丰富食物数据集的案例研究
引言
Toloka 和 ClearML 在几个月前共同启动了这个合作项目。我们的目标是向其他 ML 从业者展示如何在数据输入到 ML 模型之前,先收集数据,然后进行数据版本控制和管理。
我们相信遵循这些最佳实践将帮助他人构建更好、更强大的 AI 解决方案。如果您感兴趣,可以看看我们共同创建的项目。
我们能否丰富现有数据集,并让算法学习识别新的特征?
我们在 Kaggle 上找到了以下 数据集 ,并很快决定它非常适合我们的项目。该数据集包含数千张使用 MyFoodRepo 收集的不同类型的图像,并在知识共享 CC-BY-4.0 许可下发布。您可以在官方的 食物识别基准论文 中查看有关此数据的更多详细信息。


此外,我们注意到有些食物比其他食物更…开胃。

那么,我们能否用这些额外信息来丰富这个数据集,然后创建一个能够识别这些新特征的算法呢?
答案是可以,我们使用 Toloka 和 ClearML 实现了这一点。
在此步骤中,我们使用了 Toloka 众包平台。这是一个可以创建标注项目并将其分发给世界各地远程标注者的工具。
项目的第一步是创建界面和详细说明。在这种情况下,我们想问两个问题
- 客观问题:关于食物的类型,是固体还是液体
- 主观问题:关于一个人是否觉得食物开胃
我们使用了您在下方看到的界面
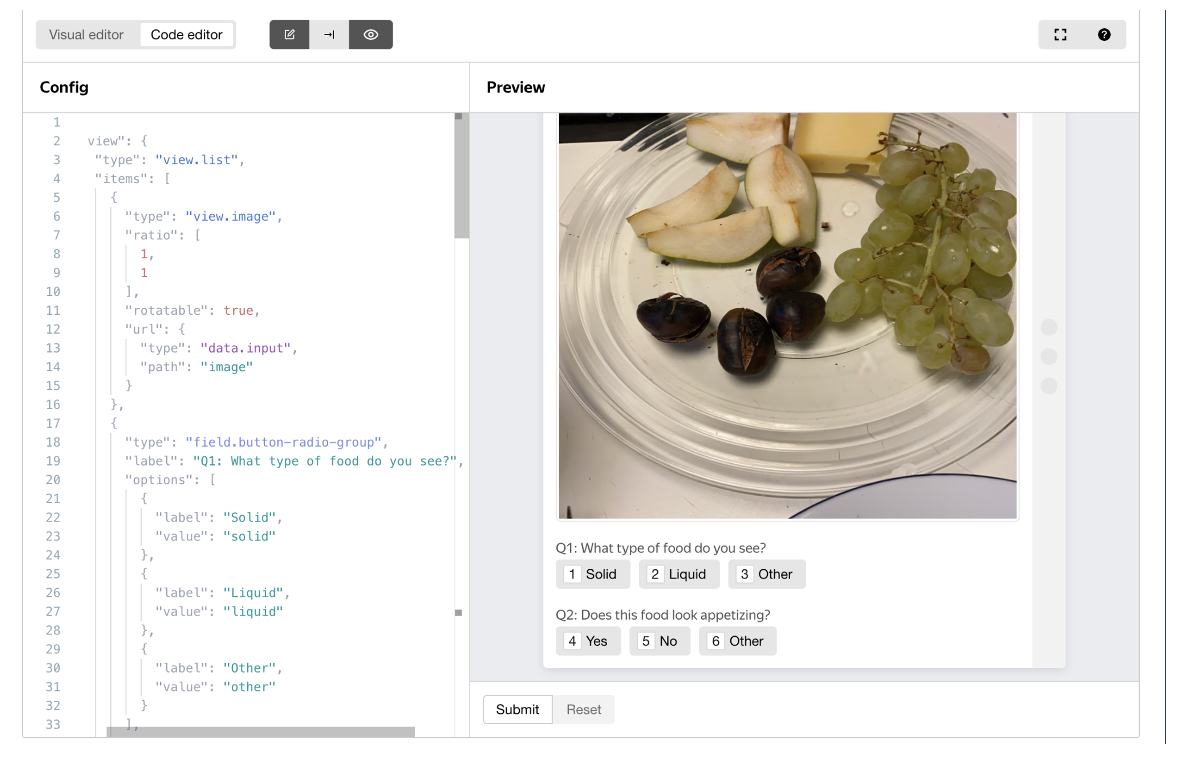
此外,在说明中,我们清楚地定义了固体和液体食物是什么,给出了示例,并提供了边缘情况。
说明和界面准备好后,我们就需要邀请执行者参与我们的项目。Toloka 的标注者遍布世界各地,因此我们必须仔细选择谁能够参与我们的项目。

由于我们提供的说明是用英文编写的,我们决定只邀请说英语的人,并使用考试来测试他们对说明的理解程度。考试包含10个任务,我们测试了他们对第一个关于食物类型的问题的回答。我们有5个固体、4个液体和1个应标记为其他的边缘情况。我们要求考试成绩达到100%才能进入标注项目。
下图显示了参加考试的人员给出的答案分布。
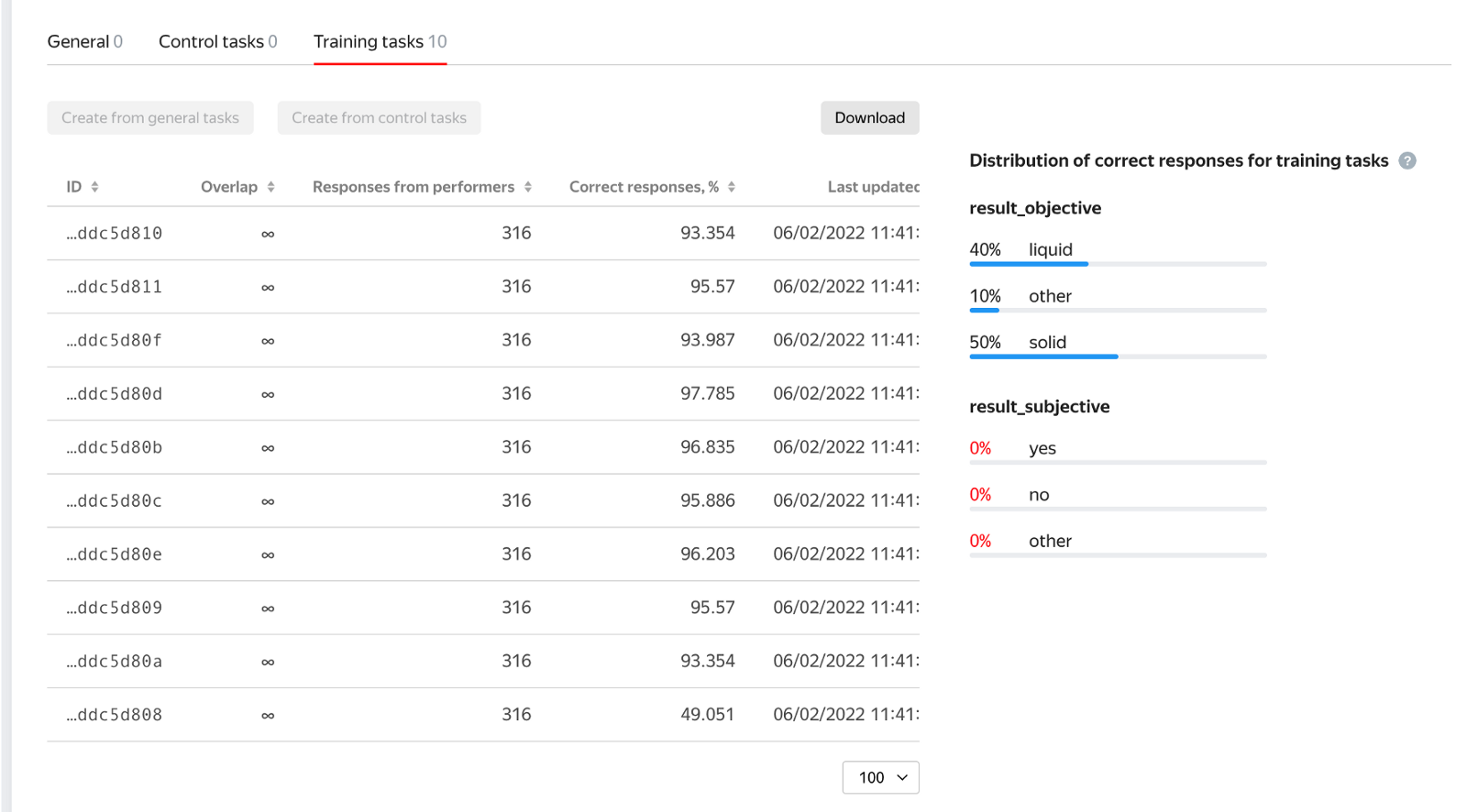
幸运的是,我们过滤掉了回答这个问题不正确的人。
我们为控制标注质量而实施的下一步措施是使用
- 快速响应规则,
- 重叠(标注),
- 和控制任务。
当用户对给定任务响应过快时,会使用快速响应规则。这意味着他甚至没有时间仔细查看和检查任务,很可能无法给出正确答案。
另一方面,重叠(标注)让我们对答案更有信心,因为每个任务都会分发给几个标注者,他们的结果可以汇总。在这种情况下,我们使用了三次重叠。
我们还在正常任务之间穿插了控制任务。这意味着,每分配给标注者九个任务,就会有一个控制任务来检查他给出的答案是否正确。如果标注者对控制任务的回答不正确,他将被从项目中移除。
通过这次标注,我们为980张图片进行了标注,每张图片使用了三位不同的标注者。收集结果大约花了30分钟,费用为6.54美元。共有105人参与了这个项目。
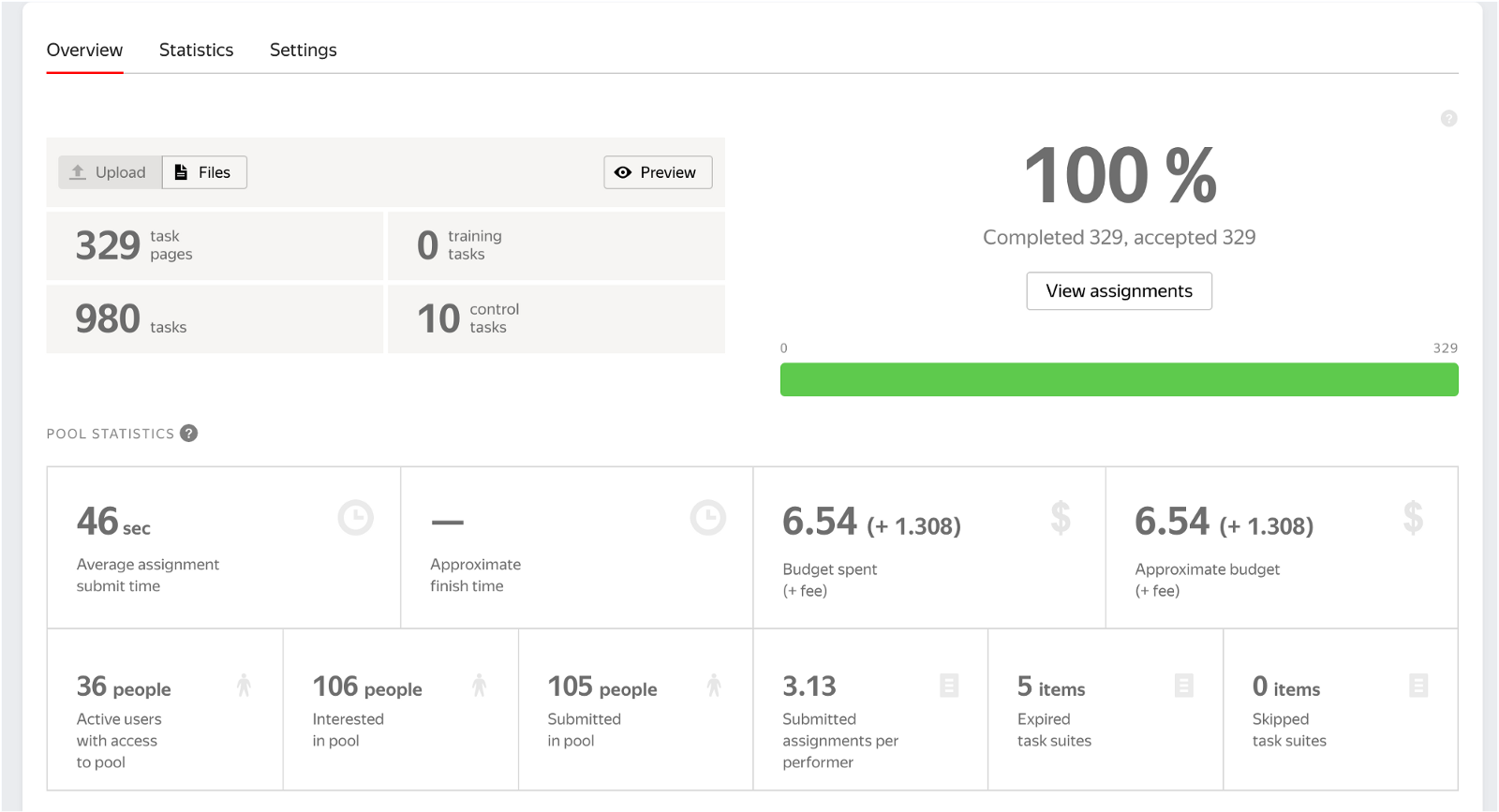
现在可以将结果传递给 ClearML 工具,用于对收集的数据进行版本控制和分析。如果您的项目需要其他类型的标注,您可以在 此处 浏览不同的标注演示。
数据管理
ClearML,一个开源的 MLOps 平台,提供了一个名为 ClearML Data 的数据管理工具,它可以与平台的其余部分无缝集成。
一旦创建了标注好的数据集,我们只需将其注册到 ClearML 中。
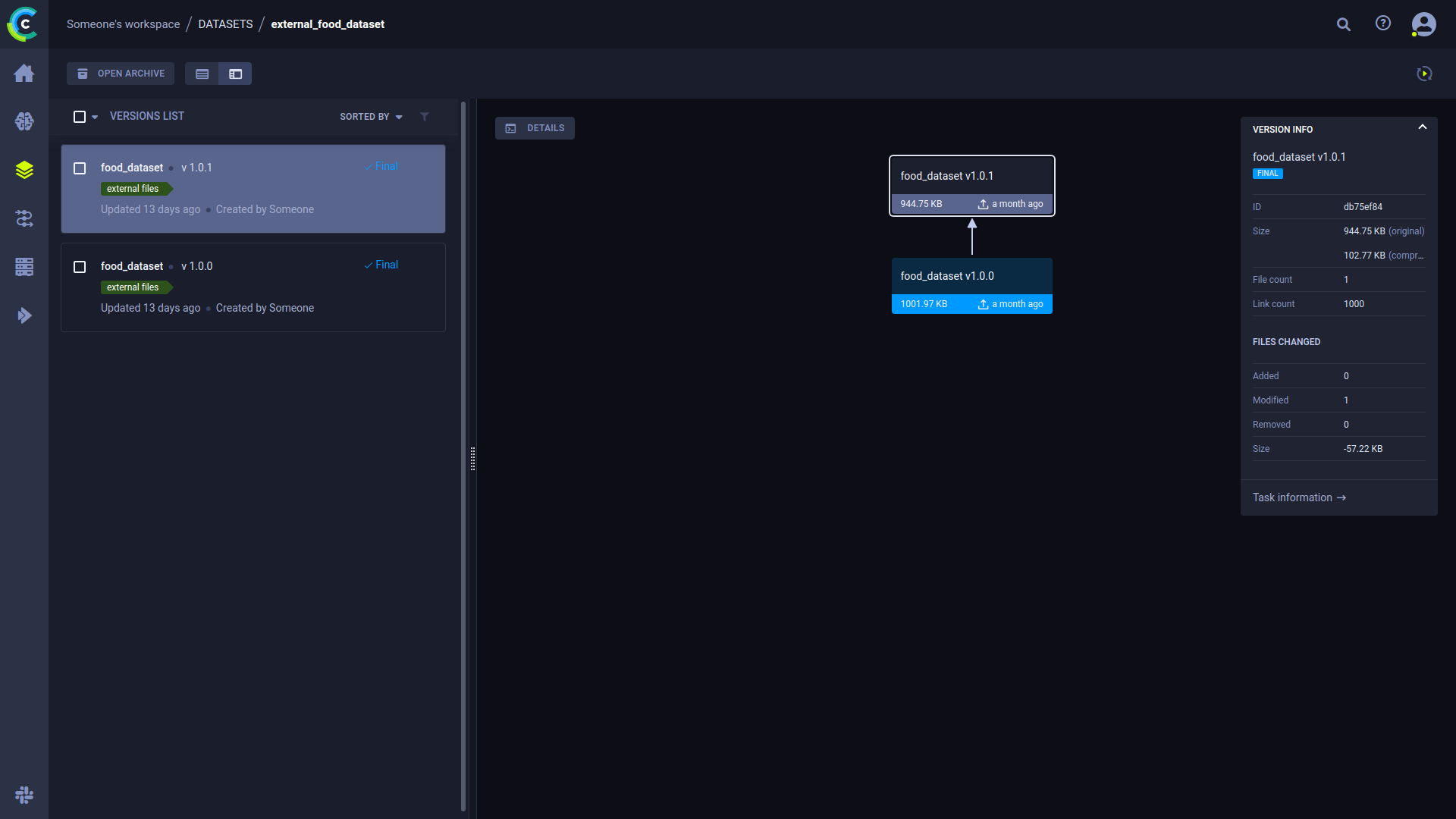
一旦数据在 ClearML 中注册,用户就可以创建和查看数据血缘树、添加数据预览、元数据,甚至像标签分布这样的图表!这意味着所有信息都被封装在一个单一实体中。
在我们的案例中,我们可以将数据集标注成本保存为元数据。我们还可以存储其他标注参数,例如说明、语言参数或其他任何内容,并将其附加到数据集中,以便以后引用。
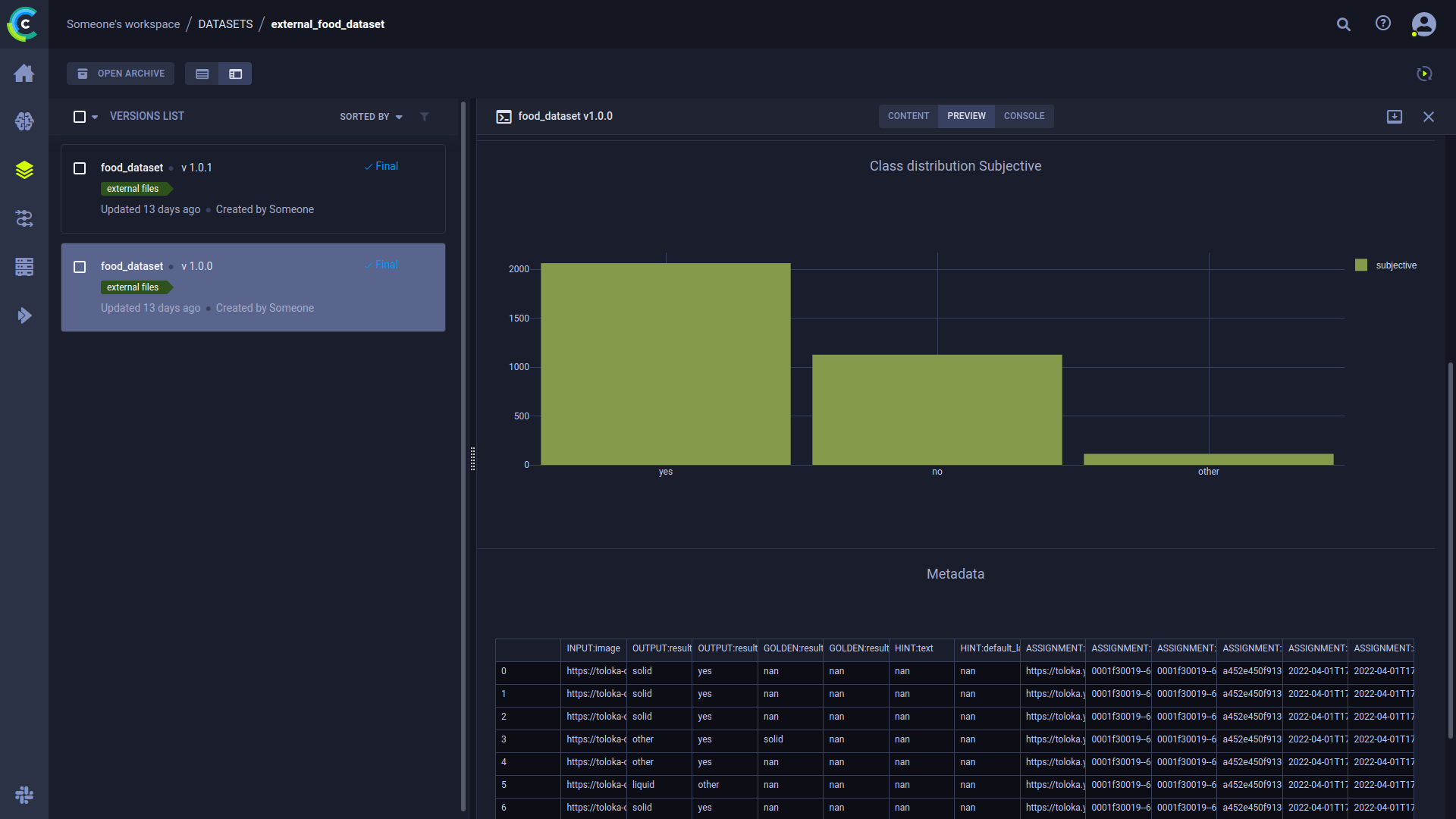
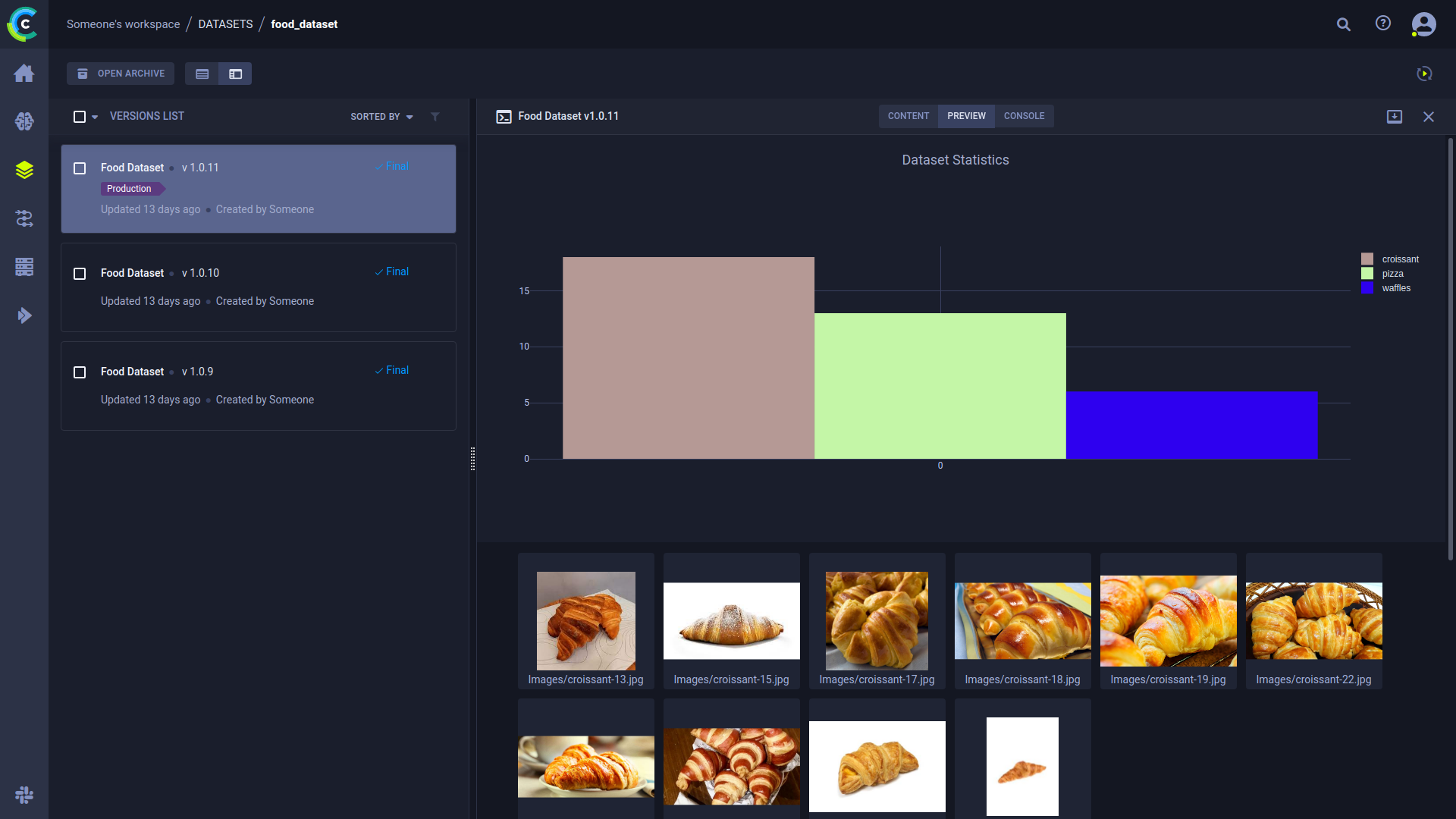
数据现在已经被跟踪了,那接下来呢?
好的,现在数据已经被跟踪和管理了,您可能会问,那接下来是什么?
好吧,现在是将其连接到 ClearML 实验管理 解决方案的强大之处!
只需一行代码,用户就可以将数据集获取到目标机器,完全抽象化数据的实际存储位置(无论是在专用的 ClearML 服务器上,还是存储在您喜欢的云服务提供商的存储空间中)。
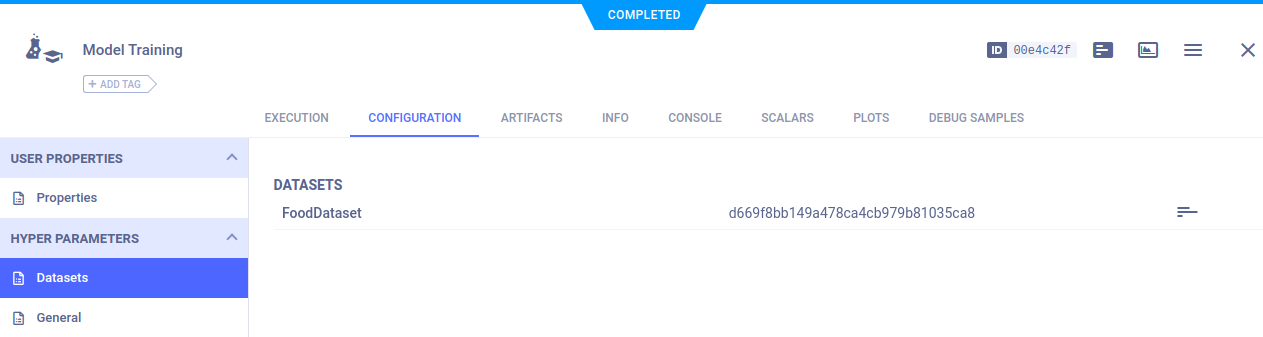
ClearML Data 会为您从存储位置获取数据,并对其进行缓存,这样后续运行就不需要重新下载数据了!
连接到 ClearML 的实验管理解决方案使用户可以享受它提供的所有功能,比如实验比较,我们可以比较两个实验,其中唯一的区别是标注成本,并实际看看为标注支付更多费用对模型有什么影响!
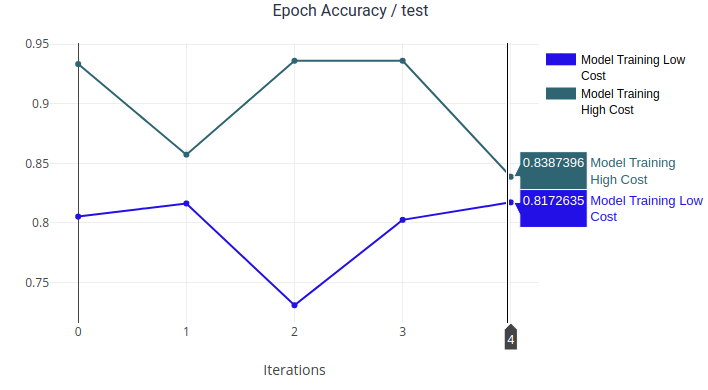
而且,既然我们将成本保存为元数据,如果我们使用 Toloka 的 SDK 自动化标注任务,我们就可以将 Toloka 和 ClearML 结合起来,自动对标注成本进行超参数优化,从而弄清楚我们到底应该在标注上投入多少!
使用 Hyper-Datasets 提升您的数据管理水平
需要从您的数据集管理工具中获得更多价值?请查看 Hyper-Datasets!
Hyper-Datasets 本质上是将标注和元数据存储在数据库中,以便在训练/测试时进行查询!
用户可以将数据上的查询(称为 DataViews)连接到实验并对其进行版本控制!使用 DataViews 可以让您在需要时轻松获取数据集(甚至多个数据集)的特定子集,这为数据管理提供了另一个层面的粒度。

如果您需要更好的数据统计信息、更好地控制网络输入的数据,以及如果您处理数据的子集并想避免数据重复(这既消耗存储空间又耗费管理精力),那么 DataViews 和 Hyper-Dataset 是很好的选择。
在本文中,您学习了如何使用 Toloka 和 ClearML 工具构建您的 ML 数据工作流,并以食物数据集为例。如果您想查看此博客中概述的步骤所需的所有代码,请查看我们准备的 colab notebook。
此外,我们以网络研讨会的形式展示了我们的实验结果,并为您保存了录像(Toloka 部分、 ClearML 部分)。
您觉得这份指南对管理您自己的 ML 项目数据有用吗?如果您有任何反馈或想询问有关此项目的问题,请在下方留言。
这篇博文由 Toloka 数据布道师 Magdalena Konkiewicz,以及 ClearML 的 Victor Sonck 和 Erez Schnaider 撰写。原文 发表在此。
