经 PyTorch 和作者许可在此转载。原帖发布于 PyTorch Medium,请点击此处。
作者:Izik Golan — Trigo 深度学习研究员

Trigo 介绍
Trigo 是零售市场基于 AI 和计算机视觉的无结账系统提供商,实现了无摩擦结账以及一系列其他店内运营和营销解决方案,例如预测库存管理、安全和欺诈预防、价格优化以及事件驱动营销。

该系统基于安装在天花板上的现成摄像头和传感器,由专有的深度学习算法驱动,旨在绘制和分析店内每个物体的位置和移动。当顾客从货架上拿起商品时,系统会自动检测该事件并将其添加到虚拟购物清单中。顾客购物完成后,可以直接走出商店,无需通过传统结账。离开商店时,顾客会被自动扣款,收据将发送到他们的移动设备上。
我们需要解决的任务
为了构建无结账系统,我们采用了多种 AI 和 PyTorch 模型及技术,并在其上叠加了应用逻辑层,将所有这些推断组合成一个连贯的决策。这与自动驾驶汽车非常相似,自动驾驶汽车有不同的系统,例如车道检测、避障、GPS 定位、路径查找等,其上有一个统一的逻辑层,将所有不同的传感器和模型结合起来,为车辆在任何特定时刻做出单一决策。
为了实现这一目标,我们建立了一个非常复杂的系统来开发和部署对象检测、跟踪、姿态估计等模型。这是由多个团队通力合作完成的,每个团队负责系统的不同方面。
工作流程与基础设施目标
拥有强大的数据科学和工程团队,我们对基础设施和工作流程设计有两个重点目标。这些目标对我们至关重要,因为它们代表了尝试构建可部署 AI 解决方案的公司经常遇到的痛点
- 数据科学团队到工程团队的快速周转。 对我们来说,加快从研究到生产的周期非常重要,这样我们可以更快地迭代和创新。因此,解决构建核心算法和 DL 模型的数据科学团队与负责构建上层应用逻辑的工程团队之间的断层至关重要。
- 像软件工程一样管理 AI / DL 生命周期。 尽管 AI 开发和部署与传统软件相比是一个非常不同的过程,但作为工程师,我们知道必须引入一些软件管理的核心概念,以实现高效的 AI / DL 开发和部署。这包括在 AI / DL 管道中实施版本控制、协作、DevOps 和 CI/CD 的相同最佳实践。
为了实现这些目标,最重要的任务是选择合适的工具,并围绕这些工具为我们的独特需求创造了“独门秘方”。
PyTorch
我们需要做的第一个选择是使用哪种机器学习框架。我们选择了 PyTorch。做出这一初步选择的主要原因如下
- 调试简单快捷。
- 通过代码构建复杂灵活的网络非常容易。
- 通过利用 PyTorch 内置的灵活性,我们能够快速迭代新想法并测试其性能。后来,令我们惊喜的是,我们发现使用 PyTorch-Ignite 还可以减少我们的样板代码,这反过来又使我们能够进一步加快这一过程。
起初我们不确定 PyTorch 是否能作为生产就绪引擎,但当 PyTorch 1.0 发布时,我们的耐心得到了回报。很明显,即使增加了设计和调试的灵活性,框架的原始 GPU 性能也没有受到影响。
Allegro AI Trains
对于基础设施工具,我们选择了 Allegro AI Trains。哇,这真是给我们带来了巨大的回报!
在选择 Trains 之前,我们测试了所有能找到的适用于 AI / DL 管理的开源/免费/付费产品。Trains 是我们测试的最后一个实验管理器,就在其测试版在 CVPR’19 期间发布到 GitHub 上之后。
到那时,我们已经在使用其他实验管理器方面积累了相当多的经验,并且了解了我们的需求。没有什么东西是完美的,因此 Trains 的第一个版本远非完美也不足为奇。然而,它在两件事上做得非常好
- 与我们的代码集成起来毫无麻烦(他们的“自动魔法”承诺确实兑现了)。
- 如果它未能记录/执行某些操作,它没有导致我们的实验崩溃。
起初,我们将代码日志记录和 Python 包视为一个很好的工具,可以更好地理解模型训练会话之间的性能差异,但很快就了解到了使用 Trains 的真正价值。我们在管理开发与部署生命周期方面取得的重大飞跃,是在我们将 Trains Agent 集成到我们的工作流程中时发生的。Trains Agent 本质上是一个守护进程,它可以为你启动一个容器并运行你的代码。真正的秘诀是,你根本无需构建那个容器!
这对于我们的研究团队来说意义重大。在使用 Trains 之前,每当他们需要将新包更新到容器中、代码库发生变化、驱动不匹配等问题时,他们都会不断地麻烦 DevOps 团队。有了 Trains 和 Trains Agent,这一切都不复存在了!
我们的开发过程
为了实现我们的核心工作流程目标,并充分利用 PyTorch 和 Trains 的最佳功能,以下是我们构建的管道概述,我们发现这是最有效的方式来开发和部署到生产环境
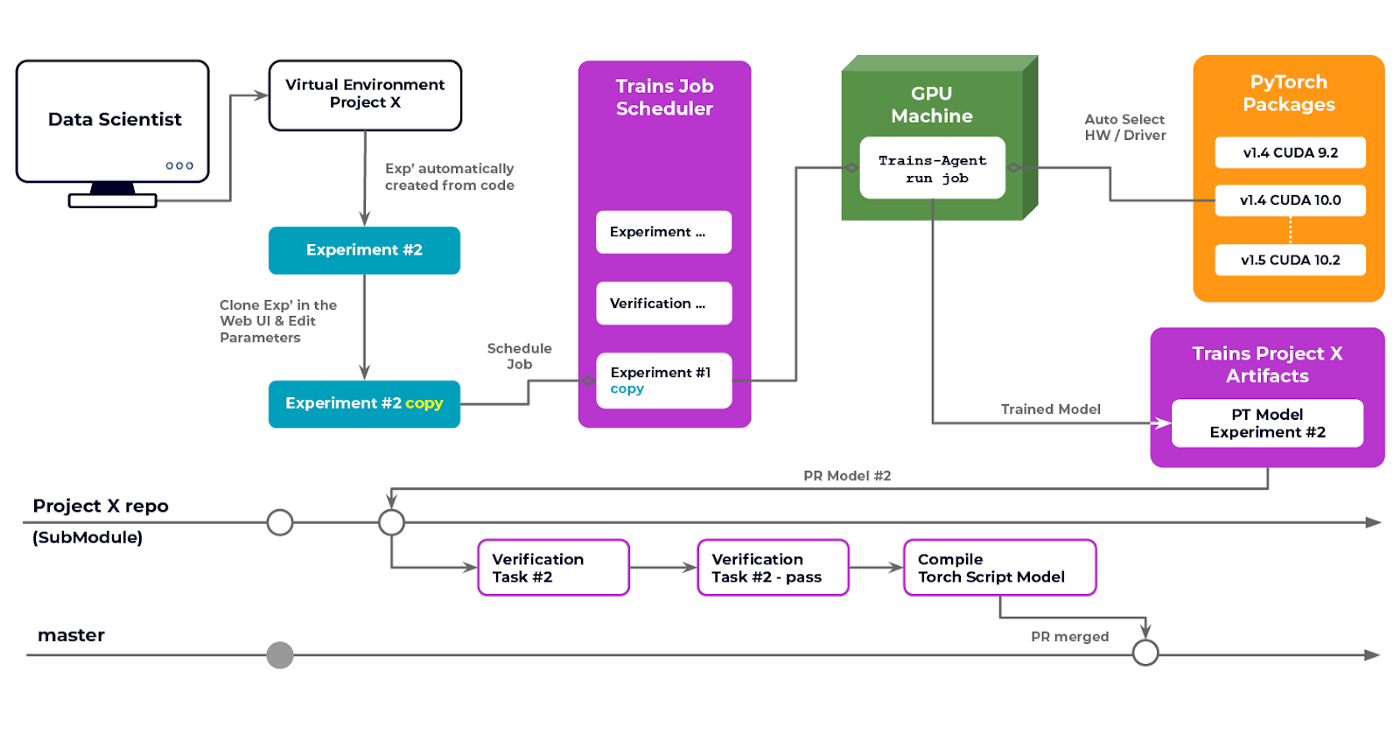
每位研究人员都有自己的专用机器,拥有完整的 root 权限,可以在其中安装他们喜欢的任何包/库。事实上,我们的数据科学家为他们正在进行的每个项目都拥有一套独特的 Python 虚拟环境。
每位研究人员都在自己的机器上运行和调试代码,通常结合在本地运行的 PyTorch 和 Tensorboard,包括在代码开头调用 Trains 的两行初始化代码。内部调试通常使用 Tensorboard 及其所有巧妙的功能来完成。
一旦代码正确执行,我们就会进入 Trains Web UI,只需两次点击即可克隆实验(执行/运行),更改一些参数并安排在我们的本地或云机器上的众多 GPU 之一上执行。最好的部分是我们根本无需打包我们的代码库。Trains Agent 会自动完成这一切。此外,它会捕获所有未提交的 Git 更改并进行部署。由于 PyTorch 实际上为特定的 CUDA 设备维护了全套的 Torch 版本,Trains Agent 会实时将特定的包与正在运行的硬件进行匹配,因此我们总能获得与我们使用的特定硬件最匹配的 PyTorch 版本(是的,我们这里有许多不同的 GPU 型号)。
最关键的项目实际上是链条上的最后一环:如何“发布”他们的模型?问题的症结在于:当你的复杂系统依赖于多个模块的性能时,你不能将一个模块合并到主分支中,而无需先验证整个系统的性能没有因更改而下降。
这意味着如果我们想快速推出更新和改进,CI 是必不可少的。因此,我们设计了以下存储库结构
- 我们有一个主要的存储库,其中包含应用逻辑本身。这个存储库使用我们单独训练的不同模型,并将它们组合成一个决策引擎。
- 然后我们有 Git 子模块,每个子模块用于不同的训练模型(例如对象检测、姿态估计等)。
对于每个存储库(例如对象检测),我们配置了 CI,以便在每次创建拉取请求时启动一个测试实验。这个测试针对一个盲数据集运行模型(盲的意思是您无法访问该数据集,因此我们知道没有人会不小心在其上进行训练)。如果性能(即准确率)结果低于当前主分支,则测试失败。
这个过程确保我们不会合并一个性能没有提升的模型代码库。当然,模型本身并不存储在 Git 仓库中,而只存储模型文件的链接。事实上,我们甚至没有这样做。我们只存储生成该模型的实验 ID。我们这样做的原因有两个
- 我们想快速地(即通过阅读代码)了解模型是由谁 / 在哪里创建的。
- 我们可以利用 Trains 自动将我们训练好的模型上传到我们的服务器。
这对我们来说确实是一个端到端的解决方案,因为我们无需担心实际的工件存放在哪里。
一旦拉取请求合并到特定项目的主分支中,我们可以将子模块提交到应用存储库中。这反过来会触发一个系统范围的质量控制(QC)过程,这个过程会使用整个系统,针对一个盲数据集(在我们的案例中是一组系统永远无法访问的视频)运行,并确保整体性能没有下降。此过程成功完成后,应用当前状态将在其主分支中得到更新。
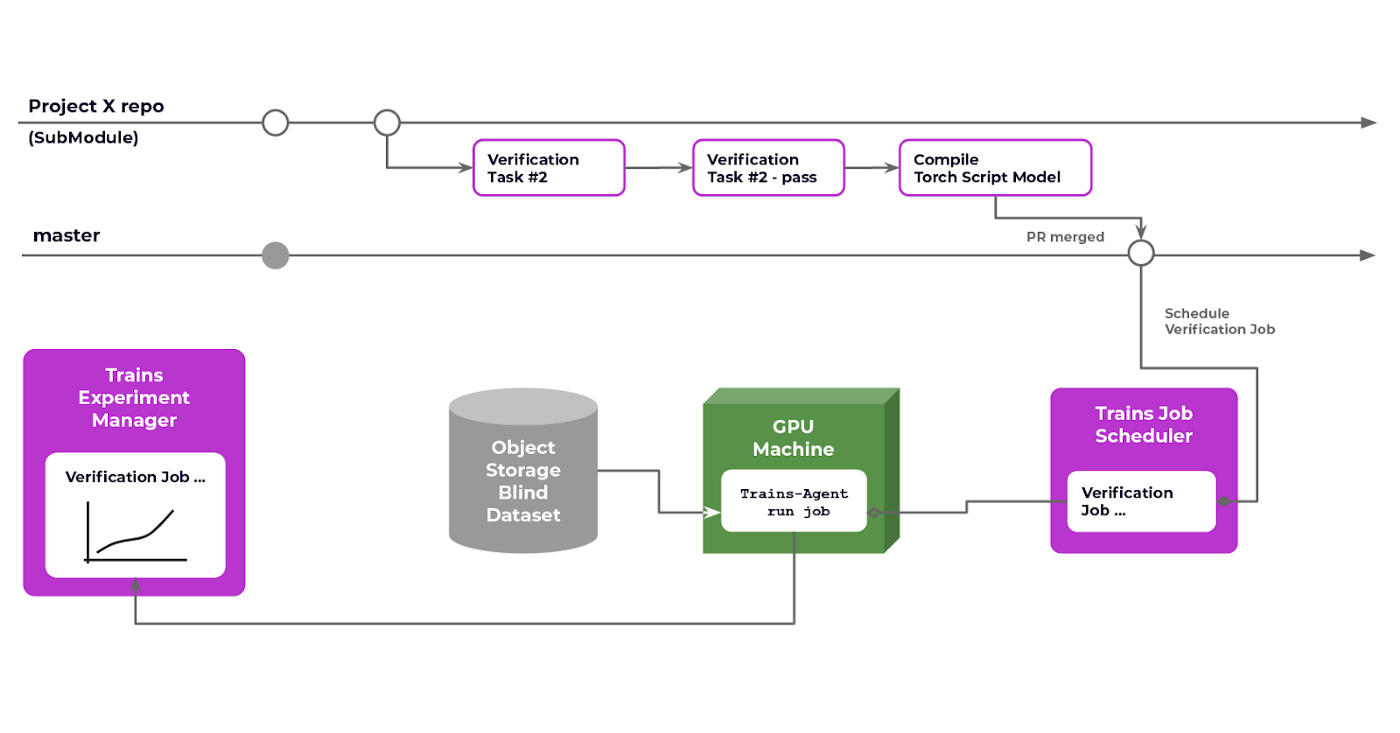
此设置的优势
这个过程可能听起来有些过度,但实际上它非常易于管理(当然,一旦设置好之后)并且极其容易操作。
例如,我们很快就明白需要确保每个模型都在所有不同对象上均等地进行训练。否则它们往往在稀有对象上表现不佳。假设我们的对象检测拉取请求在质量控制阶段(我们对模型推理测试阶段的命名)失败了。测试本身在 Trains 中创建了一个新实验,CI 日志包含指向该实验的直接链接。现在我们可以查看模型的实际性能了。我们还添加了调试图像,以便每次模型未能检测到对象时,我们都会绘制图像以及预期/检测到的结果。这些调试信息对于我们理解模型在现实生活中(即在盲数据集上)的表现至关重要,并使我们能够更好地理解失败点并消除它们。
一个恰当的例子是,听起来很小的事情,在我们的一个模型中,我们未能正确平衡数据。我们设置的 DL CI 过程使我们免于部署一个模型,尽管它总体上表现更好,但在某些个别情况下会完全失败。调试信息非常宝贵,因为它帮助我们快速识别并随后修复了问题,并最终为与我们的一位客户成功进行 Beta 测试做好了准备。
结论
希望我们在 Trigo 构建的成果能给你带来启发。我们现在坚信将 CI 应用于深度学习,并且是 PyTorch 和 Allegro Trains 的忠实拥趸——这两个工具是未来 AI 模型开发和部署最先进技术的基础。
期待很快在我们的零售部署中与您相见 😉
