作者:Erez Schnaider,ClearML 技术产品营销经理
克服 AI 工作负载中的 GPU 瓶颈
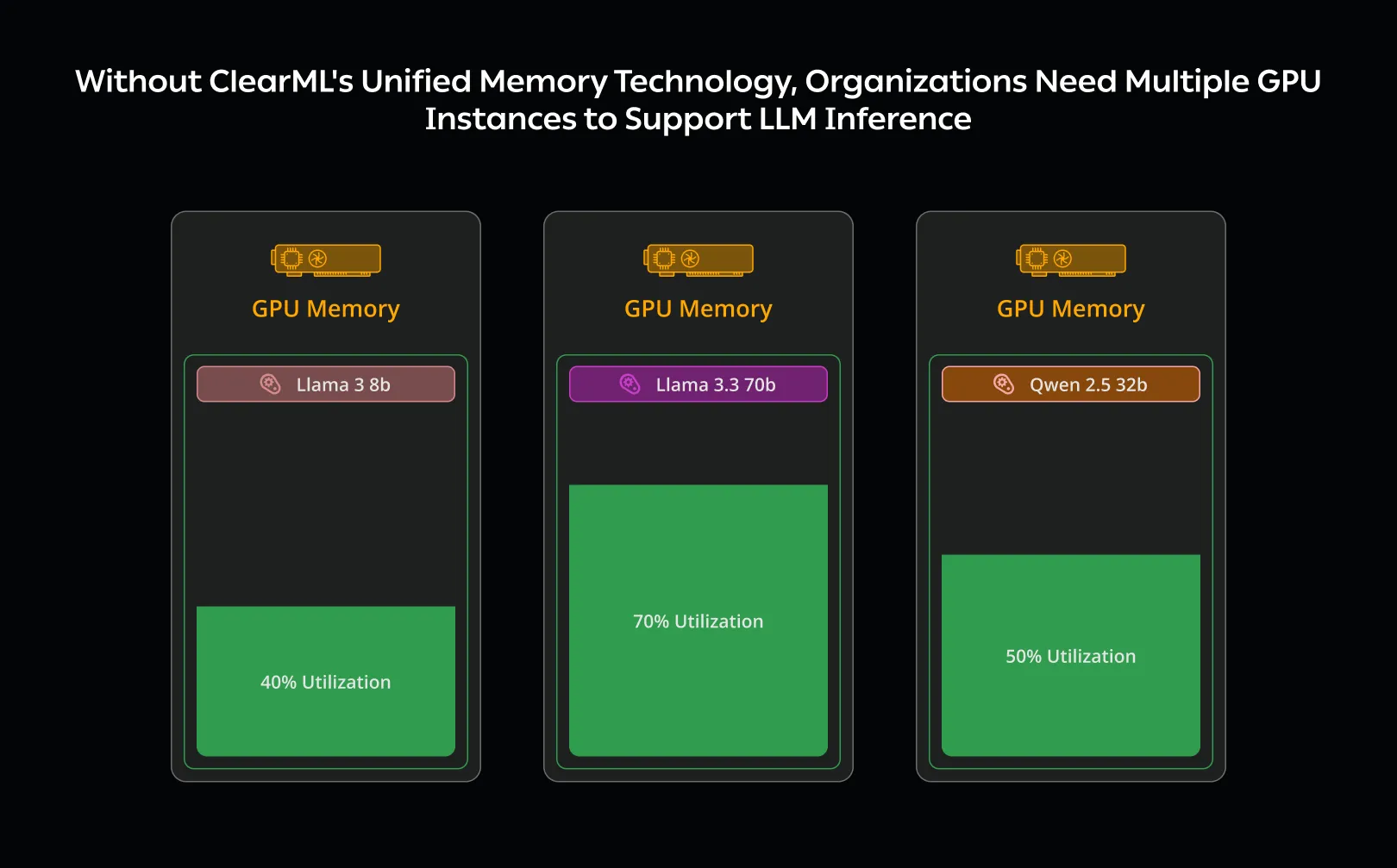
将模型部署到生产环境的 AI 构建者专注于确保为用户提供高性能模型。一旦模型上线,重点就转向优化 GPU 使用以实现高效部署。虽然 GPU 机器提供最佳性能,但运行成本高昂且经常未得到充分利用。当每个模型都在单独的 GPU 实例上运行时,这个问题变得更加突出;计算需求的这种近似线性增长使得公司难以扩展其运营,增加了部署复杂性和基础设施成本。
将多个模型打包到一台机器上有时会有帮助,但 GPU 受其 VRAM 大小的限制。如果多个模型超出可用内存,它们将无法同时提供服务,因此需要额外的始终在线资源。由于推理基础设施是一个主要的成本因素,优化 GPU 使用可以决定 AI 运营是否在财务上可行。
降低成本的一种方法是仅在需要时启动实例。不幸的是,这种情况会引入冷启动惩罚,因为启动新实例可能需要几分钟,这对于大多数用例来说是不切实际的,因为用户期望 LLM 在几秒钟内做出响应。即使对于对延迟不敏感的用例,这也需要建立和维护一个编排系统,该系统知道何时执行此操作,并且还具备在空闲时将其关闭的能力。
这就是 ClearML 统一内存技术发挥作用的地方。提供模型服务时,GPU 会被占用,因此最大化其使用至关重要;如果模型没有主动使用 GPU 资源,另一个模型就可以利用它们。它通过将非活动模型卸载到系统 RAM 中来无缝扩展 GPU 的 VRAM,系统 RAM 通常比 VRAM 大 10 到 100 倍。这使得工程师和运维人员可以在同一硬件上运行更多模型,在保持性能的同时降低成本并简化部署架构。

工作原理
ClearML 的统一内存技术利用 CPU 的 RAM 作为热缓存,将缓存的模型存储在系统内存中,同时将活动模型保留在 VRAM 中以便立即访问。如果多个模型能够容纳在可用 VRAM 中,它们可以一直保留在那里,直到需要空间为止。当访问缓存的模型时,ClearML 会将其从 CPU RAM 无缝加载到 VRAM 中(换出一个非活动模型),并使用 GPU 卓越的计算能力执行它。与依赖静态或半手动配置的 vLLM 和 llama.cpp 等引擎原生方法不同,ClearML 的统一内存技术是完全动态的,根据实时使用情况自动将模型换入或换出 VRAM,无需手动设置,也无需任何配置。
这种方法通过利用 CPU 的 RAM 既提供了高推理性能(以每秒生成的 token 数衡量,通过利用 GPU 实现),又提供了更大的内存容量。
利用 ClearML 的统一内存技术可以提高 GPU 利用率,因为单个 GPU 现在可以运行多个不同的模型;同时可以降低成本,因为可以在一台机器上部署更多模型,从而帮助企业扩展其 AI 推理工作负载。
内置,无需额外配置
ClearML 的统一内存技术已集成到 ClearML 的 生成式 AI 应用引擎中,使用户只需单击即可测试和部署 LLM,而无需管理基础设施、配置部署设置或处理模型端点的网络配置。
当使用 ClearML 内置的 vLLM 或 llama.cpp 引擎集成来提供模型服务时,它会自动将活动模型加载到 VRAM 中。当用户需要访问缓存的模型时,它会无缝地换入 VRAM 并在 GPU 上执行。这个过程无需手动配置,也无需更改代码,并且支持 Hugging Face 提供的现成模型以及存储在 ClearML 模型仓库中的自定义模型。
基准测试
我们使用 ClearML 的 vLLM 服务引擎对 ClearML 新的统一内存技术进行了测试,评估了其对模型加载速度和响应能力的影响。
设置
- 实例:AWS EC2 g6e.8xlarge,配备单个 NVIDIA L40s GPU
- 服务引擎:ClearML vLLM,启用统一内存和多模型支持
- 待测试的模型
- QWQ 32B(8 位量化)– 约 32.5 GB
- Llama 3 Instruct 8B(16 位浮点)– 约 15 GB
- Llama 3 Instruct 8B(8 位量化)– 约 8 GB
基准测试目标
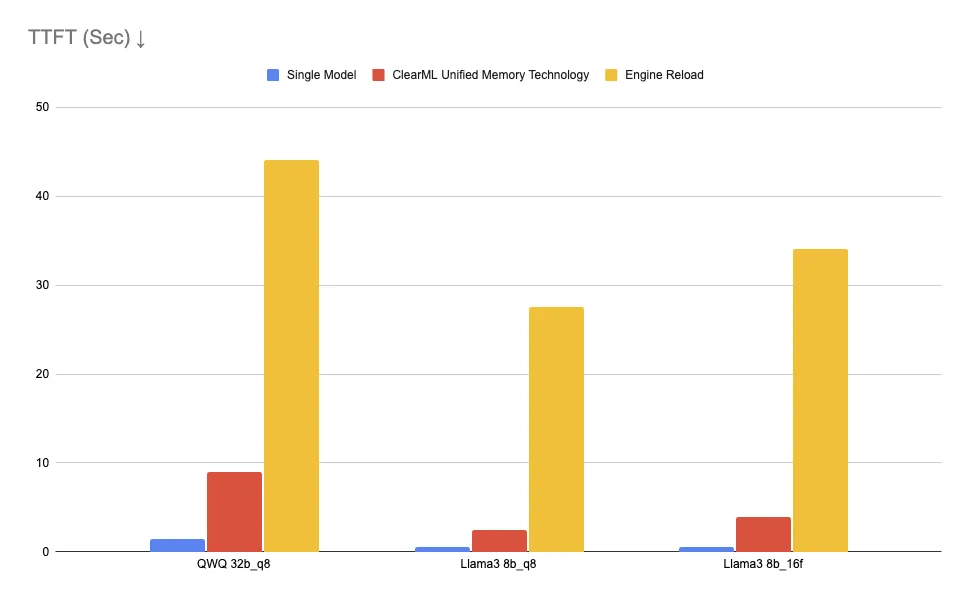
目标是评估不同场景下的首个 Token 生成时间 (TTFT)
- 每实例单个模型 – 单个“热”模型在内存中已激活时能多快响应。
- ClearML 统一内存技术 – 使用 ClearML 的统一内存技术在 CPU RAM 中缓存的模型之间切换需要多长时间。
- 引擎重新加载 – 从磁盘加载模型时引入的延迟,模拟动态启动或关闭服务引擎时的冷启动。
首个 Token 生成时间以秒为单位测量。
| 单个模型 | ClearML 统一内存技术 | 引擎重新加载 | 实例冷启动 | |
|---|---|---|---|---|
| QWQ 32b_q8 | 1.4 | 9.03 | 44 | 280 |
| Llama3 8b_q8 | 0.56 | 2.42 | 27.5 | 263 |
| Llama3 8b_16f | 0.51 | 3.97 | 34 | 270 |
结果
- 统一内存实现了比基于磁盘加载快 11 倍的 TTFT。
- 正如预期的那样,与模型驻留在 VRAM 中相比,CPU 交换会带来额外的延迟开销。
- 与启动新的 EC2 GPU 实例(可能需要几十秒到几分钟)相比,统一内存提供了超过 100 倍的响应能力提升。
这项技术对于许多不需要严格实时延迟的用例来说是有效的,并且能够大幅节省成本。
总结
ClearML 通过将 GPU 内存扩展到 CPU 的 RAM 上,帮助 AI 构建者最大化其基础设施、提高利用率并降低推理成本,同时保持可靠、高性能的 AI 部署。借助 ClearML 的统一内存技术,用户可以在每个 GPU 实例上运行更多模型,推理延迟最高可提升 100 倍。
有兴趣了解 ClearML 如何提升您的 AI 项目吗?立即预约演示,了解它如何加速您的开发并提高效率。
