为确保 AI/ML 开发生命周期的顺畅无阻,ClearML 最近宣布推出用于管理、调度和优化 GPU 计算资源的全新广泛功能。无论客户的设置是本地、云端还是混合部署,此功能都将带来益处。
在 ClearML 的 Orchestration 菜单下,新增的企业成本管理中心使客户能够更好地可视化和监督其集群中发生的一切。实时查看资源利用率的功能为团队提供了更好的方式来管理 GPU 分配、队列、作业调度和使用,以及项目配额。凭借更高的可见性,DevOps 团队可以更快、更好地做出决策,从而最大限度地提高其 GPU 资源利用率。
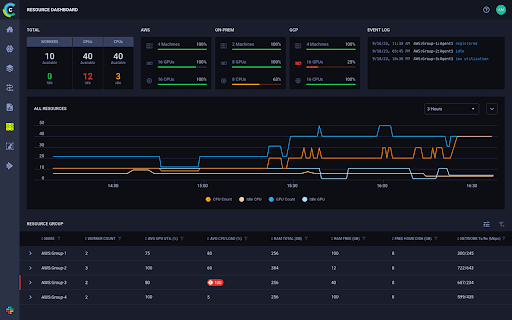
DevOps 团队还可以通过分配 GPU 分数、管理超额订阅、整合以及更密切地管理调度和优先级来确保 GPU 资源得到充分利用。通过策略管理器,ClearML 使团队能够完全控制作业优先级以及队列或配额内的作业顺序。通过创建自动化来更有效地管理作业,DevOps 团队可以节省大量时间和精力。
对于云或云混合部署设置,ClearML 的 Autoscaler(自动伸缩器)和 Spillover(溢出)功能使企业能够严格管理预算和成本。当计划的作业超出可用的现有本地 GPU 资源时,Spillover 可以安全地使用云计算资源。Autoscaler 功能(可与 Spillover 结合使用或单独使用)会自动在云端预置机器来运行作业,并在闲置时关闭它们,从而防止产生浪费成本。为了进一步控制成本和提供可用性选项,团队可以设置作业是在常规实例还是 Spot 实例上运行,并且不受区域限制。
通过编排和调度驱动 ClearML 的核心 AI/ML 平台,用户和管理员都可以更轻松地访问计算资源。ClearML 平台内置企业级安全性,并具有基于角色的访问控制。结合项目级用户凭据,ClearML 会自动为需要进行数据预处理、模型训练或模型服务的用户预置预配置的机器。对于原生集成的推理服务器,模型部署自动伸缩是自动的,支持 CPU 和 GPU 专用节点。如果您尚未拥有 AI/ML 平台,或正在重新评估您的工具包,请查阅 由 AI Infrastructure Alliance 整理的 AI/ML 解决方案概览。
ClearML 还为模型治理提供透明度和完整的溯源。每个集群的每个事件都会自动记录,便于审计。ClearML 完全开源且可扩展,可以安装在云、虚拟机、裸金属、Slurm 或 Kubernetes 上。该平台还与硬件和云无关,使企业可以自由选择自己的基础设施供应商,并针对本地/云混合组合进行优化。

如果您的公司需要更好地管理其 GPU 计算资源以节省时间、优化利用率并推动您的 AI/ML 计划,请立即申请 ClearML 演示。
