
如果我想在 ClearML 上部署 Huggingface 模型怎么办?从何开始?
通常,机器学习工程师现在都知道,在生产环境中部署模型时,一个好的模型服务引擎是无价的。如今,NVIDIA 的 Triton 推理引擎是一个流行的选择,但在某些方面它有所欠缺。
特别是,定义自定义模型监控指标可能会很麻烦,因为开发者必须使用 Triton 的底层 C API 来集成它们。此外,运行自定义 Python 代码(例如用于预处理和后处理)也不是非常直接。虽然可以定义自定义 Python 端点,然后使用集成结构将它们组合成一个 API 调用。但这种结构不仅繁琐,而且还会阻止你自动扩展(通常受 CPU 限制的)预处理和后处理代码。在 Triton 中可以扩展端点,但只能手动进行,这在这种情况下并不理想,可能导致实际模型的 GPU 服务成为瓶颈。
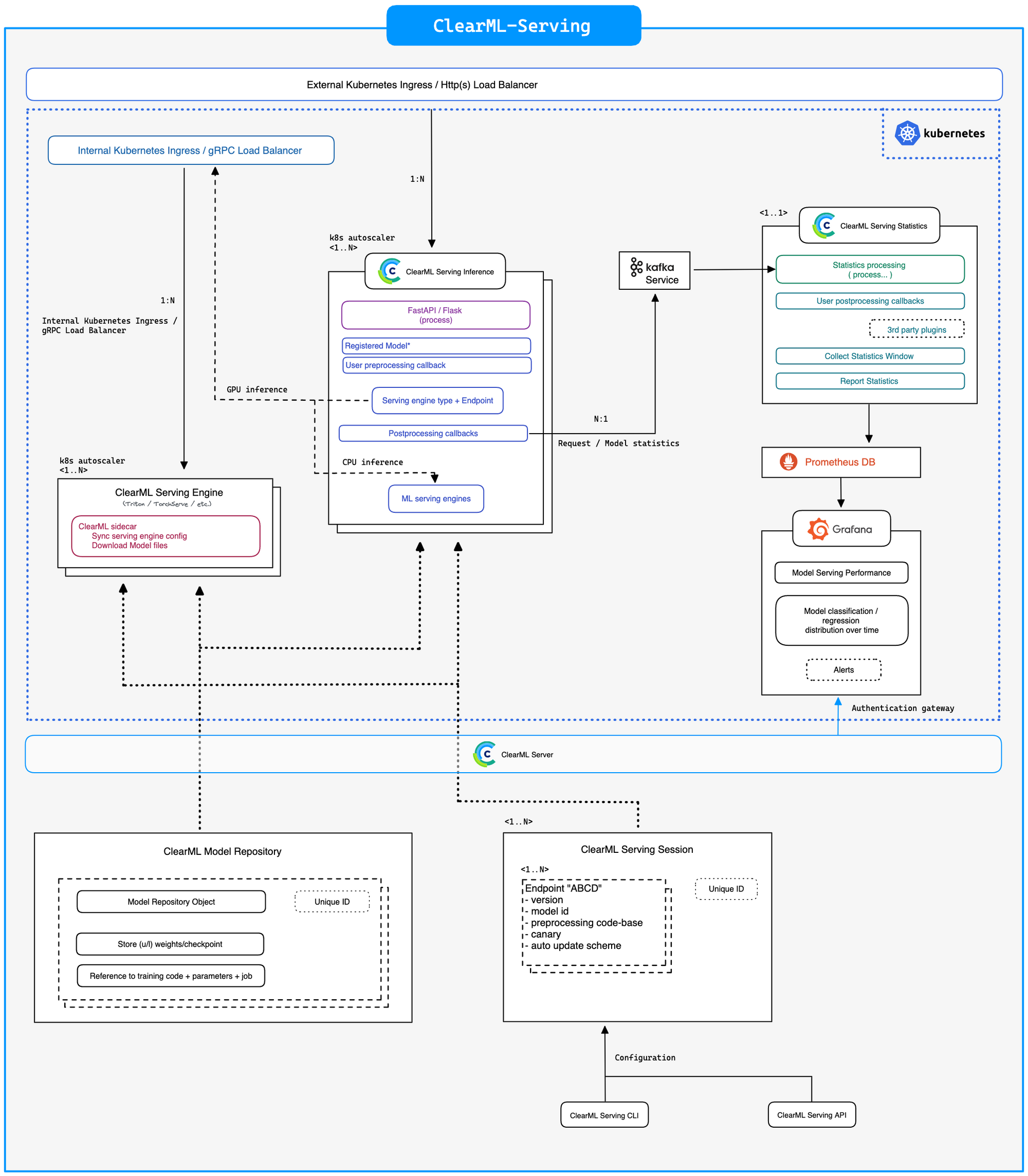
ClearML-Serving 架构
为了解决 Triton 的这些问题,同时仍然利用其出色的性能,我们创建了 ClearML-Serving。它创建了一个完全自动扩展的推理容器,可以运行自定义的预处理和后处理代码,并捕获任何用户定义的指标并将其传输到 Prometheus 和 Grafana。
除了这些优点之外,ClearML-Serving 如果你愿意的话,还可以很好地融入 ClearML 生态系统的其他部分。轻松部署已使用实验管理器存储的模型,并全面支持自动化,如触发器和管道。
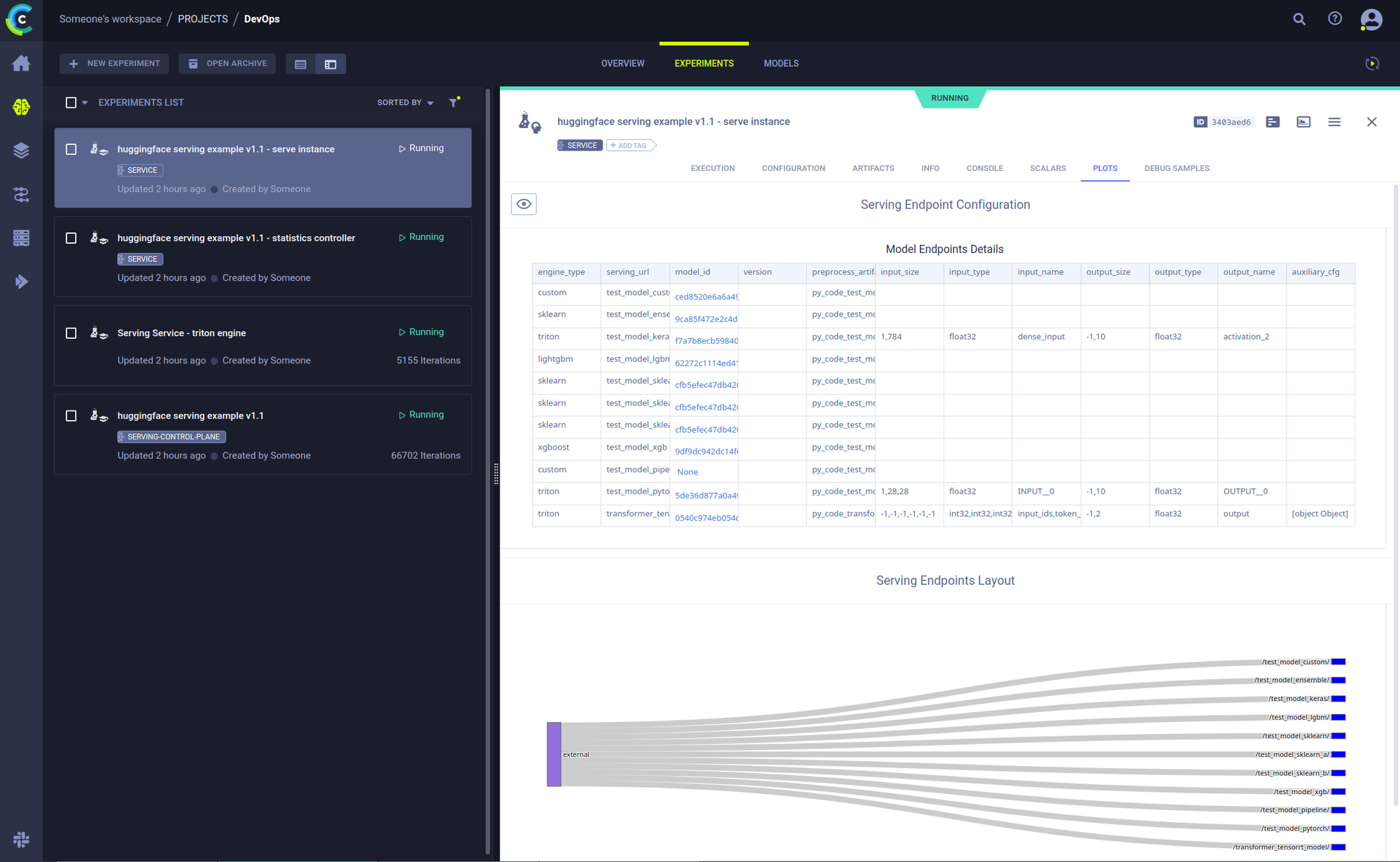
正如何 ClearML 中的其他一切一样,服务实例是一个任务(Task),它会跟踪控制台输出、版本历史记录和基本机器监控。简而言之,它为你最喜欢的开源 MLOps 工具箱又增加了一个开源工具,供你使用。
部署 Huggingface 模型
这篇博文将介绍在部署模型时需要注意的一些资源、发现和最佳实践。ClearML-Serving 仓库中的示例将一步一步地向你展示如何在自己的机器上进行设置。
模型和分词器
现在 Huggingface 上可用的大多数模型都是用 Pytorch 构建的。从技术上讲,Triton 实际上开箱即用地支持 Pytorch 模型,所以如果你愿意,可以直接以那种方式提供模型服务。但这不仅仅是模型本身。
许多模型需要一个被称为分词器(tokenizer)的东西,用于在将传入数据发送到模型之前对其进行预处理。Huggingface 自己有一个很不错的视频解释了这个概念。撇开更复杂的方法不谈,它本质上是一个预先制作好的查找表,将文本输入转换为模型可以处理的数字。
指望用户请求(例如网页发起的 API 调用)在客户端进行分词是不好的做法。这意味着分词器会分散在每一个想要向服务器发起 API 请求的设备或端点上,并且与模型本身同步更新将是一场噩梦。
相反,将分词器作为预处理步骤部署在服务器端,紧挨着请求到达模型服务器之前,这样做非常有意义。ClearML-Serving 允许你指定一个自定义的 Python 预处理类来完成这项工作,使得这变得非常容易。
"""Hugginface preprocessing module for ClearML Serving."""
from typing import Any
from transformers import AutoTokenizer, PreTrainedTokenizer, TensorType
# Notice Preprocess class Must be named "Preprocess"
class Preprocess:
"""Processing class will be run by the ClearML inference services before and after each request."""
def __init__(self):
"""Set internal state, this will be called only once. (i.e. not per request)."""
self.tokenizer: PreTrainedTokenizer = AutoTokenizer.from_pretrained("philschmid/MiniLM-L6-H384-uncased-sst2")
def preprocess(self, body: dict, state: dict, collect_custom_statistics_fn=None) -> Any:
"""Will be run when a request comes into the ClearML inference service."""
tokens: BatchEncoding = self.tokenizer(
text=body['text'], return_tensors=TensorType.NUMPY, padding=True, pad_to_multiple_of=8
)
return [tokens["input_ids"].tolist(), tokens["token_type_ids"].tolist(), tokens["attention_mask"].tolist()]
def postprocess(self, data: Any, state: dict, collect_custom_statistics_fn=None) -> dict:
"""Will be run whan a request comes back from the Triton Engine."""
# post process the data returned from the model inference engine
# data is the return value from model prediction we will put is inside a return value as Y
return {'data': data.tolist()}
统领一切的博文
由 Michaël Benesty(又称 pommedeterresautee 这个很棒的名字)撰写的这篇博文,是开始在 Triton 上部署 Huggingface 模型的绝佳资源。
随附的GitHub 仓库提供了一个 convert_model 命令,可以接收一个 Huggingface 模型并将其转换为 ONNX 格式,然后可以使用 TensorRT 进行优化。
这是一个很好的开始,即使转换不能立即成功,代码本身也提供了一个非常好的样板,可以帮助你启动自己的转换流程。模型转换不是一项简单的任务,所以任何在这方面做出贡献的人都是天赐之福。
关于 TensorRT, ONNX 和 Triton 版本的注意事项
“深度学习模型转换”大致等于“依赖地狱”。建议使用 Docker 容器并保持极大的耐心。以下是一些需要考虑的事项的简要总结。
Triton 只提供为其自身版本精确编译的 TensorRT 模型二进制文件,别无其他。不提供向后兼容性。
ONNX 版本与 TensorRT 版本紧密关联,以确保兼容性。你可以在此处查看兼容性矩阵。
更不用说原始模型是使用哪个版本的 Pytorch 训练的,以及它与 ONNX 的关系了。
transformer-deploy docker 镜像所使用的 Triton 版本很可能与 ClearML-Serving 在任何给定时间使用的版本不同,这将在后续引发问题。请查看此页面,了解哪个 Triton 容器中附带了哪个 TensorRT 版本。
如果它们不匹配,ClearML Triton 镜像已经为 Triton 的几个不同版本由我们构建。如果这些都不符合你的需求,请在本地使用正确的 Triton 版本构建镜像,并在设置堆栈时确保 docker compose 能够识别它;或者在本地使用正确的版本构建 transformers-deploy 镜像,并用它来运行模型转换。你的模型必须使用完全相同的 TensorRT 版本进行优化,否则将无法提供服务!
部署模型
阅读完所有内容后,就可以开始实际部署了。这不是本博文的重点,要了解更多信息,请查看这里的 README。但简而言之,要让一切正常运行(当然,在 ClearML-Serving 初始化设置之后),只需几个步骤。
- 上传模型文件
clearml-serving --id <your_service_ID> model upload --name "Transformer TensorRT" --project "Hugginface Serving" --path model.bin
- 为其创建端点
clearml-serving --id <your_service_ID> model add --engine triton --endpoint "transformer_tensorrt_model" --model-id <your_model_ID> --preprocess examples/huggingface_tensorrt/preprocessing.py --input-size "[-1, -1]" "[-1, -1]" "[-1, -1]" --input-type int32 int32 int32 --input-name "input_ids" "token_type_ids" "attention_mask" --output-size "[-1, 2]" --output-type float32 --output-name "output" --aux-config platform=\\"tensorrt_plan\\" default_model_filename=\\"model.bin\\"
热插拔模型与金丝雀部署
使用 ClearML-Serving 可以做的一件很酷的事情是,只需使用命令行即可无缝地将模型更新到新版本。ClearML 服务提供了自动模型部署和升级功能,直接与模型仓库和 API 相连接。
配置模型自动部署后,当你在 ClearML 模型仓库中“发布”或“标记”新模型时,新版本模型将自动部署。这个自动化接口简化了 CI/CD 模型部署过程,因为一个 API 调用就可以自动部署(或移除)服务中的模型。
clearml-serving --id <service_id> model auto-update --engine triton --endpoint "transformer_tensorrt_model" --preprocess "preprocess.py" --name "Transformer TensorRT" --project "Hugginface Serving" --max-versions 2
你甚至可以设置金丝雀部署,让 x% 的用户使用模型 A,100-x% 的用户使用模型 B,当然这完全可配置 🙂
# First add 2 endpoints corresponding to your requirements
clearml-serving --id <service_id> model canary --endpoint "transformer_tensorrt_model" --weights 0.1 0.9 --input-endpoints transformer_tensorrt_model/2 transformer_tensorrt_model/1
后续步骤
在后续的博文中,我们计划在我们自己的基准测试中补充上述博文提供的出色性能数据。了解独立扩展的可能性对最终推理速度有多大贡献将是非常有趣的。
此外,我们还将向你展示如何为服务实例添加自定义指标,这将使你能够使用 Prometheus 和 Grafana 监控你的所有端点列表。
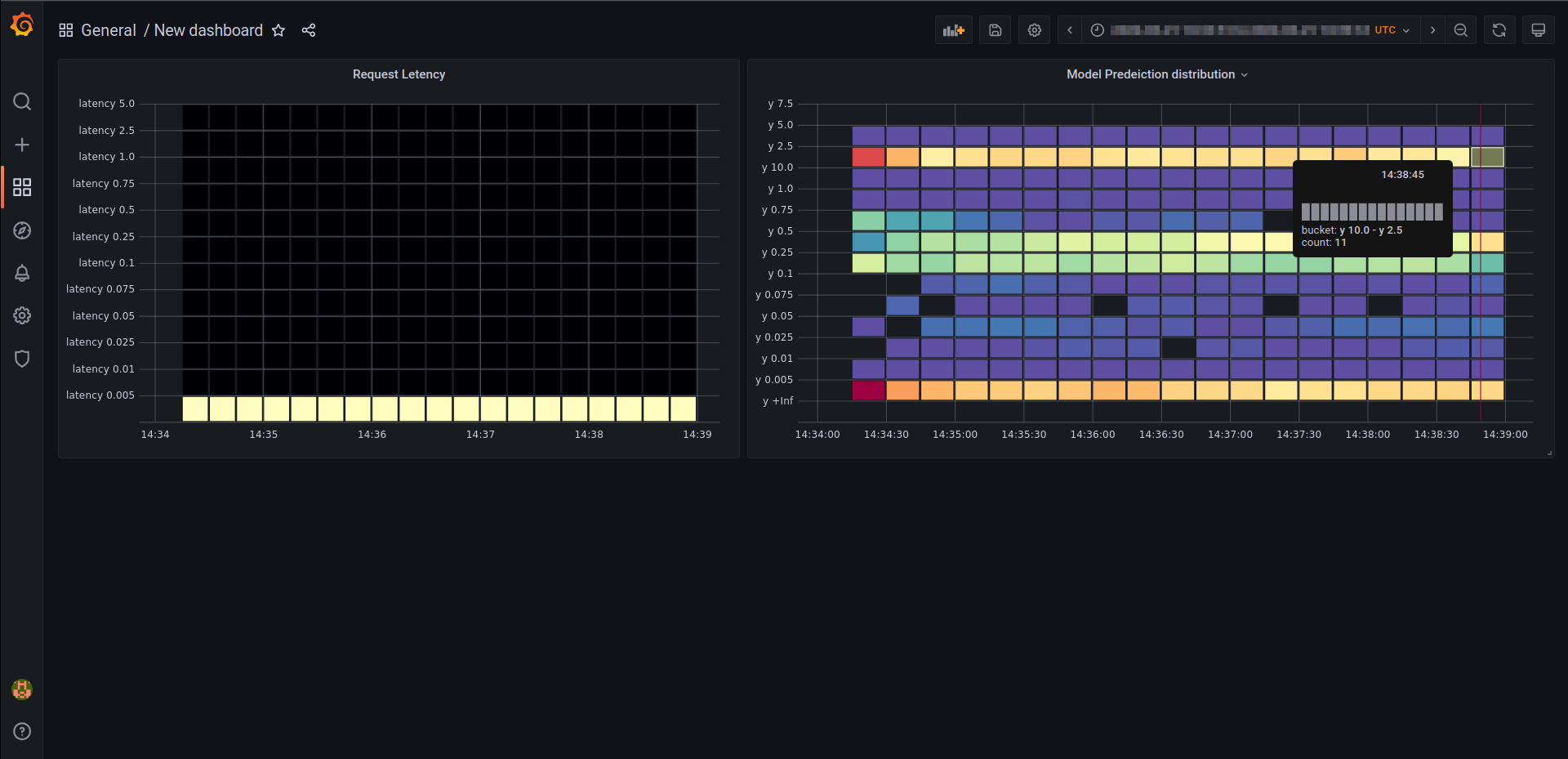
敬请期待!
