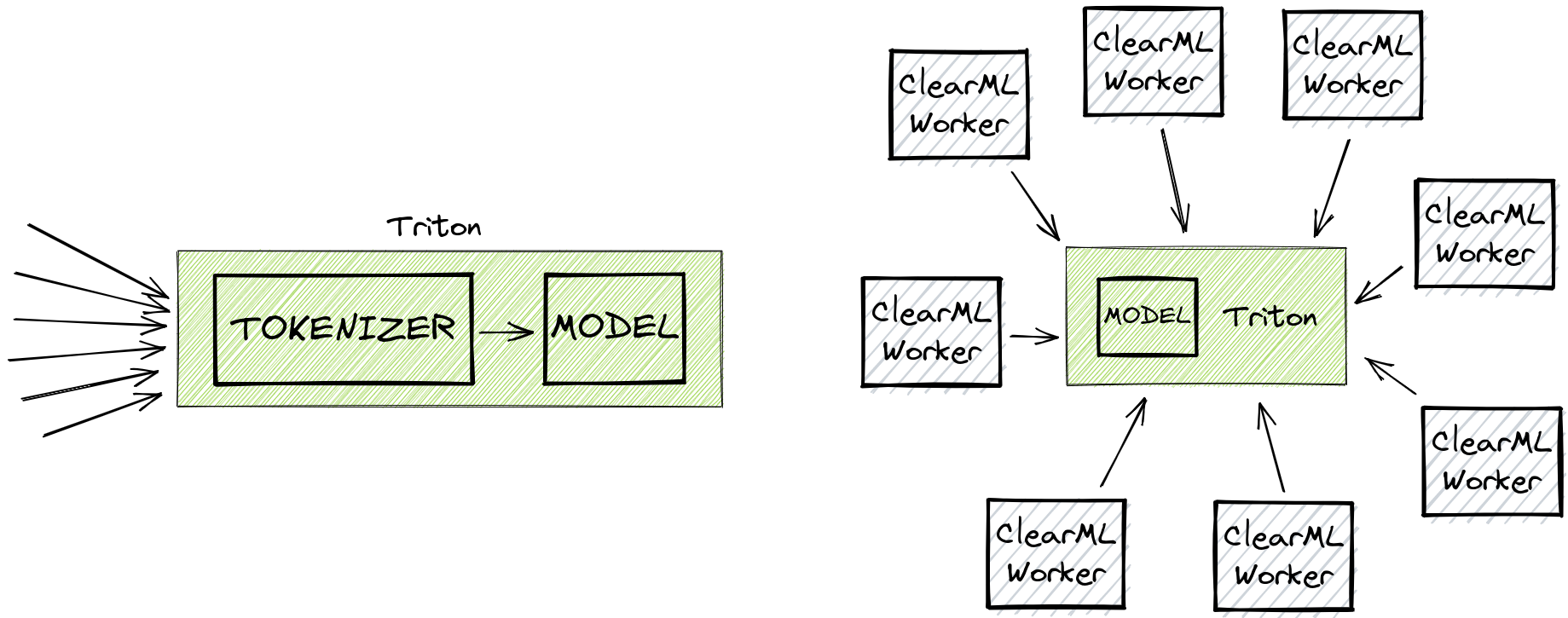
本质上,这意味着在一定规模下,ClearML Serving 开始超出其自身的开销,实质上是免费为你提供了所有额外功能!
结论
要进行大规模部署,需要考虑的事情远不止单次请求延迟。Transformer-Deploy 博文和仓库的作者在提供一个用于优化 Huggingface 模型以用于生产的框架方面做得非常出色。在这篇博文中,我们更进一步,展示了在更实际的生产场景中,你可以从这些模型中获得多少性能。
我们已经证明,你并不一定需要牺牲性能来获得无缝模型更新、监控和端到端工作流程集成等“生活质量”功能。前提是你的模型是大规模部署的。
同样,你可以在此处找到重现此示例的代码
如果你有兴趣自己试用一下,请前往我们的 ClearML serving github 仓库试试看!如果你需要任何帮助,欢迎加入我们的 Slack 频道,我们的社区将很乐意帮助你!
